Capítulo 14 Modelos de Supervivencia
Vista Previa del Capítulo. Este capítulo introduce la regresión donde la variable dependiente es el tiempo hasta un evento, como el tiempo hasta la muerte, el inicio de una enfermedad o el incumplimiento de un préstamo. Los tiempos de eventos a menudo están limitados por procedimientos de muestreo, por lo que en este capítulo se resumen ideas de censura y truncamiento de datos. Los tiempos de eventos son no negativos y sus distribuciones se describen en términos de funciones de supervivencia y de riesgo. Se consideran dos tipos de regresión basada en el riesgo: un modelo completamente paramétrico de tiempo de falla acelerado y un modelo semiparamétrico de riesgos proporcionales.
14.1 Introducción
En los modelos de supervivencia, la variable dependiente es el tiempo hasta un evento de interés. El ejemplo clásico de un evento es el tiempo hasta la muerte (el complemento de la muerte es la supervivencia). Los modelos de supervivencia ahora se aplican ampliamente en muchas disciplinas científicas; otros ejemplos de eventos de interés incluyen el inicio de la enfermedad de Alzheimer (biomedicina), el tiempo hasta la bancarrota (economía) y el tiempo hasta el divorcio (sociología).
Ejemplo: Tiempo hasta la Bancarrota. Shumway (2001) examinó el tiempo hasta la bancarrota para 3,182 empresas listadas en el archivo industrial de Compustat y el archivo de rendimientos diarios de acciones de CRSP para la Bolsa de Nueva York durante el período 1962-1992. Se examinaron varias variables financieras explicativas, incluyendo capital de trabajo sobre activos totales, ganancias retenidas sobre activos totales, ganancias antes de intereses e impuestos sobre activos totales, capital de mercado sobre pasivos totales, ventas sobre activos totales, ingresos netos sobre activos totales, pasivos totales sobre activos totales y activos corrientes sobre pasivos corrientes. El conjunto de datos incluyó 300 bancarrotas de 39,745 años-firma.
Véase también Kim et al. (1995) para un estudio similar sobre insolvencias en seguros.
Una característica distintiva del modelado de supervivencia es que es común que la variable dependiente solo se observe de manera limitada. Algunos eventos de interés, como la bancarrota o el divorcio, nunca ocurren para sujetos específicos (y por lo tanto pueden pensarse como que toman un tiempo infinito). Para otros sujetos, incluso cuando el tiempo del evento es finito, puede ocurrir después del período de estudio, de modo que los datos están censurados (por la derecha). Es decir, la información completa sobre los tiempos de eventos puede no estar disponible debido al diseño del estudio. Además, las empresas pueden fusionarse o ser adquiridas por otras empresas, y las personas pueden mudarse de un área geográfica, dejando el estudio. Por lo tanto, los datos pueden estar limitados por eventos que son ajenos a la pregunta de investigación en consideración, representados como censura aleatoria. La censura es una característica regular de los datos de supervivencia; los valores grandes de una variable dependiente requieren más tiempo para desarrollarse, por lo que pueden ser más difíciles de observar que los valores pequeños, considerando otras condiciones iguales. También pueden ocurrir otros tipos de limitaciones; los sujetos cuya observación depende de la experiencia del evento de interés se denominan truncados. Para ilustrar, en una investigación de mortalidad en la vejez, solo aquellos que sobreviven hasta los 85 años son reclutados para ser parte del estudio. La Sección 14.2 describe la censura y el truncamiento con más detalle.
Otra característica distintiva del modelado de supervivencia es que la variable dependiente tiene valores positivos. Por lo tanto, las aproximaciones de curva normal utilizadas en la regresión lineal son menos útiles en el análisis de supervivencia; este capítulo introduce modelos de regresión alternativos. Además, es habitual interpretar los modelos de supervivencia utilizando la función de riesgo, definida como \[ \mathrm{h}(t)= \frac{\textit{función de densidad de probabilidad}} {\textit{función de supervivencia}} =\frac{\mathrm{f}(t)}{\mathrm{S}(t)}, \] la probabilidad “instantánea” de un evento, condicionada a la supervivencia hasta el tiempo \(t\). La función de riesgo recibe muchos otros nombres: se conoce como la fuerza de mortalidad en la ciencia actuarial, la tasa de falla en ingeniería y la función de intensidad en procesos estocásticos.
En economía, las funciones de riesgo se utilizan para describir la dependencia de duración, la relación entre la probabilidad instantánea de un evento (la densidad) y el tiempo transcurrido en un estado dado. La dependencia de duración negativa está asociada con tasas de riesgo decrecientes. Por ejemplo, cuanto mayor sea el tiempo hasta que un reclamante solicite un pago por una lesión asegurada, menor será la probabilidad de hacer una solicitud. La dependencia de duración positiva está asociada con tasas de riesgo crecientes. Por ejemplo, la mortalidad humana en la vejez generalmente muestra una tasa de riesgo creciente. Cuanto mayor sea la edad de una persona, mayor será la probabilidad de muerte en el corto plazo.
Una cantidad relacionada de interés es la función acumulada de riesgo, \(H(t)= \int_0^t h(s)ds\). Esta cantidad también puede expresarse como el logaritmo negativo de la función de supervivencia, y de manera inversa, \(\Pr(y>t)=\mathrm{S}(t) = \exp (-H(t))\).
Los dos modelos de regresión más utilizados en el análisis de supervivencia están basados en funciones de riesgo. La Sección 14.3 introduce el modelo de tiempo de falla acelerado, donde se asume un modelo lineal para el logaritmo del tiempo hasta la falla, pero con una distribución de error que no necesita ser aproximadamente normal. La Sección 14.4 introduce el modelo de riesgos proporcionales debido a Cox (1972), donde se asume que la función de riesgo puede escribirse como el producto de un riesgo “base” y una función de una combinación lineal de variables explicativas.
Con los datos de supervivencia, observamos una muestra transversal de sujetos donde el tiempo es la variable dependiente de interés. Al igual que en el Capítulo 10 sobre datos longitudinales y de panel, también existen aplicaciones en las que estamos interesados en observaciones repetidas para cada sujeto. Por ejemplo, si sufres una lesión cubierta por un seguro, los pagos que surgen de esta reclamación pueden ocurrir repetidamente a lo largo del tiempo, dependiendo del tiempo de recuperación. La Sección 14.5 introduce la noción de tiempos de eventos repetidos, llamados eventos recurrentes.
14.2 Censura y Truncamiento
14.2.1 Definiciones y Ejemplos
Dos tipos de limitaciones que se encuentran en los datos de supervivencia son la censura y el truncamiento. La censura y el truncamiento también son características comunes en otras aplicaciones actuariales, incluidas las del Capítulo 16 sobre modelos de dos partes y el Capítulo 17 sobre modelos de colas largas. Por lo tanto, esta sección describe estos conceptos en detalle.
Para la censura, la forma más común es la censura por la derecha, en la cual observamos el menor valor entre la “verdadera” variable dependiente y una variable de tiempo de censura. Por ejemplo, supongamos que deseamos estudiar el tiempo hasta que un nuevo empleado deje la empresa y que tenemos cinco años de datos para realizar nuestro análisis. Entonces, observamos el menor valor entre cinco años y el tiempo que el empleado estuvo con la empresa. También observamos si el empleado dejó la empresa dentro de esos cinco años.
Usando notación, sea \(y\) el tiempo hasta el evento, como la cantidad de tiempo que el empleado trabajó en la empresa. Sea \(C_U\) el tiempo de censura, como \(C_U=5\). Entonces, observamos la variable \(y_U^{\ast}= \min(y, C_U)\). También observamos si ocurrió o no la censura. Sea \(\delta_U= \mathrm{I}(y \geq C_U)\) una variable binaria que es 1 si ocurre censura, \(y \geq C_U\), y 0 en caso contrario. Por ejemplo, en la Figura 14.1, los valores de \(y\) que son mayores que el límite superior de censura \(C_U\) no se observan; por lo tanto, esto se llama comúnmente censura por la derecha.
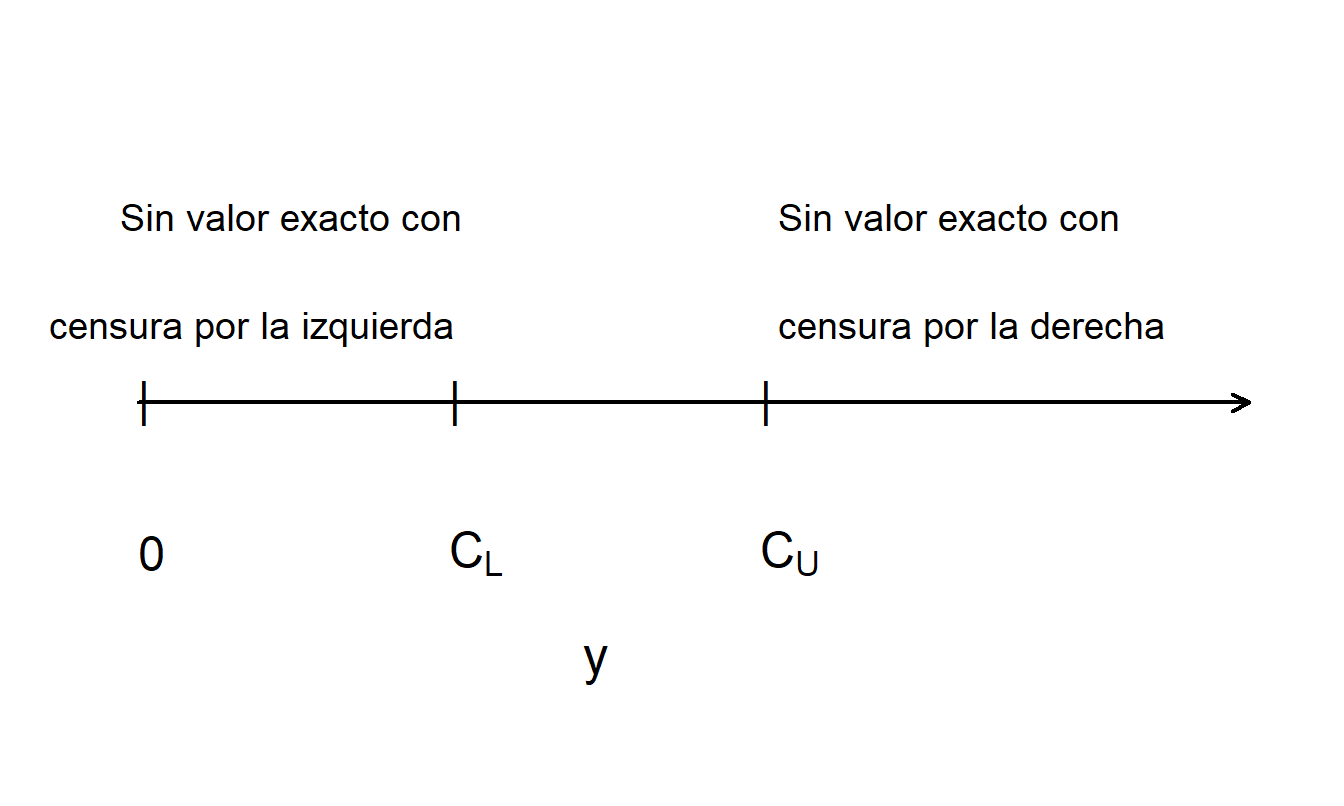
Figura 14.1: Figura que Ilustra Censura por la Izquierda y por la Derecha
Otras formas comunes de censura son la censura por la izquierda y la censura por intervalo. Con la censura por la izquierda, observamos \(y_L^{\ast}= \max(y, C_L)\) y \(\delta_L= \mathrm{I}(y \leq C_L)\) donde \(C_L\) es el tiempo de censura. Por ejemplo, si estás realizando un estudio y entrevistas a una persona sobre un evento pasado, el sujeto puede recordar que el evento ocurrió antes de \(C_L\) pero no la fecha exacta.
Con la censura por intervalo, hay un intervalo de tiempo, como \((C_L, C_U)\), en el que se sabe que \(y\) ocurre pero no se observa el valor exacto. Por ejemplo, podrías estar mirando dos años sucesivos de registros anuales de empleados. Las personas empleadas en el primer año pero no en el segundo dejaron el trabajo en algún momento durante el año. Con una fecha exacta de salida, podrías calcular el tiempo que estuvieron en la empresa. Sin la fecha de salida, solo sabes que salieron en algún momento durante un intervalo de un año.
Los tiempos de censura como \(C_L\) y \(C_U\) pueden o no ser estocásticos. Si los tiempos de censura representan variables conocidas por el analista, como el período de observación, se dice que son tiempos de censura fija. Aquí, el adjetivo “fijo” significa que los tiempos son conocidos de antemano. Los tiempos de censura pueden variar según el individuo pero seguir siendo fijos. Sin embargo, la censura también puede ser el resultado de fenómenos imprevistos, como la fusión de una empresa o el cambio de domicilio de un sujeto fuera de un área geográfica. En este caso, la censura \(C\) se representa mediante una variable aleatoria y se dice que es censura aleatoria. Si la censura es fija o si el tiempo de censura aleatorio es independiente del evento de interés, entonces se dice que la censura es no informativa. Si los tiempos de censura son independientes del evento de interés, entonces esencialmente podemos tratar la censura como fija. Cuando la censura y el tiempo hasta el evento son dependientes (conocido como censura informativa), entonces se requieren modelos especiales. Por ejemplo, si el evento de interés es el tiempo hasta la quiebra de una empresa y el mecanismo de censura implica la presentación de estados financieros adecuados, entonces existe una relación potencial. Las empresas financieramente débiles tienen más probabilidades de quebrar y menos probabilidades de realizar el esfuerzo contable para presentar estados financieros adecuados.
Las observaciones censuradas están disponibles para estudio, aunque de forma limitada. En contraste, las respuestas truncadas son un tipo de datos faltantes. Para ilustrarlo, con datos truncados por la izquierda, si \(y\) es menor que un umbral (digamos, \(C_L\)), entonces no se observa. Para datos truncados por la derecha, si \(y\) excede un umbral (digamos, \(C_U\)), entonces no se observa. Para comparar observaciones truncadas y censuradas, considera el siguiente ejemplo.
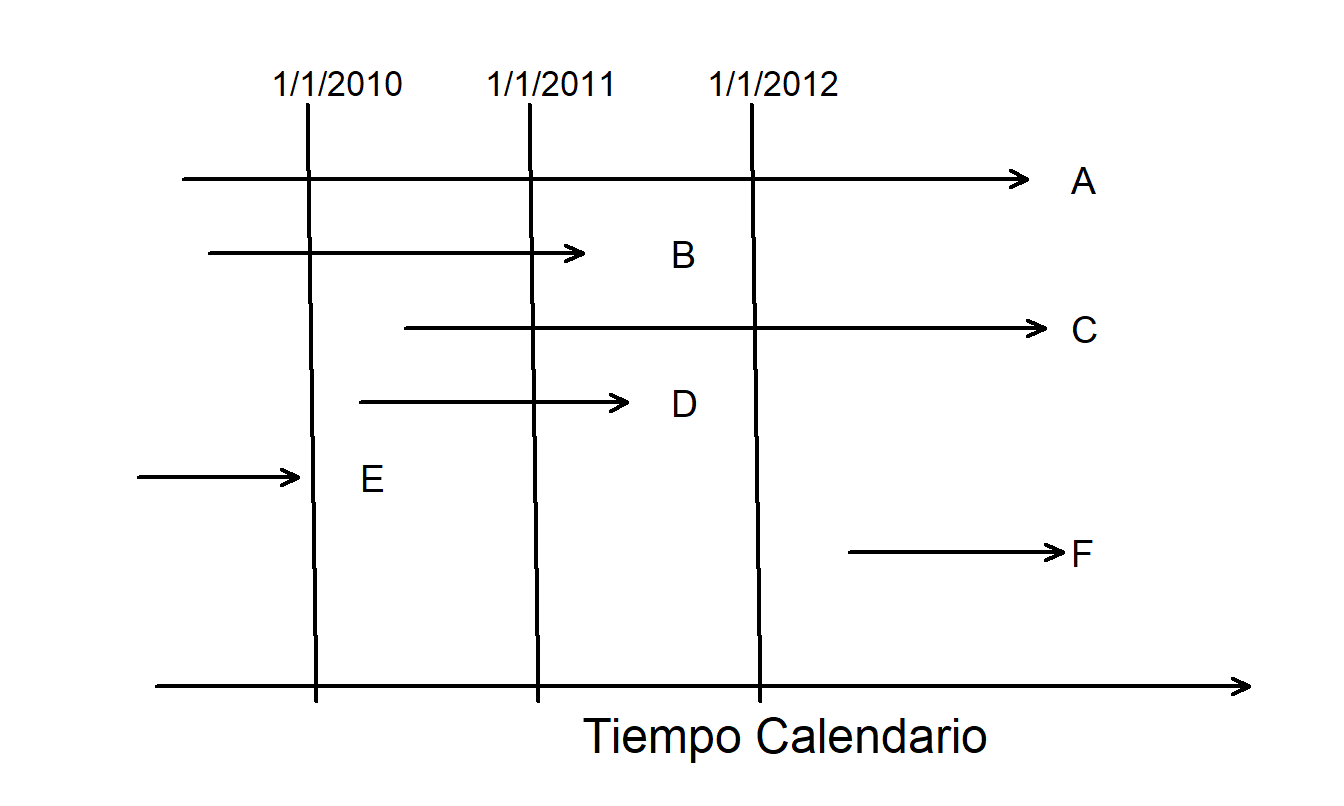
Figura 14.2: Línea de tiempo para varios sujetos en un estudio de mortalidad.
Ejemplo: Estudio de Mortalidad. Supongamos que estás realizando un estudio de dos años sobre la mortalidad de sujetos de alto riesgo, comenzando el 1 de enero de 2010 y finalizando el 1 de enero de 2012. La Figura 14.2 representa gráficamente los seis tipos de sujetos reclutados. Para cada sujeto, el inicio de la flecha representa el momento en que el sujeto fue reclutado y el final de la flecha representa el tiempo del evento. Por lo tanto, la flecha representa el tiempo de exposición.
- Tipo A - censura por la derecha. Este sujeto está vivo al inicio y al final del estudio. Como no se conoce el tiempo de muerte al final del estudio, está censurado por la derecha. La mayoría de los sujetos son de tipo A.
- Tipo B. Se dispone de información completa para un sujeto de tipo B. El sujeto está vivo al inicio del estudio y la muerte ocurre dentro del período de observación.
- Tipo C - censura por la derecha y truncamiento por la izquierda. Un sujeto de tipo C está censurado por la derecha, ya que la muerte ocurre después del período de observación. Sin embargo, el sujeto ingresó después del inicio del estudio y se dice que tiene un tiempo de entrada retrasado. Como el sujeto no habría sido observado si la muerte hubiera ocurrido antes de la entrada, está truncado por la izquierda.
- Tipo D - truncamiento por la izquierda. Un sujeto de tipo D también tiene una entrada retrasada. Como la muerte ocurre dentro del período de observación, este sujeto no está censurado por la derecha.
- Tipo E - truncamiento por la izquierda. Un sujeto de tipo E no está incluido en el estudio porque la muerte ocurre antes del período de observación.
- Tipo F - truncamiento por la derecha. De manera similar, un sujeto de tipo F no está incluido porque el tiempo de entrada ocurre después del período de observación.
14.2.2 Inferencia por Verosimilitud
Muchas técnicas de inferencia para el modelado de supervivencia implican la estimación por verosimilitud, por lo que es útil entender las implicaciones de la censura y el truncamiento al especificar funciones de verosimilitud. Para simplificar, asumimos tiempos de censura fijos y un tiempo hasta el evento continuo \(y\).
Para comenzar, considere el caso de datos censurados por la derecha, donde observamos \(y_U^{\ast}= \min(y, C_U)\) y \(\delta_U= \mathrm{I}(y \geq C_U)\). Si ocurre censura de modo que \(\delta_U=1\), entonces \(y \geq C_U\) y la verosimilitud es \(\Pr(y \geq C_U) = \mathrm{S}(C_U)\). Si no ocurre censura de modo que \(\delta_U=0\), entonces \(y < C_U\) y la verosimilitud es \(\mathrm{f}(y)\). Resumiendo, tenemos: \[\begin{eqnarray*} \text{Verosimilitud} &=& \left\{ \begin{array}{cl} \mathrm{f}(y) & \textrm{si}~\delta=0 \\ \mathrm{S}(C_U) & \textrm{si}~\delta=1 \end{array} \right. \\ &=& \left( \mathrm{f}(y)\right)^{1-\delta} \left( \mathrm{S}(C_U)\right)^{\delta} . \end{eqnarray*}\]
La expresión de la derecha nos permite presentar la verosimilitud de manera más compacta. Ahora, para una muestra independiente de tamaño \(n\), \(\{ (y_{U1}, \delta_1), \ldots,(y_{Un}, \delta_n) \}\), la verosimilitud es: \[ \prod_{i=1}^n \left( \mathrm{f}(y_i)\right)^{1-\delta_i} \left( \mathrm{S}(C_{Ui})\right)^{\delta_i} = \prod_{\delta_i=0} \mathrm{f}(y_i) \prod_{\delta_i=1} \mathrm{S}(C_{Ui}), \] con posibles tiempos de censura \(\{ C_{U1}, \ldots,C_{Un} \}\). Aquí, la notación “\(\prod_{\delta_i=0}\)” significa tomar el producto sobre observaciones no censuradas, y de manera similar para “\(\prod_{\delta_i=1}\)”.
Los datos truncados se manejan en la inferencia por verosimilitud mediante probabilidades condicionales. Específicamente, ajustamos la contribución a la verosimilitud dividiendo por la probabilidad de que la variable haya sido observada. Resumiendo, tenemos las siguientes contribuciones a la verosimilitud para seis tipos de resultados:
\[ \small{ \begin{array}{lc} \hline \text{Resultado } & \text{Contribución a la Verosimilitud} \\\hline \text{Valor exacto} & f(y) \\ \text{Censura por la derecha} & S(C_U) \\ \text{Censura por la izquierda} & 1-S(C_L) \\ \text{Truncamiento por la derecha} & f(y)/(1-S(C_U)) \\ \text{Truncamiento por la izquierda} & f(y)/S(C_L) \\ \text{Censura por intervalo} & S(C_L)-S(C_U) \\ \hline \end{array} } \]
Para tiempos de evento conocidos y datos censurados, la verosimilitud es: \[ \prod_{E} \mathrm{f}(y_i) \prod_{R} \mathrm{S}(C_{Ui}) \prod_{L} (1-\mathrm{S}(C_{Li})) \prod_{I} (\mathrm{S}(C_{Li})-\mathrm{S}(C_{Ui})), \] donde “\(\prod_{E}\)” es el producto sobre observaciones con valores exactos (Exact), y de manera similar para Right (derecha), Left (izquierda) y Interval (intervalo).
Para datos censurados por la derecha y truncados por la izquierda, la verosimilitud es: \[ \prod_{E} \frac{\mathrm{f}(y_i)}{\mathrm{S}(C_{Li})} \prod_{R} \frac{\mathrm{S}(C_{Ui})}{\mathrm{S}(C_{Li})} , \] y de manera similar para otras combinaciones. Para obtener más información, considere lo siguiente.
Caso Especial: Distribución Exponencial. Considere datos censurados por la derecha y truncados por la izquierda, con variables dependientes \(y_i\) distribuidas exponencialmente con media \(\mu\). Con estas especificaciones, recuerde que \(\mathrm{f}(y) = \mu^{-1} \exp(-y/\mu)\) y \(\mathrm{S}(y) = \exp(-y/\mu)\).
Para este caso especial, la verosimilitud logarítmica es: \[ \begin{array}{ll} \ln \text{Verosimilitud} &= \sum_{E} \left( \ln \mathrm{f}(y_i) - \ln \mathrm{S}(C_{Li}) \right) +\sum_{R}\left( \ln \mathrm{S}(C_{Ui})- \ln \mathrm{S}(C_{Li}) \right) \\ &= \sum_{E} (-\ln \mu -(y_i-C_{Li})/\mu ) -\sum_{R} (C_{Ui}-C_{Li})/\mu . \end{array} \] Para simplificar la notación, definimos \(\delta_i = \mathrm{I}(y_i \geq C_{Ui})\) como una variable binaria que indica censura por la derecha. Sea \(y_i^{\ast \ast} = \min(y_i, C_{Ui}) - C_{Li}\) la cantidad en que la variable observada excede el límite inferior de truncamiento. Con esto, la verosimilitud logarítmica es: \[\begin{equation} \ln \text{Verosimilitud} = - \sum_{i=1}^n ((1-\delta_i) \ln \mu + \frac{y_i^{\ast \ast}}{\mu} ). \tag{14.1} \end{equation}\] Derivando con respecto al parámetro \(\mu\) e igualando a cero se obtiene el estimador de máxima verosimilitud: \[\begin{eqnarray*} \widehat{\mu} &=& \frac{1}{n_u} \sum_{i=1}^n y_i^{\ast \ast}, \end{eqnarray*}\] donde \(n_u = \sum_i (1-\delta_i)\) es el número de observaciones no censuradas.
14.2.3 Estimador Producto-Límite
Puede ser útil calibrar los métodos de verosimilitud con métodos no paramétricos que no dependen de una forma paramétrica de la distribución. El estimador producto-límite debido a Kaplan y Meier (1958) es un estimador bien conocido de la distribución en presencia de censura.
Para introducir este estimador, consideremos el caso de datos censurados por la derecha. Sean \(t_1 < \cdots < t_c\) los puntos de tiempo distintos en los que ocurre un evento de interés y sea \(d_j\) el número de eventos en el punto de tiempo \(t_j\). Además, definimos \(R_j\) como el “conjunto de riesgo” correspondiente, es decir, el número de observaciones que están activas en un instante justo antes de \(t_j\). Usando notación, el conjunto de riesgo es \(R_j = \sum_{i=1}^n I\left( y_i \geq t_j \right)\). Con esta notación, el estimador producto-límite de la función de supervivencia es: \[\begin{equation} \widehat{S}(t) = \left\{ \begin{array}{ll} 1 & t<t_1 \\ \prod_{t_j \leq t} \left(1 - \frac{d_j}{R_j} \right) & t \geq t_1 \end{array} \right. . \tag{14.2} \end{equation}\]
Para interpretar el estimador producto-límite, evaluémoslo en los tiempos de eventos. En el primer tiempo de evento \(t_1\), el estimador es \(\widehat{S}(t_1)= 1- d_1/R_1=(R_1 - d_1)/R_1\), la proporción de no eventos en el conjunto de riesgo \(R_1\). En el segundo tiempo de evento \(t_2\), la probabilidad de supervivencia condicional a la supervivencia hasta el tiempo \(t_1\) es \(\widehat{S}(t_2)/ \widehat{S}(t_1)\) \(= 1 - d_2/R_2\) \(=(R_2 - d_2)/R_2\), la proporción de no eventos en el conjunto de riesgo \(R_2\). De manera similar, en el \(j\)-ésimo tiempo de evento:
\[ \frac{\widehat{S}(t_j)}{\widehat{S}(t_{j-1})}= 1 - \frac{d_j}{R_j}=\frac{R_j - d_j}{R_j} . \] A partir de estas probabilidades condicionales, se puede construir el estimador de supervivencia como:
\[ \widehat{S}(t_j) = \frac{\widehat{S}(t_j)}{\widehat{S}(t_{j-1})} \times \cdots \times \frac{\widehat{S}(t_2)}{\widehat{S}(t_{1})} \times \widehat{S}(t_{1}), \] lo que resulta en la ecuación (14.2). En este sentido, el estimador es un “producto,” hasta el “límite” del tiempo. Para tiempos entre los tiempos de evento, la estimación de supervivencia se considera constante.
Para ver cómo usar el estimador producto-límite, consideremos un pequeño conjunto de datos de \(n=23\) observaciones, donde 18 son tiempos de evento y 5 han sido censurados por la derecha. Este ejemplo es de Miller (1997), donde los eventos corresponden a la supervivencia de pacientes con leucemia mieloide aguda. Después de recibir quimioterapia para lograr la remisión completa, se asignaron aleatoriamente a uno de dos grupos, aquellos que recibieron quimioterapia de mantenimiento y aquellos que no (el grupo control). El evento fue el tiempo en semanas hasta la recaída desde el estado de remisión completa. Para el grupo de mantenimiento, los tiempos son: 9, 13, 13+, 18, 23, 28+, 31, 34, 45+, 48, 161+. Para el grupo de control, los tiempos son: 5, 5, 8, 8, 12, 16+, 23, 27, 30, 33, 43, 45. Aquí, el signo más (+) indica censura por la derecha de una observación.
Las Figuras 14.3 y 14.4 muestran las estimaciones de la función de supervivencia producto-límite para estos datos. Note la naturaleza escalonada de la función, donde las caídas (desde la izquierda, o saltos desde la derecha) corresponden a tiempos de eventos. Cuando no hay censura, el estimador producto-límite se reduce al estimador empírico usual de la función de supervivencia.
En las figuras, las observaciones censuradas se representan con un símbolo de trazado de más (+). Cuando la última observación ha sido censurada, como en la Figura 14.3, existen diferentes métodos para definir la curva de supervivencia para tiempos que exceden esta observación. Los analistas que realizan estimaciones en estos tiempos deben ser conscientes de la opción que utiliza su paquete estadístico. Estas opciones se describen en libros estándar de análisis de supervivencia, como Klein y Moschberger (1997).
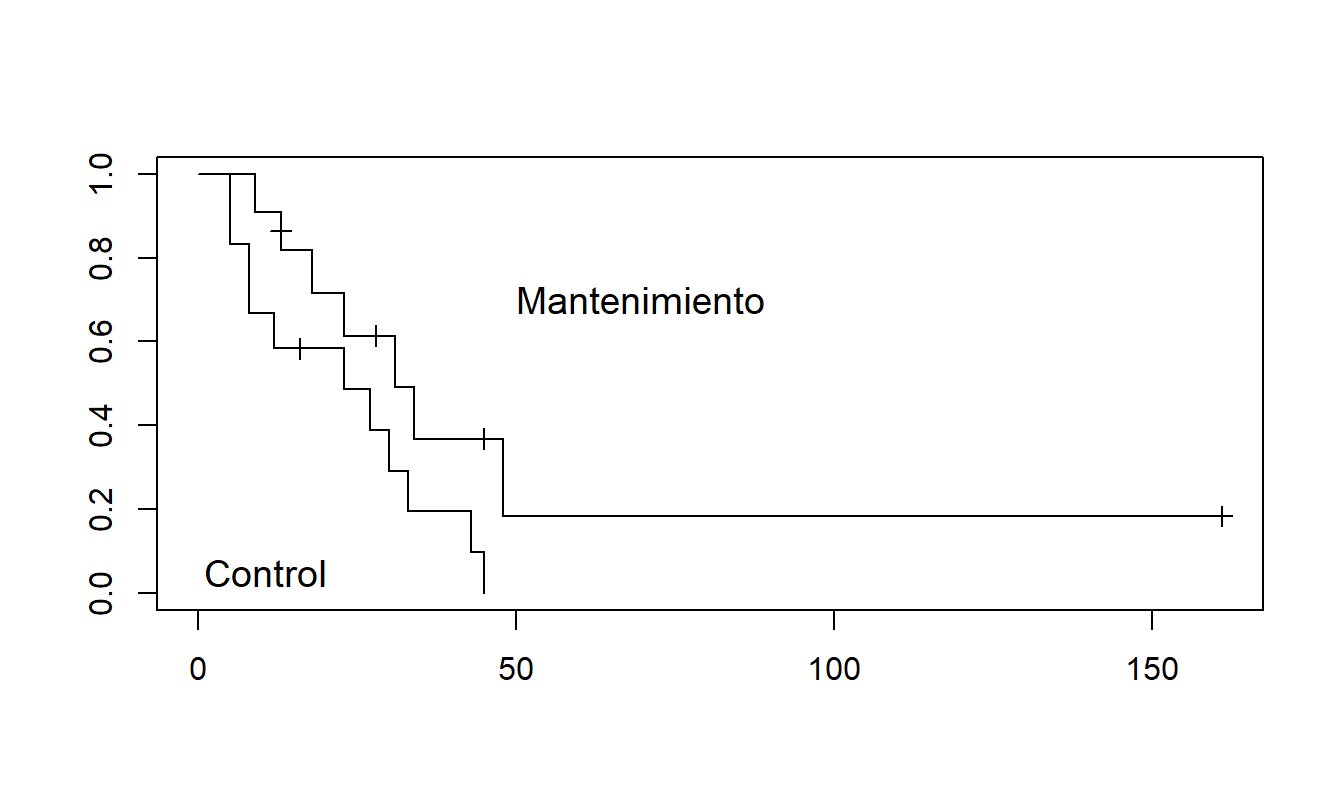
Figura 14.3: Estimación Producto-Límite de las Funciones de Supervivencia para Dos Grupos. Este gráfico muestra que aquellos con tratamiento de quimioterapia de mantenimiento tienen mayores probabilidades de supervivencia estimadas que aquellos en el grupo control.
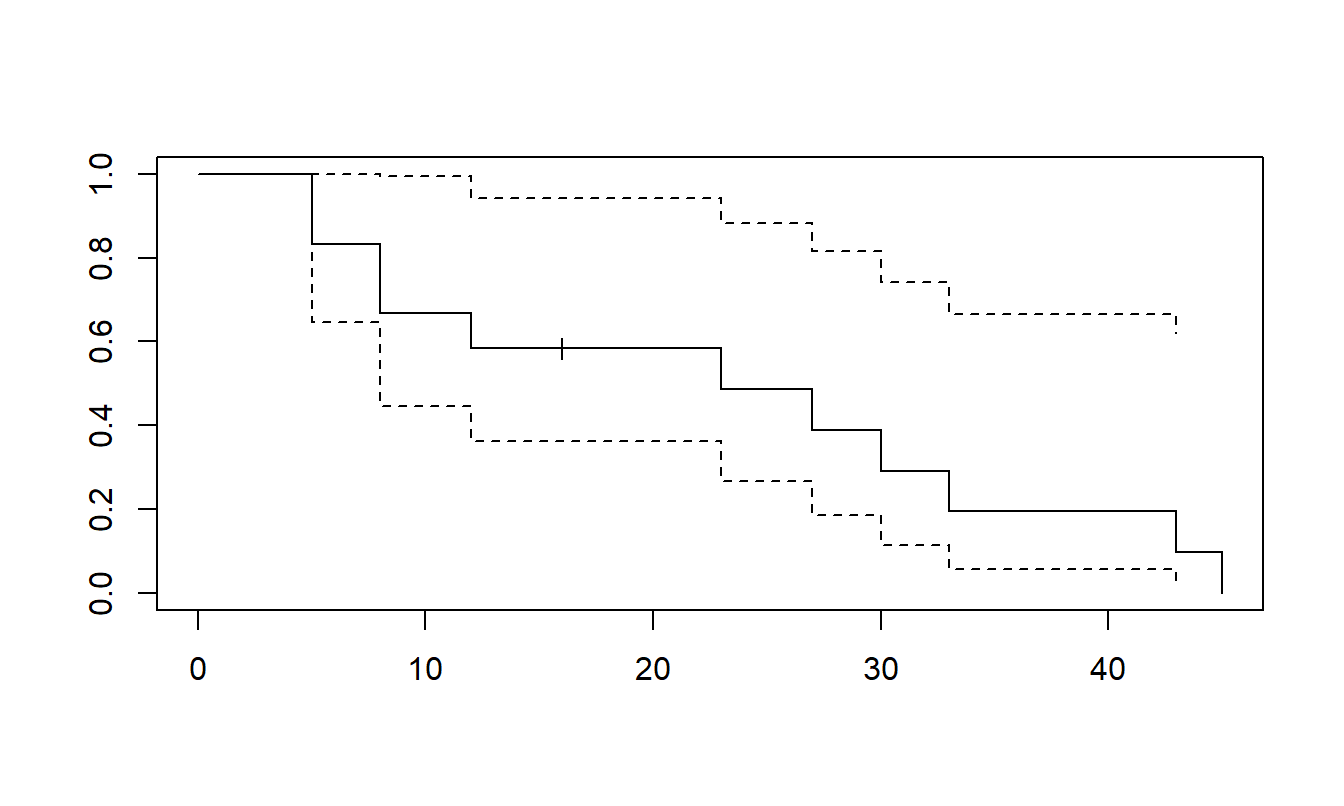
Figura 14.4: Estimación Producto-Límite de la Función de Supervivencia para el Grupo Control. Los límites superior e inferior provienen de la fórmula de Greenwood para la estimación de la varianza.
Figure 14.4 también muestra una estimación del error estándar. Estos se calculan utilizando la fórmula de Greenwood (1926) para una estimación de la varianza, dada por: \[ \widehat{\mathrm{Var}(\widehat{S}(t))} = (\widehat{S}(t))^2 \sum_{t_j \leq t} \frac{d_j}{R_j(R_j-d_j)} . \]
Código R para generar las Figuras 14.3 y 14.4
14.3 Modelo de Tiempo de Fallo Acelerado
Un modelo de tiempo de fallo acelerado (\(AFT\)) puede expresarse usando una ecuación de regresión lineal \(\ln y_i = \mathbf{x}_i^{\prime} \boldsymbol \beta + \varepsilon_i\), donde \(y_i\) es el tiempo de evento. A diferencia del modelo de regresión lineal usual, el modelo AFT hace una suposición paramétrica sobre el término de perturbación, como una distribución normal, de valor extremo o logística. Como hemos visto, la distribución normal es la base para el modelo de regresión lineal usual. Así, muchos analistas comienzan tomando logaritmos de los datos de eventos y utilizando rutinas de regresión lineal habituales para explorar sus datos.
Distribuciones de Localización y Escala
Para entender el nombre “tiempo de fallo acelerado,” también conocido como riesgos acelerados, es útil repasar la idea estadística de familias de localización y escala. Una distribución de localización y escala paramétrica es aquella donde la función de densidad tiene la forma: \[ \mathrm{f}(t) =\frac{1}{\sigma }\mathrm{f}_0 \left( \frac{t-\mu }{\sigma }\right) , \] donde \(\mu\) es el parámetro de localización y \(\sigma >0\) es el parámetro de escala. El caso \(\mu =0\) y \(\sigma =1\) corresponde a la forma estándar de la distribución. Dentro de una distribución de localización y escala, los cambios aditivos, como pasar de grados Kelvin a grados Centígrados, \(^{\circ }K=\) \(^{\circ }C+273.15\), y los múltiplos escalares, como pasar de dólares a miles de dólares, permanecen en la misma familia de distribución. Como veremos en el Capítulo 17, un parámetro de localización es un lugar natural para introducir covariables de regresión.
Una variable aleatoria \(y\) se dice que tiene una distribución logarítmica de localización y escala si \(\ln y\) tiene una distribución de localización y escala. Supongamos que una variable aleatoria \(y_0\) tiene una distribución de localización y escala estándar con función de supervivencia \(\mathrm{S}_0\left( z\right)\). Entonces, la función de supervivencia de \(y\) definida por \(\ln y = \mu + \sigma y_0\) puede expresarse como: \[ \mathrm{S}\left( t\right) =\Pr \left( y>t\right) =\Pr \left( y_0>\frac{\ln t-\mu }{\sigma }\right) =\mathrm{S}_0\left( \frac{\ln t-\mu }{\sigma } \right) =\mathrm{S}_0^{\ast }\left( \left( \frac{t}{e^{\mu }}\right) ^{1/\sigma }\right) , \] donde \(\mathrm{S}_0^{\ast }(t) =\mathrm{S}_0( \ln t)\) es la función de supervivencia de la forma estándar de \(\ln y\). En el contexto del modelado de supervivencia donde \(t\) representa tiempo, el efecto de reescalar dividiendo por \(e^{\mu }\) puede interpretarse como “acelerar el tiempo” (cuando \(e^{\mu }<1\)). Esta es la motivación para el nombre “modelos de tiempo de fallo acelerado.” La Tabla 14.1 proporciona algunos casos especiales de distribuciones de localización y escala ampliamente utilizadas y sus contrapartes logarítmicas.
| Distribución de Supervivencia Estándar | Distribución de Localización y Escala | Distribución Logarítmica de Localización y Escala |
|---|---|---|
| \(\mathrm{S}_0(t) = \exp(- e^t)\) | Distribución de valor extremo | Weibull |
| \(\mathrm{S}_0(t) =1 - \Phi(t)\) | Normal | Lognormal |
| \(\mathrm{S}_0(t) = (1 + e^t)^{-1}\) | Logística | Log-logística |
Inferencia para Modelos AFT
Para tener una idea de las complejidades en la estimación de un modelo \(AFT\), volvemos a la distribución exponencial. Este es un caso especial de regresión Weibull con el parámetro de escala \(\sigma =1\).
Caso Especial: Distribución Exponencial - Continuación. Para introducir covariables de regresión, dejamos que \(\mu_i = \exp (\mathbf{x}_i^{\prime} \boldsymbol \beta)\). Usando el mismo razonamiento que con la ecuación (14.1), la verosimilitud logarítmica es: \[ \begin{array}{ll} \ln \text{Verosimilitud} &= - \sum_{i=1}^n ((1-\delta_i) \ln \mu_i +\frac{y_i^{\ast \ast}}{\mu_i} )\\ &= - \sum_{i=1}^n ((1-\delta_i) \mathbf{x}_i^{\prime} \boldsymbol \beta+ y_i^{\ast \ast}\exp (-\mathbf{x}_i^{\prime} \boldsymbol \beta)) , \end{array} \] donde \(\delta_i = I(y_i \geq C_{Ui})\) y \(y_i^{\ast \ast} =\min(y_i, C_{Ui}) - C_{Li}\). Al derivar con respecto a \(\boldsymbol \beta\), obtenemos la función de puntuación: \[ \begin{array}{ll} \frac{\partial \ln \text{Verosimilitud}}{\partial \boldsymbol \beta} &= - \sum_{i=1}^n ((1-\delta_i) \mathbf{x}_i - \mathbf{x}_i y_i^{\ast \ast}\exp (-\mathbf{x}_i^{\prime} \boldsymbol \beta)) \\ &= \sum_{i=1}^n \mathbf{x}_i \frac{y_i^{\ast \ast}-\mu_i (1-\delta_i)} {\mu_i } . \end{array} \] Esto tiene la forma de una ecuación de estimación generalizada, introducida en el Capítulo 13. Aunque las soluciones en forma cerrada rara vez existen, puede resolverse fácilmente con paquetes estadísticos modernos.
Como ilustra este caso especial, la estimación de modelos de regresión \(AFT\) puede abordarse fácilmente a través de máxima verosimilitud. Además, las propiedades de las estimaciones de máxima verosimilitud son bien entendidas, por lo que contamos con herramientas generales de inferencia, como estimación y prueba de hipótesis. Los paquetes estadísticos estándar proporcionan resultados que apoyan esta inferencia.
14.4 Modelo de Riesgos Proporcionales
La suposición de riesgos proporcionales se define en la Sección 14.4.1 y las técnicas de inferencia se discuten en la Sección 14.4.2.
14.4.1 Riesgos Proporcionales
En el modelo de riesgos proporcionales (\(PH\)) debido a Cox (1972), se asume que la función de riesgo puede escribirse como el producto de un riesgo “base” y una función de una combinación lineal de variables explicativas. Para ilustrar, usamos: \[\begin{equation} h_i(t) = h_0(t) \exp( \mathbf{x}_i^{\prime} \boldsymbol \beta ). \tag{14.3} \end{equation}\] donde \(h_0(t)\) es el riesgo base. Este se conoce como un modelo de “riesgos proporcionales” porque, si se toma la razón de funciones de riesgo para dos conjuntos de covariables, digamos \(\mathbf{x}_1\) y \(\mathbf{x}_2\), se obtiene: \[ \frac{h_1(t|\mathbf{x}_1)}{h_2(t|\mathbf{x}_2)} = \frac {h_0(t) \exp( \mathbf{x}_1^{\prime} \boldsymbol \beta )} {h_0(t) \exp( \mathbf{x}_2^{\prime} \boldsymbol \beta )} = \exp( (\mathbf{x}_1-\mathbf{x}_2)^{\prime}\boldsymbol \beta ) . \] Nótese que la razón no depende del tiempo \(t\).
Como hemos visto en muchas aplicaciones de regresión, los usuarios están interesados en los efectos de las variables y no siempre en otros aspectos del modelo. La razón por la que el modelo \(PH\) en la ecuación (14.3) ha resultado tan popular es que especifica los efectos de las variables explicativas como una función simple de la combinación lineal mientras permite un componente base flexible, \(h_0\). Aunque este componente base es común a todos los sujetos, no necesita especificarse paramétricamente como en los modelos \(AFT\). Además, no es necesario usar la función “exp” para las variables explicativas; sin embargo, esta es la especificación común ya que asegura que la función de riesgo seguirá siendo no negativa.
Los riesgos proporcionales pueden motivarse como una extensión de la regresión exponencial. Considere una variable aleatoria \(y^{\ast}\) que tiene una distribución exponencial con media \(\mu = \exp (\mathbf{x}^{\prime} \boldsymbol \beta)\). Supongamos que observamos \(y = \mathrm{g}(y^{\ast})\), donde \(\mathrm{g}(\cdot)\) es desconocida excepto que es monótonamente creciente. Muchas distribuciones de supervivencia son transformaciones de la distribución exponencial. Por ejemplo, si \(y = \mathrm{g}(y^{\ast})=(y^{\ast})^{\sigma}\), entonces es fácil verificar que \(y\) tiene una distribución Weibull como se da en la Tabla 14.1. La distribución Weibull es el único modelo \(AFT\) que tiene riesgos proporcionales (ver Lawless, 2003, ejercicio 6.1).
Cálculos simples muestran que la función de riesgo de \(y\) puede expresarse como: \[ \mathrm{h}_y(t) = \mathrm{g}^{\prime}(t) / \mu = \mathrm{g}^{\prime}(t) \exp (- \mathbf{x}^{\prime} \boldsymbol \beta ), \] ver, por ejemplo, Zhou (2001). Esto tiene una estructura de riesgos proporcionales, como en la ecuación (14.3), donde \(\mathrm{g}^{\prime}(t)\) sirve como el riesgo base. En el modelo \(PH\), se asume que el riesgo base es desconocido. En contraste, para la Weibull y otros modelos de regresión \(AFT\), se asume que la función de riesgo base es conocida hasta uno o dos parámetros que pueden estimarse a partir de los datos.
14.4.2 Inferencia
Debido a la especificación flexible del componente base, las técnicas usuales de estimación de máxima verosimilitud no están disponibles para estimar el modelo \(PH\). Para esbozar el procedimiento de estimación, dejamos que \((y_1, \delta_1), \ldots, (y_n, \delta_n)\) sean independientes y asumimos que \(y_i\) sigue la ecuación (14.3) con regresores \(\mathbf{x}_i\). Es decir, ahora dejamos de usar la notación con asterisco (\(\ast\)) y dejamos que \(y_i\) denote valores observados (exactos o censurados) y usamos \(\delta_i\) como la variable binaria que indica censura (derecha). Además, dejamos que \(H_0\) sea la función de riesgo acumulada asociada con la función base \(h_0\). Recordando la relación general \(\mathrm{S}(t) = \exp (-H(t))\), con la ecuación (14.3) tenemos \(\mathrm{S}(t) = \exp \left(-H_0(t)\exp( \mathbf{x}_i^{\prime} \boldsymbol \beta )\right).\)
Desde la perspectiva usual de verosimilitud, de la Sección 14.2.2 la verosimilitud es: \[\begin{eqnarray*} L(\boldsymbol \beta , h_0)&= & \prod_{i=1}^n \mathrm{f}(y_i)^{1-\delta_i} \mathrm{S}(y_i)^{\delta_i} = \prod_{i=1}^n h(y_i)^{1-\delta_i} \exp(-H(y_i)) \\&= & \prod_{i=1}^n \left( h_0(t) \exp( \mathbf{x}_i^{\prime} \boldsymbol \beta ) \right)^{1-\delta_i} \exp\left(-H_0(y_i)\exp( \mathbf{x}_i^{\prime} \boldsymbol \beta ) \right) . \end{eqnarray*}\]
Ahora, las estimaciones de parámetros que maximizan \(L(\boldsymbol \beta , h_0)\) no siguen las propiedades usuales de la estimación de máxima verosimilitud porque el riesgo base \(h_0\) no se especifica paramétricamente. Una forma de abordar este problema es mediante Breslow (1974), quien mostró que un estimador de máxima verosimilitud no paramétrico de \(h_0\) podría usarse en \(L(\boldsymbol \beta , h_0)\). Esto resulta en lo que Cox llamó una verosimilitud parcial: \[\begin{equation} L_P(\boldsymbol \beta) = \prod_{i=1}^n \left( \frac{\exp( \mathbf{x}_i^{\prime} \boldsymbol \beta )} {\sum_{j \in R(y_i)} \exp( \mathbf{x}_j^{\prime} \boldsymbol \beta )} \right)^{1-\delta_i}, \tag{14.4} \end{equation}\] donde \(R(t)\) es el conjunto de riesgo en el tiempo \(t\). Específicamente, este es el conjunto de todos \(\{y_1, \ldots, y_n \}\) tales que \(y_i \geq t\), es decir, el conjunto de todos los sujetos que aún están bajo estudio en el tiempo \(t\).
La ecuación (14.4) es solo una verosimilitud “parcial” en el sentido de que no utiliza toda la información en \((y_1, \delta_1), \ldots, (y_n, \delta_n)\). Por ejemplo, de la ecuación (14.4), vemos que la inferencia para los coeficientes de regresión depende únicamente de los rangos de las variables dependientes \(\{y_1, \ldots, y_n \}\), no de sus valores reales.
No obstante, la ecuación (14.4) sugiere (y es cierto) que la teoría de distribución muestral en grandes muestras tiene propiedades similares a la teoría paramétrica (totalmente) deseable. Desde la perspectiva del usuario, esta verosimilitud parcial puede tratarse como una verosimilitud usual. Es decir, los parámetros de regresión que maximizan la ecuación (14.4) son consistentes y tienen una distribución normal en grandes muestras con las estimaciones de varianza habituales (ver Sección 11.9 para una revisión). Esto es ligeramente sorprendente porque el modelo de riesgos proporcionales es semi-paramétrico; en la ecuación (14.3), la función de riesgo tiene un componente completamente paramétrico, \(\exp( \mathbf{x}_i^{\prime} \boldsymbol \beta )\), pero también contiene un riesgo base no paramétrico, \(h_0(t)\). En general, los modelos no paramétricos son más flexibles que sus contrapartes paramétricas para el ajuste de modelos, pero resultan en propiedades muestrales menos deseables (específicamente, tasas de convergencia más lentas a una distribución asintótica).
Ejemplo: Puntajes de Crédito. Stepanova y Thomas (2002) usaron modelos de riesgos proporcionales para crear puntajes de crédito que los bancos podrían usar para evaluar la calidad de préstamos personales. Sus puntajes dependían de los propósitos del préstamo y las características de los solicitantes. Los clientes potenciales solicitan préstamos a los bancos por muchos propósitos, incluidos la financiación de la compra de una casa, automóvil, barco o instrumento musical, para mejoras en el hogar y reparaciones de automóviles, o para financiar una boda y lunas de miel; Stepanova y Thomas enumeraron 22 propósitos de préstamo. En la solicitud de préstamo, las personas proporcionaron su edad, monto solicitado, años con el empleador actual y otras características personales; Stepanova y Thomas enumeraron 22 características de la solicitud utilizadas en su análisis.
Sus datos provienen de una importante institución financiera del Reino Unido. Consistieron en información de solicitud de 50,000 préstamos personales, con el estado de reembolso para cada uno de los primeros 36 meses del préstamo. Así, cada préstamo estaba (fijamente) censurado a la derecha por el menor entre la duración del período de estudio, 36 meses, y el plazo de reembolso del préstamo, que variaba entre 6 y 60 meses.
Para crear los puntajes, los autores examinaron dos variables dependientes que tienen consecuencias financieras negativas para el prestamista, el tiempo hasta el incumplimiento del préstamo y el tiempo hasta el reembolso anticipado. Para este estudio, la definición de incumplimiento es 3 o más meses de morosidad. (En principio, se podrían analizar ambos tiempos simultáneamente en un marco de “riesgos competitivos”). Cuando Stepanova y Thomas usaron un modelo de riesgos proporcionales con el tiempo hasta el incumplimiento como variable dependiente, el tiempo hasta el reembolso anticipado era una variable de censura aleatoria a la derecha. A la inversa, cuando el tiempo hasta el reembolso anticipado era la variable dependiente, el tiempo hasta el incumplimiento era una variable de censura aleatoria a la derecha.
Stepanova y Thomas utilizaron estimaciones del modelo de las funciones de supervivencia a los 12 meses y a los 24 meses como sus puntajes de crédito para ambas variables dependientes. Compararon estos puntajes con los de un modelo de regresión logística donde, por ejemplo, la variable dependiente era el incumplimiento del préstamo dentro de los 12 meses. Ningún enfoque dominó al otro; encontraron situaciones en las que cada enfoque de modelado proporcionaba mejores predictores del riesgo crediticio de un individuo.
Una característica importante del modelo de riesgos proporcionales es que puede extenderse fácilmente para manejar covariables que varían en el tiempo de la forma \(\mathbf{x}_i(t)\). En este caso, se puede escribir la verosimilitud parcial como \[ L_P(\boldsymbol \beta) = \prod_{i=1}^n \left( \frac{\exp( \mathbf{x}_i^{\prime}(y_i) \boldsymbol \beta )} {\sum_{j \in R(y_i)} \exp( \mathbf{x}_j^{\prime}(y_j) \boldsymbol \beta ) }\right)^{1-\delta_i} . \] Usar esta verosimilitud es complejo, aunque la maximización puede realizarse fácilmente con software estadístico moderno. La inferencia es compleja porque puede ser difícil separar las covariables observadas que varían en el tiempo \(\mathbf{x}_i(t)\) del riesgo base no observado que varía en el tiempo \(\mathrm{h}_0(t)\). Consulte las referencias en la Sección 14.6 para más detalles.
14.5 Eventos Recurrentes
Los eventos recurrentes son tiempos de eventos que pueden ocurrir repetidamente a lo largo del tiempo para cada sujeto. Para el \(i\)-ésimo sujeto, usamos la notación \(y_{i1} < y_{i2} < \cdots < y_{im_i}\) para denotar los \(m_i\) tiempos de eventos. Entre otras aplicaciones, los eventos recurrentes pueden usarse para modelar:
- Reclamos de garantía,
- Pagos de reclamos que han sido reportados a una compañía de seguros y
- Reclamos de eventos que han ocurrido pero aún no han sido reportados a una compañía de seguros.
Ejemplo: Reclamos de Garantía de Automóviles. Cook y Lawless (2007) consideran una muestra de 15,775 automóviles que fueron vendidos y bajo garantía durante 365 días. Las garantías son garantías de confiabilidad del producto emitidas por el fabricante. Los datos de garantía corresponden a un sistema del vehículo (como frenos o tren motriz) y cubren un año con un límite de 12,000 millas. La Tabla 14.2 resume la distribución de los 2,620 reclamos de esta muestra.
| Número de Reclamos | 0 | 1 | 2 | 3 | 4 | 5+ | Total |
| Número de Autos | 13,987 | 1,243 | 379 | 103 | 34 | 29 | 15,775 |
| Fuente: Cook y Lawless (2007, Tabla 1.3). |
La Tabla 14.2 muestra que hay 1,788 (=15,775-13,987) automóviles con al menos un (\(m_i > 0\)) reclamo. La Figura 14.5 representa la estructura de los tiempos de eventos.
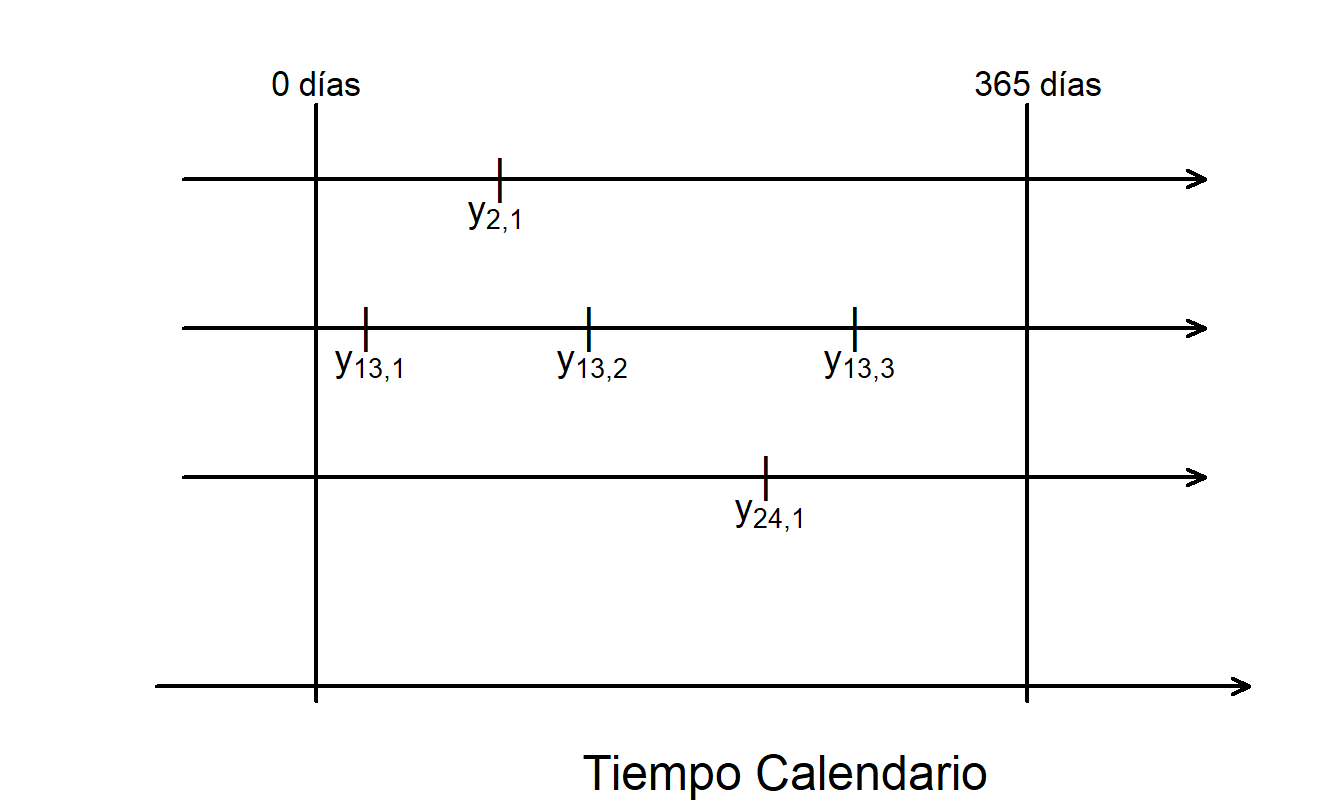
Figura 14.5: Figura que Ilustra Reclamos de Garantía (Potencialmente) Repetidos.
Presentamos modelos de eventos recurrentes usando procesos de conteo, específicamente empleando procesos de Poisson. Aunque existen enfoques alternativos, para los análisis estadísticos el concepto de procesos de conteo parece el más fructífero (Cook y Lawless, 2007). Además, existe una fuerte conexión histórica de los procesos de Poisson con la teoría actuarial de ruina (Klugman, Panjer y Willmot, 2008, Capítulo 11), por lo que muchos actuarios están familiarizados con los procesos de Poisson.
Sea \(N_i(t)\) el número de eventos que han ocurrido hasta el tiempo \(t\). Usando álgebra, podemos escribir esto como \(N_i(t) = \sum_{j \geq 1} \mathrm{I}(y_{ij} \leq t).\) Debido a que \(N_i(t)\) varía con la experiencia de un sujeto, es una variable aleatoria para cada \(t\) fijo. Además, al observar toda la evolución de los reclamos, \(\{N_i(t), t \geq 0 \}\), se conoce como un proceso estocástico. Un proceso de conteo es un tipo especial de proceso estocástico que describe conteos que aumentan de manera monótona con el tiempo. Un proceso de Poisson es un tipo especial de proceso de conteo. Si \(\{N_i(t), t \geq 0 \}\) es un proceso de Poisson, entonces \(N_i(t)\) tiene una distribución de Poisson con media, digamos, \(\mathrm{h}_i(t)\) para cada \(t\) fijo. En la literatura de procesos de conteo, es común referirse a \(\mathrm{h}_i(t)\) como la función de intensidad.
La inferencia estadística para eventos recurrentes puede llevarse a cabo utilizando procesos de Poisson y técnicas paramétricas de máxima verosimilitud. Como se discute en Cook y Lawless (2007), la verosimilitud para el \(i\)-ésimo sujeto se basa en la densidad de probabilidad condicional de los resultados observados “\(m_i\) eventos, en los tiempos \(y_{i1} < \cdots < y_{im_i}\)”. Esto produce la verosimilitud \[\begin{equation} \text{Verosimilitud}_i = \prod_{j=1}^{m_i} \{\mathrm{h}_i(y_{ij}) \} \exp \left(- \int_0^{\infty} y_i(s) \mathrm{h}_i(s) ds \right) \tag{14.5} \end{equation}\] donde \(y_i(s)\) es una variable binaria que indica si el \(i\)-ésimo sujeto es observado hasta el tiempo \(s\).
Para parametrizar la función de intensidad \(\mathrm{h}_i(t)\), asumimos que tenemos disponibles variables explicativas. Por ejemplo, al examinar reclamos de garantía de automóviles, podríamos disponer de información como la marca y el modelo del vehículo, o características del conductor como género y edad al momento de la compra. También podríamos tener características que sean funciones del tiempo del reclamo, como el número de millas recorridas. Por lo tanto, usamos la notación \(\mathbf{x}_i(t)\) para denotar la posible dependencia de las variables explicativas en el tiempo del evento.
Similar a la ecuación (14.3), es habitual escribir la función de intensidad como \[ h_i(t) = h_0(t) \exp( \mathbf{x}_i^{\prime}(t) \boldsymbol \beta ). \] donde \(h_0(t)\) es la intensidad base. Para una especificación totalmente paramétrica, se especificaría la intensidad base en términos de varios parámetros. Luego, se usaría la función de intensidad \(h_i(t)\) en la ecuación de verosimilitud (14.5), que serviría como base para la inferencia por verosimilitud. Como se discute en Cook y Lawless (2007), también son posibles enfoques semiparamétricos donde la base no está completamente parametrizada (como en el modelo \(PH\)).
14.6 Lecturas Adicionales y Referencias
Como se describe en Collett (1994), el estimador de límite de producto ha sido utilizado desde principios del siglo XX. Greenwood (1926) estableció la fórmula para una varianza aproximada. El trabajo de Kaplan y Meier (1958) suele asociarse con el estimador de límite de producto; demostraron que es un estimador de máxima verosimilitud no paramétrico de la función de supervivencia.
Existen varias fuentes excelentes para el estudio adicional del análisis de supervivencia, particularmente en las ciencias biomédicas; Collett (1994) es una de estas fuentes. El texto de Klein y Moeschberger (1997) fue utilizado durante varios años como lectura obligatoria para el temario de la Sociedad de Actuarios de Norteamérica. Lawless (2003) proporciona una introducción desde una perspectiva de ingeniería. Lancaster (1990) discute temas econométricos. Hougaard (2000) ofrece un tratamiento avanzado.
Recomendamos Cook y Lawless (2007) para un tratamiento extenso de eventos recurrentes.
Referencias del Capítulo
- Breslow, Norman (1974). Covariance analysis of censored survival data. Biometrics 30, 89-99.
- Collett, D. (1994). Modelling Survival Data in Medical Research. Chapman & Hall, London.
- Cook, Richard J. and Jerald F. Lawless (2007). The Statistical Analysis of Recurrent Events. Springer-Verlag, New York.
- Cox, David R. (1972). Regression models and life-tables. Journal of the Royal Statistical Society, Series B 34, 187-202.
- Gourieroux, Christian and Joann Jasiak (2007). The Econometrics of Individual Risk. Princeton University Press, Princeton, New Jersey.
- Greenwood, M. (1926). The errors of sampling of the survivorship tables. Reports on Public Health and Statistical Subjects, number 33, Appendix, HMSO, London.
- Kaplan, E. L. and Meier, P. (1958). Nonparametric estimation from incomplete observations. Journal of the American Statistical Association 53, 457-481.
- Kim, Yong-Duck, Dan R. Anderson, Terry L. Amburgey and James C. Hickman (1995). The use of event history analysis to examine insurance insolvencies. Journal of Risk and Insurance 62, 94-110.
- Klein, John P. and Melvin L. Moeschberger (1997). Survival Analysis: Techniques for Censored and Truncated Data. Springer-Verlag, New York.
- Klugman, Stuart A, Harry H. Panjer and Gordon E. Willmot (2008). Loss Models: From Data to Decisions. John Wiley & Sons, Hoboken, New Jersey.
- Lancaster, Tony (1990). The Econometric Analysis of Transition Data. Cambridge University Press, New York.
- Lawless, Jerald F. (2003). Statistical Models and Methods for Lifetime Data, Second Edition. John Wiley & Sons, New York.
- Hougaard, Philip (2000). Analysis of Multivariate Survival Data. Springer-Verlag, New York.
- Miller, Rupert G. (1997). Survival Analysis. John Wiley & Sons, New York.
- Shumway, Tyler (2001). Forecasting bankruptcy more accurately: A simple hazard model. Journal of Business 74, 101-124.
- Stepanova, Maria and Lyn Thomas (2002). Survival analysis methods for personal loan data. Operations Research 50(2), 277-290.
- Zhou, Mai (2001). Understanding the Cox regression models with time-changing covariates. American Statistician 55(2), 153-155.