Capítulo 6 Interpretación de Resultados de Regresión
Vista previa del capítulo. Un analista de regresión recopila datos, selecciona un modelo y luego informa sobre los hallazgos del estudio, en ese orden. Este capítulo considera estos tres temas en orden inverso, enfatizando cómo cada etapa del estudio está influenciada por los pasos precedentes. Una aplicación, determinar las características de una empresa que influyen en su efectividad para gestionar el riesgo, ilustra el proceso de modelado de regresión de principio a fin.
Estudiar un problema utilizando un proceso de modelado de regresión implica un compromiso sustancial de tiempo y energía. Primero, uno debe adoptar el concepto de pensamiento estadístico, es decir, estar dispuesto a utilizar los datos activamente como parte de un proceso de toma de decisiones. En segundo lugar, uno debe apreciar la utilidad de un modelo que se usa para aproximar una situación real. Después de hacer este compromiso sustancial, hay una tendencia natural a “sobrevender” los resultados de métodos estadísticos como el análisis de regresión. Al sobrevender cualquier conjunto de ideas, los consumidores eventualmente se sienten decepcionados cuando los resultados no cumplen con sus expectativas. Este capítulo comienza en la Sección 6.1 resumiendo lo que podemos esperar aprender razonablemente del modelado de regresión.
Los modelos están diseñados para ser mucho más simples que las relaciones entre entidades que existen en el mundo real. Un modelo es simplemente una aproximación de la realidad. Como dijo George Box (1979), “Todos los modelos son incorrectos, pero algunos son útiles”. Desarrollar el modelo, el tema del Capítulo 5, es parte del arte de la estadística. Aunque los principios de la selección de variables son ampliamente aceptados, la aplicación de estos principios puede variar considerablemente entre los analistas. El producto resultante tiene ciertos valores estéticos y de ninguna manera está predeterminado. La estadística se puede considerar como el arte de razonar con datos. La Sección 6.2 subrayará la importancia de la selección de variables.
La formulación del modelo y la recopilación de datos forman la primera etapa del proceso de modelado. Los estudiantes de estadística suelen sorprenderse por la dificultad de relacionar ideas sobre relaciones con los datos disponibles. Estas dificultades incluyen la falta de datos fácilmente disponibles y la necesidad de usar ciertos datos como sustitutos de la información ideal que no está disponible numéricamente. La Sección 6.3 describirá varios tipos de dificultades que pueden surgir al recopilar datos. La Sección 6.4 describirá algunos modelos para aliviar estas dificultades.
6.1 Lo que nos dice el proceso de modelado
La inferencia del modelo es la etapa final del proceso de modelado. Al estudiar el comportamiento de los modelos, esperamos aprender algo sobre el mundo real. Los modelos sirven para imponer un orden en la realidad y proporcionar una base para entender la realidad a través de la naturaleza del orden impuesto. Además, los modelos estadísticos se basan en el razonamiento con los datos disponibles de una muestra. Por lo tanto, los modelos sirven como una guía importante para predecir el comportamiento de observaciones fuera de la muestra disponible.
6.1.1 Interpretación de efectos individuales
Al interpretar los resultados de una regresión múltiple, el objetivo principal es a menudo transmitir la importancia de las variables individuales, o efectos, sobre un resultado de interés. La interpretación depende de si los efectos son o no significativamente sustantivos, estadísticamente significativos y causales.
Significado Sustantivo. Los lectores de un estudio de regresión primero quieren entender la dirección y magnitud de los efectos individuales. ¿Las mujeres tienen más o menos reclamaciones que los hombres en un estudio de reclamaciones de seguros? Si es menos, ¿cuánto menos? Puedes responder a estas preguntas a través de una tabla de coeficientes de regresión. Además, para dar una idea de la fiabilidad de las estimaciones, también puede ser útil incluir el error estándar o un intervalo de confianza, como se introdujo en la Sección 3.4.2.
Recuerda que los coeficientes de regresión son estimaciones de las derivadas parciales de la función de regresión
\[ \mathrm{E~}y = \beta_0 + \beta_1 x_1 + \ldots + \beta_k x_k. \]
Al interpretar los coeficientes para variables explicativas continuas, es útil hacerlo en términos de cambios significativos de cada \(x\). Por ejemplo, si la población es una variable explicativa, podemos hablar del cambio esperado en \(y\) por cada cambio de 1,000 o un millón en la población. Además, al interpretar los coeficientes de regresión, comenta sobre su significado “sustantivo”. Por ejemplo, supongamos que encontramos una diferencia en las reclamaciones entre hombres y mujeres, pero la diferencia estimada es solo del 1% de las reclamaciones esperadas. Esta diferencia puede ser estadísticamente significativa pero no económicamente relevante. La significación sustantiva se refiere a la importancia en el campo de estudio; en ciencia actuarial, esto es típicamente de relevancia financiera o económica, pero también podría ser no monetaria, como los efectos sobre la esperanza de vida futura.
Significado Estadístico. ¿Son los efectos debidos al azar? La maquinaria de pruebas de hipótesis introducida en la Sección 3.4.1 proporciona un mecanismo formal para responder a esta pregunta. Las pruebas de hipótesis son útiles porque proporcionan un estándar formal y acordado para decidir si una variable hace una contribución importante a una respuesta esperada. Al interpretar los resultados, los investigadores suelen citar un \(t\)-ratio o un \(p\)-valor para demostrar significación estadística.
En algunas situaciones, es de interés comentar sobre las variables que no son estadísticamente significativas. Los efectos que no son estadísticamente significativos tienen errores estándar que son grandes en relación con los coeficientes de regresión. En la Sección 5.5.2, expresamos este error estándar como
\[\begin{equation} se(b_{j}) = s \frac{\sqrt{VIF_{j}}}{s_{x_{j}} \sqrt{n-1}}. \tag{6.1} \end{equation}\]
Una posible explicación para la falta de significancia estadística es una gran variación en el término de perturbación. Al expresar el error estándar en esta forma, vemos que cuanto mayor es la variación natural, medida por \(s\), más difícil es rechazar la hipótesis nula de ningún efecto (\(H_0\)), manteniendo todo lo demás constante.
Una segunda posible explicación para la falta de significancia estadística es la alta colinealidad, medida por \(VIF_j\). Una variable puede estar confundida con otras variables de manera que, a partir de los datos que se están analizando, sea imposible distinguir los efectos de una variable de otra.
Una tercera posible explicación es el tamaño de la muestra. Supongamos que se utiliza un mecanismo similar a extracciones de una población estable para observar las variables explicativas. Entonces, la desviación estándar de \(x_j\), \(s_{x_j}\), debería ser estable a medida que aumenta el número de extracciones. De manera similar, también deberían serlo \(R_j^2\) y \(s^2\). Entonces, el error estándar \(se(b_j)\) debería disminuir a medida que el tamaño de la muestra, \(n\), aumenta. Por el contrario, un tamaño de muestra más pequeño significa un error estándar mayor, manteniendo todo lo demás constante. Esto significa que es posible que no podamos detectar la importancia de las variables en muestras de tamaño pequeño o moderado.
Por lo tanto, en un mundo ideal, si no se detecta significancia estadística donde se había hipotetizado (y completamente esperado), se podría: (i) obtener una medida más precisa de \(y\), reduciendo así su variabilidad natural, (ii) rediseñar el esquema de recolección de muestras para que las variables explicativas relevantes sean menos redundantes y (iii) recopilar más datos. Normalmente, estas opciones no están disponibles con datos observacionales, pero puede ser útil señalar los próximos pasos en un programa de investigación.
Los analistas ocasionalmente observan relaciones estadísticamente significativas que no se anticiparon; esto podría deberse a un tamaño de muestra grande. Anteriormente, mencionamos que una muestra pequeña puede no proporcionar suficiente información para detectar relaciones significativas. La otra cara de este argumento es que, para muestras grandes, tenemos la oportunidad de detectar la importancia de variables que podrían pasar desapercibidas en muestras de tamaño pequeño o incluso moderado. Desafortunadamente, esto también significa que las variables con coeficientes de parámetro pequeños, que contribuyen poco a entender la variación en la respuesta, pueden ser juzgadas como significativas utilizando nuestros procedimientos de toma de decisiones. Esto sirve para resaltar la diferencia entre significancia sustantiva y estadística: en particular, para muestras grandes, los investigadores encuentran variables que son estadísticamente significativas pero prácticamente poco importantes. En estos casos, puede ser prudente que el investigador omita variables de la especificación del modelo cuando su presencia no esté de acuerdo con la teoría aceptada, incluso si se consideran estadísticamente significativas.
Efectos Causales. Si cambiamos \(x\), ¿cambiaría \(y\)? Como estudiantes de ciencias básicas, aprendimos principios que involucran acciones y reacciones. Agregar masa a una bola en movimiento aumenta la fuerza de su impacto contra una pared. Sin embargo, en las ciencias sociales, las relaciones son probabilísticas, no deterministas, y por lo tanto más sutiles. Por ejemplo, a medida que la edad (\(x\)) aumenta, la probabilidad de morir en un año (\(y\)) aumenta para la mayoría de las curvas de mortalidad humana. Comprender la causalidad, incluso la probabilística, es la raíz de toda la ciencia y proporciona la base para la toma de decisiones informada.
Es importante reconocer que los procesos causales generalmente no pueden demostrarse exclusivamente a partir de los datos; los datos solo pueden presentar evidencia empírica relevante que sirva como un eslabón en una cadena de razonamiento sobre los mecanismos causales. Para la causalidad, hay tres condiciones necesarias: (i) asociación estadística entre variables, (ii) orden temporal apropiado y (iii) la eliminación de hipótesis alternativas o el establecimiento de un mecanismo causal formal.
Como ejemplo, recordemos el estudio de Galton en la Sección 1.1, que relaciona la altura de los hijos adultos (\(y\)) con un índice de la altura de los padres (\(x\)). Para este estudio, estaba claro que hay una fuerte asociación estadística entre \(x\) e \(y\). La demografía también deja claro que las mediciones de los padres (\(x\)) preceden a las mediciones de los hijos (\(y\)). Lo que no es seguro es el mecanismo causal. Por ejemplo, en la Sección 1.5, mencionamos la posibilidad de que una variable omitida, como la dieta familiar, podría estar influyendo tanto en \(x\) como en \(y\). Se necesitan evidencias y teorías de la biología humana y la genética para establecer un mecanismo causal formal.
Ejemplo: Raza, Redlining y Precios del Seguro de Automóviles. En un artículo con este título, Harrington y Niehaus (1998) investigaron si las compañías de seguros participaban en conductas discriminatorias (raciales), conocidas comúnmente como redlining. La discriminación racial es ilegal y las compañías de seguros no pueden usar la raza para determinar los precios. El término redlining se refiere a la práctica de trazar líneas rojas en un mapa para indicar áreas que las aseguradoras no cubrirán, áreas que típicamente contienen una alta proporción de minorías.
Para investigar si existe o no discriminación racial en los precios del seguro, Harrington y Niehaus recopilaron datos de primas y reclamaciones de seguros de automóviles de pasajeros privados del Departamento de Seguros de Missouri para el período 1988-1992. Aunque las compañías de seguros no mantienen información sobre raza/etnicidad en sus datos de primas y reclamaciones, dicha información está disponible a nivel de código postal en la Oficina del Censo de EE. UU. Al agregar las primas y las reclamaciones al nivel de código postal, Harrington y Niehaus pudieron evaluar si las áreas con un mayor porcentaje de población negra pagaban más por el seguro (PCTBLACK).
Una medida de precios ampliamente utilizada es la razón de siniestralidad, definida como la relación entre reclamaciones y primas. Esta medida la rentabilidad de las aseguradoras; si existe discriminación racial en los precios, se esperaría ver una baja razón de siniestralidad en áreas con una alta proporción de minorías. Harrington y Niehaus usaron esto como la variable dependiente, después de tomar logaritmos para abordar la asimetría en la distribución de la razón de siniestralidad.
Harrington y Niehaus (1998) estudiaron 270 códigos postales alrededor de seis ciudades principales en Missouri, donde había grandes concentraciones de minorías. La Tabla 6.1 presenta los hallazgos de la cobertura comprensiva, aunque los autores también investigaron la cobertura de colisión y de responsabilidad civil. Además de la variable principal de interés, PCTBLACK, se introdujeron algunas variables de control relacionadas con la distribución por edades (PCT1824 y PCT55UP), estado civil (MARRIED), población (ln TOTPOP) y empleo (PCTUNEMP). El tamaño de la póliza se midió indirectamente a través del valor promedio del automóvil (ln AVCARV).
La Tabla 6.1 informa que solo el tamaño de la póliza y la población son determinantes estadísticamente significativos de las razones de siniestralidad. De hecho, el coeficiente asociado con PCTBLACK tiene un signo positivo, lo que indica que las primas son más bajas en áreas con altas concentraciones de minorías (aunque no significativo). En un mercado de seguros eficiente, esperaríamos que los precios estuvieran estrechamente alineados con las reclamaciones y que existieran pocos patrones generales.
| Variable | Descripción | Coeficiente de Regresión | \(t\)-Estadístico |
|---|---|---|---|
| Intercept | 1.98 | 2.73 | |
| PCTBLACK | Proporción de la población negra | 0.11 | 0.63 |
| ln TOTPOP | Logaritmo de la población total | -0.1 | -4.43 |
| PCT1824 | Porcentaje de la población entre 18 y 24 años | -0.23 | -0.5 |
| PCT55UP | Porcentaje de la población de 55 años o más | -0.47 | -1.76 |
| MARRIED | Porcentaje de la población casada | -0.32 | -0.9 |
| PCTUNEMP | Porcentaje de la población desempleada | 0.11 | 0.1 |
| ln AVCARV | Logaritmo del valor promedio del automóvil asegurado | -0.87 | -3.26 |
| Fuente: Harrington y Niehaus (1998) | |||
| \(R_a^2\) 0.11 |
Ciertamente, los hallazgos de Harrington y Niehaus (1998) son inconsistentes con la hipótesis de discriminación racial en los precios. Establecer una falta de significancia estadística suele ser más difícil que establecer significancia. En el artículo de Harrington y Niehaus (1998), hay muchas especificaciones de modelos alternativas que evalúan la robustez de sus hallazgos frente a diferentes procedimientos de selección de variables y diferentes subconjuntos de datos. La Tabla 6.1 presenta los estimadores de los coeficientes y los \(t\)-ratios calculados utilizando mínimos cuadrados ponderados, con el tamaño de la población como pesos. Los autores también utilizaron mínimos cuadrados (ordinarios) con errores estándar robustos, obteniendo resultados similares.
6.1.2 Otras Interpretaciones
Cuando se toman colectivamente, las combinaciones lineales de los coeficientes de regresión pueden interpretarse como la función de regresión:
\[ \mathrm{E~}y = \beta_0 + \beta_1 x_1 + \cdots + \beta_k x_k. \]
Al presentar los resultados de regresión, los lectores quieren saber qué tan bien el modelo se ajusta a los datos. La Sección 5.6.1 resumió varias estadísticas de bondad de ajuste que se informan rutinariamente en investigaciones de regresión.
Función de Regresión y Precios. Al evaluar los datos de reclamaciones de seguros, la función de regresión representa las reclamaciones esperadas y, por lo tanto, forma la base de la función de precios. (Vea el ejemplo en el Capítulo 4). En este caso, la forma de la función de regresión y los niveles para combinaciones clave de variables explicativas son de interés.
Estudios de Referencia (Benchmarking). En algunas investigaciones, el propósito principal puede ser determinar si una observación específica está “en línea” con las otras disponibles. Por ejemplo, en el Capítulo 20 examinaremos los salarios de los CEOs. El propósito principal de dicho análisis podría haber sido ver si el salario de una persona es alto o bajo en comparación con otros en la muestra, controlando por características como la industria y los años de experiencia. El residuo resume la desviación de la respuesta respecto a la esperada según el modelo. Si el residuo es inusualmente grande o pequeño, entonces interpretamos esto como que existen circunstancias inusuales asociadas con esta observación. Este análisis no sugiere la naturaleza ni las causas de estas circunstancias; simplemente indica que la observación es inusual en comparación con las demás en la muestra. Para algunas investigaciones, como en litigios relacionados con paquetes de compensación, esta es una declaración poderosa.
Predicción. Muchas aplicaciones actuariales conciernen a la predicción, donde el interés radica en describir la distribución de una variable aleatoria que aún no se ha realizado. Al establecer reservas, los actuarios de compañías de seguros están estableciendo pasivos para futuras reclamaciones que predicen que se realizarán y, por lo tanto, se convertirán en gastos eventuales de la compañía. La predicción, o pronóstico, es la principal motivación de la mayoría de los análisis de datos de series temporales, que se trata en los Capítulos 7-10.
La predicción de una sola variable aleatoria en el contexto de la regresión lineal múltiple se introdujo en la Sección 4.2.3. Aquí, asumimos que tenemos disponible un conjunto dado de características, \(\mathbf{x}_{\ast}=(1,x_{\ast 1},\ldots,x_{\ast k})^{\prime }\). Según nuestro modelo, la nueva respuesta es:
\[ y_{\ast}=\beta_0 + \beta_1 x_{\ast 1} + \cdots + \beta_k x_{\ast k} + \varepsilon_{\ast}. \]
Utilizamos como nuestro predictor puntual:
\[ \hat{y}_{\ast}=b_{0} + b_{1} x_{\ast 1} + \cdots + b_{k} x_{\ast k}. \]
Como en la Sección 2.5.3, podemos descomponer el error de predicción en el error de estimación más el error aleatorio, de la siguiente manera:
\[ \begin{array}{ccccc} \underbrace{y^{\ast}-\widehat{y}^{\ast}} & = & \underbrace{\beta_0 - b_{0} + (\beta_1 - b_{1})x_{\ast 1} + \cdots + (\beta_k - b_{k})x_{\ast k}} & + & \underbrace{\varepsilon ^{\ast}} \\ {\small \text{error de predicción}} & {\small =} & {\small \text{error en la estimación de la} } & {\small +} & {\small \text{desviación} }\\ & & {\small \text{función de regresión en } x_{\ast 1}, \ldots, x_{\ast k}} & & {\small \text{adicional} } \end{array} \]
Esta descomposición nos permite proporcionar una distribución para el error de predicción. Es habitual asumir una normalidad aproximada. Con esta suposición adicional, resumimos esta distribución utilizando un intervalo de predicción
\[\begin{equation} \hat{y}_{\ast} \pm t_{n-(k+1),1-\alpha /2} ~ se(pred), \tag{6.2} \end{equation}\]
donde
\[ se(pred) = s \sqrt{1 + \mathbf{x}_{\ast}^{\prime }(\mathbf{X}^{\prime} \mathbf{X})^{-1} \mathbf{x}_{\ast}}. \]
Aquí, el valor \(t\) \(t_{n-(k+1),1-\alpha /2}\) es un percentil de la distribución \(t\) con \(df=n-(k+1)\) grados de libertad. Esto extiende la ecuación (2.7).
Comunicar el rango de resultados probables es un objetivo importante. Al analizar datos, puede haber varias técnicas alternativas de predicción disponibles. Incluso dentro de la clase de modelos de regresión, cada uno de los varios modelos candidatos producirá una predicción diferente. Es importante proporcionar una distribución o rango de posibles errores. Los consumidores ingenuos pueden desilusionarse fácilmente con los resultados de las predicciones de los modelos de regresión. A estos consumidores se les dice (correctamente) que el modelo de regresión es óptimo, basado en ciertos criterios bien definidos, y luego se les proporciona una predicción puntual, como \(\hat{y}_{\ast}\). Sin conocimiento de un intervalo, el consumidor tiene expectativas sobre el rendimiento de la predicción, generalmente más altas de lo que justifica la información disponible en la muestra. Un intervalo de predicción no solo proporciona una única predicción óptima puntual, sino también un rango de fiabilidad.
Al hacer las predicciones, hay una suposición importante: la nueva observación sigue el mismo modelo que se utilizó en la muestra. Por lo tanto, las condiciones básicas sobre la distribución de los errores deben permanecer sin cambios para las nuevas observaciones. También es importante que el nivel de las variables predictoras, \(x_{\ast 1},\ldots,x_{\ast k}\), sea similar al de las observaciones disponibles en la muestra. Si una o varias de las variables predictoras difieren drásticamente de las de la muestra disponible, entonces la predicción resultante puede ser inadecuada. Por ejemplo, sería imprudente usar el modelo desarrollado en las Secciones 2.1 a 2.3 para predecir la lotería de una región con una población de \(x_{\ast}=400,000\), más de diez veces la mayor población en nuestra muestra. Aunque sería fácil introducir \(x_{\ast}=400,000\) en nuestras fórmulas, el resultado tendría poco sentido intuitivo. Extrapolar relaciones más allá de los datos observados requiere experiencia tanto en la naturaleza de los datos como en la metodología estadística. En la Sección 6.3, identificaremos este problema como un sesgo potencial debido a la región de muestreo.
6.2 La Importancia de la Selección de Variables
Por un lado, elegir un modelo teórico que represente exactamente los eventos del mundo real es probablemente una tarea imposible. Por otro lado, elegir un modelo que represente aproximadamente el mundo real es un asunto práctico importante. Cuanto más cerca esté nuestro modelo del mundo real, más precisas serán las afirmaciones que hagamos, sugeridas por el modelo. Aunque no podemos obtener el modelo correcto, podemos seleccionar un modelo útil o al menos adecuado.
Los usuarios de la estadística, desde el principiante hasta el experto experimentado, siempre seleccionarán un modelo inadecuado de vez en cuando. La pregunta clave es: ¿Qué tan importante es seleccionar un modelo adecuado? Aunque no se puede prever cada tipo de error, hay algunos principios orientadores que son útiles tener en cuenta al seleccionar un modelo.
6.2.1 Sobreajuste del Modelo
Este tipo de error ocurre cuando se añaden variables superfluas o extrañas al modelo especificado. Si solo se añaden un pequeño número de variables extrañas, como una o dos, entonces este tipo de error probablemente no distorsionará de manera significativa la mayoría de los tipos de conclusiones que puedan alcanzarse con el modelo ajustado. Por ejemplo, sabemos que cuando añadimos una variable al modelo, la suma de cuadrados de los errores no aumenta. Si la variable es extraña, entonces la suma de cuadrados de los errores tampoco disminuirá de manera apreciable. De hecho, añadir una variable extraña puede aumentar \(s^2\) porque el denominador es más pequeño por un grado de libertad. Sin embargo, para conjuntos de datos de tamaño de muestra moderado, el efecto es mínimo. Sin embargo, añadir varias variables extrañas puede inflar \(s^{2}\) de manera apreciable. Además, existe la posibilidad de que añadir variables explicativas extrañas induzca, o empeore, la presencia de colinealidad.
Un punto más importante es que, al añadir variables extrañas, nuestras estimaciones de los coeficientes de regresión permanecen insesgadas. Considere el siguiente ejemplo.
Ejemplo: Regresión usando una Variable Explicativa. Suponga que el modelo verdadero de las respuestas es
\[ y_i = \beta_0 + \varepsilon_i, \quad i = 1, \ldots, n. \]
Bajo este modelo, el nivel de una variable explicativa genérica \(x\) no afecta el valor de la respuesta \(y\). Si fuéramos a predecir la respuesta en cualquier nivel de \(x\), la predicción tendría un valor esperado de \(\beta_0\). Sin embargo, supongamos que equivocadamente ajustamos el modelo
\[ y_i = \beta_0^{\ast} + \beta_1^{\ast}x_i + \varepsilon_i^{\ast}. \]
Con este modelo, la predicción en un nivel genérico \(x\) es \(b_{0}^{\ast} + b_{1}^{\ast}x\) donde \(b_{0}^{\ast}\) y \(b_{1}^{\ast}\) son las estimaciones de mínimos cuadrados ordinarios de \(\beta_0^{\ast}\) y \(\beta_1^{\ast}\), respectivamente. No es demasiado difícil confirmar que
\[ \text{Sesgo} = \text{E}(b_{0}^{\ast} + b_{1}^{\ast}x) - \text{E}y = 0, \]
donde las esperanzas se calculan usando el modelo verdadero. Por lo tanto, al usar un modelo ligeramente más grande del que deberíamos, no pagamos en términos de cometer un error persistente a largo plazo, como el representado por el sesgo. El precio de cometer este error es que nuestro error estándar es ligeramente mayor de lo que sería si hubiéramos elegido el modelo correcto.
6.2.2 Subajuste del Modelo
Este tipo de error ocurre cuando se omiten variables importantes en la especificación del modelo; es más grave que el sobreajuste. Omitir variables importantes puede causar cantidades apreciables de sesgo en nuestras estimaciones resultantes. Además, debido a este sesgo, las estimaciones resultantes de \(s^{2}\) son más grandes de lo necesario. Un \(s\) más grande infla nuestros intervalos de predicción y produce pruebas inexactas de hipótesis sobre la importancia de las variables explicativas. Para ver los efectos de subajustar un modelo, volvemos al ejemplo anterior.
Ejemplo: Regresión usando una Variable Explicativa - Continuación. Ahora invertimos los roles de los modelos descritos antes. Supongamos que el modelo verdadero es
\[ y_i = \beta_0 + \beta_1 x_i + \varepsilon_i \]
y que ajustamos erróneamente el modelo,
\[ y_i = \beta_0^{\ast} + \varepsilon_i^{\ast}. \]
Por lo tanto, hemos omitido inadvertidamente los efectos de la variable explicativa \(x\). Con el modelo ajustado, usaríamos \(\bar{y}\) para nuestra predicción en un nivel genérico de \(x\). A partir del modelo verdadero, tenemos \(\bar{y} = \beta_0 + \beta_1 \bar{x} + \bar{\varepsilon}\). El sesgo de la predicción en \(x\) es
\[ \begin{array}{ll} \text{Sesgo} &= \text{E} \bar{y} - \text{E} (\beta_0 + \beta_1 x + \varepsilon) \\ &= \text{E} (\beta_0 + \beta_1 \bar{x} + \bar{\varepsilon}) - (\beta_0 + \beta_1 x) \\ &= \beta_1 (\bar{x} - x). \end{array} \]
Si \(\beta_1\) es positivo, entonces subestimamos para valores grandes de \(x\), resultando en un sesgo negativo, y sobreestimamos para valores pequeños de \(x\) (en relación con \(\overline{x}\)). Así, hay un error persistente a largo plazo al omitir la variable explicativa \(x\). De manera similar, se puede verificar que este tipo de error produce estimaciones sesgadas de los parámetros de regresión y un valor inflado de \(s^{2}\).
Por supuesto, nadie quiere sobreajustar o subajustar el modelo. Sin embargo, los datos de las ciencias sociales a menudo son desordenados y puede ser difícil saber si incluir o no una variable en el modelo. Al seleccionar variables, los analistas a menudo se guían por el principio de parsimonia, también conocido como la Navaja de Occam, que establece que cuando hay varias explicaciones posibles para un fenómeno, se debe usar la más simple. Hay varios argumentos para preferir modelos más simples:
- Una explicación más simple es más fácil de interpretar.
- Los modelos simples, también conocidos como modelos “parsimoniosos”, a menudo funcionan bien con datos fuera de la muestra.
- Las variables superfluas pueden causar problemas de colinealidad, lo que dificulta la interpretación de los coeficientes individuales.
El punto de vista opuesto se puede resumir en una cita a menudo atribuida a Albert Einstein, que dice que debemos usar “el modelo más simple posible, pero no más simple”. Esta sección demuestra que subajustar un modelo, omitiendo variables importantes, es típicamente un error más grave que incluir variables superfluas que aportan poco a nuestra capacidad de explicar los datos. Incluir variables superfluas disminuye los grados de libertad y aumenta la estimación de la variabilidad, lo cual suele ser de menor preocupación en las aplicaciones actuariales.
En caso de duda, deje la variable en el modelo.
6.3 La Importancia de la Recolección de Datos
El proceso de modelado de regresión comienza con la recolección de datos. Habiendo estudiado los resultados y el proceso de selección de variables, ahora podemos discutir las entradas al proceso. No es sorprendente que haya una larga lista de posibles dificultades que se encuentran con frecuencia al recolectar datos para regresión. En esta sección, identificamos las principales dificultades potenciales y proporcionamos algunas vías para evitar estas dificultades.
6.3.1 Error en el Marco Muestral y Selección Adversa
El error en el marco muestral ocurre cuando el marco muestral, la lista de la cual se extrae la muestra, no es una aproximación adecuada de la población de interés. Al final, una muestra debe ser un subconjunto representativo de una población más grande, o universo, de interés. Si la muestra no es representativa, tomar una muestra más grande no elimina el sesgo; simplemente repite el mismo error una y otra vez.
Ejemplo: Encuesta de Literary Digest. Quizás el ejemplo más conocido de error en el marco muestral es de la encuesta de Literary Digest en 1936. Esta encuesta se realizó para predecir el ganador de las elecciones presidenciales de Estados Unidos en 1936. Los dos principales candidatos eran Franklin D. Roosevelt, el demócrata, y Alfred Landon, el republicano. Literary Digest, una revista prominente en ese momento, realizó una encuesta a diez millones de votantes. De los encuestados, 2.4 millones respondieron, prediciendo una victoria “arrolladora” de Landon por un margen de 57% a 43%. Sin embargo, la elección real resultó en una victoria abrumadora de Roosevelt, por un margen de 62% a 38%. ¿Qué salió mal?
Hubo varios problemas con la encuesta de Literary Digest. Quizás el más importante fue el error en el marco muestral. Para desarrollar su marco muestral, Literary Digest utilizó direcciones de guías telefónicas y listas de membresía de clubes. En 1936, Estados Unidos estaba en el fondo de la Gran Depresión; los teléfonos y las membresías de clubes eran un lujo que solo las personas de altos ingresos podían permitirse. Así, la lista de Literary Digest incluía una cantidad no representativa de personas de altos ingresos. En elecciones presidenciales anteriores realizadas por Literary Digest, los ricos y los pobres tendían a votar de manera similar y esto no era un problema. Sin embargo, los problemas económicos fueron los principales temas políticos en las elecciones presidenciales de 1936. Como resultó ser, los pobres tendían a votar por Roosevelt y los ricos por Landon. Como resultado, los resultados de la encuesta de Literary Digest fueron gravemente erróneos. Tomar una muestra grande, incluso de tamaño 2.4 millones, no ayudó; el error básico se repitió una y otra vez.
El sesgo en el marco muestral ocurre cuando la muestra no es un subconjunto representativo de la población de interés. Al analizar los datos de las compañías de seguros, este sesgo puede surgir debido a la selección adversa. En muchos mercados de seguros, las compañías diseñan y fijan los precios de los contratos y los asegurados deciden si desean o no entrar en un acuerdo contractual (de hecho, los asegurados “solicitan” un seguro, por lo que los aseguradores también tienen el derecho de no entrar en el acuerdo). Por lo tanto, alguien es más probable que entre en un acuerdo si cree que la aseguradora está subestimando su riesgo, especialmente a la luz de las características del asegurado que no son observadas por la aseguradora. Por ejemplo, es bien sabido que la experiencia de mortalidad de una muestra de compradores de rentas vitalicias no es representativa de la población en general; las personas que compran rentas vitalicias tienden a ser saludables en relación con la población general. No compraría una renta vitalicia que pague un beneficio periódico mientras esté vivo si tuviera mala salud y pensara que su probabilidad de una larga vida es baja. La selección adversa surge porque los “malos riesgos”, aquellos con reclamos mayores de los esperados, son más propensos a entrar en contratos que los “buenos riesgos” correspondientes. Aquí, la expectativa se desarrolla en función de características (variables explicativas) que pueden ser observadas por la aseguradora.
Por supuesto, existe un gran mercado para las rentas vitalicias y otras formas de seguros en las que existe selección adversa. Las compañías de seguros pueden fijar precios adecuados para estos mercados redefiniendo su “población de interés” para que no sea la población general, sino la población de asegurados potenciales. Así, por ejemplo, al fijar el precio de las rentas vitalicias, las aseguradoras utilizan datos de mortalidad de rentistas, no datos de la población general. De esta manera, pueden evitar posibles desajustes entre la población y la muestra. Más generalmente, la experiencia de casi cualquier compañía difiere de la población general debido a los estándares de suscripción y las filosofías de ventas. Algunas compañías buscan “riesgos preferidos” ofreciendo descuentos educativos, bonos por buen manejo, etc., mientras que otras buscan asegurados de alto riesgo. La muestra de asegurados de la compañía diferirá de la población general y el grado de la diferencia puede ser un aspecto interesante para cuantificar en un análisis.
El sesgo en el marco muestral puede ser particularmente importante cuando una compañía busca comercializar un nuevo producto para el cual no tiene datos de experiencia. Identificar un mercado objetivo y su relación con la población general es un aspecto importante de un plan de desarrollo de mercado.
6.3.2 Regiones de Muestreo Limitadas
Una región de muestreo limitada puede dar lugar a un sesgo potencial cuando intentamos extrapolar fuera de la región de muestreo. Para ilustrarlo, considere la Figura 6.1. Aquí, con base en los datos de la región de muestreo, una línea puede parecer una representación apropiada. Sin embargo, si una curva cuadrática es la verdadera respuesta esperada, cualquier pronóstico que esté lejos de la región de muestreo estará seriamente sesgado.

Figura 6.1: La extrapolación fuera de la región de muestreo puede estar sesgada
Otro problema debido a una región de muestreo limitada, aunque no sea un sesgo, que puede surgir es la dificultad para estimar un coeficiente de regresión. En el Capítulo 5, vimos que una menor dispersión de una variable, ceteris paribus, significa una estimación menos confiable del coeficiente de pendiente asociado con esa variable. Es decir, a partir de la Sección 5.5.2 o de la ecuación (6.1), vemos que cuanto menor es la dispersión de \(x_{j}\), medida por \(s_{x_{j}}\), mayor es el error estándar de \(b_{j},se(b_{j})\). Llevado al extremo, donde \(s_{x_{j}}=0\), podríamos tener una situación como la ilustrada en la Figura 6.2. Para la situación extrema ilustrada en la Figura 6.2, no hay suficiente variación en \(x\) para estimar el parámetro de pendiente correspondiente.

Figura 6.2: La falta de variación en \(x\) significa que no podemos ajustar una línea única que relacione \(x\) y \(y\).
6.3.3 Variables Dependientes Limitadas, Censura y Truncamiento
En algunas aplicaciones, la variable dependiente está limitada a ciertos rangos. Para entender por qué esto es un problema, primero recordemos que bajo el modelo de regresión lineal, la variable dependiente es igual a la función de regresión más un error aleatorio. Normalmente, se supone que el error aleatorio se distribuye aproximadamente de manera normal, por lo que la respuesta varía de forma continua. Sin embargo, si los resultados de la variable dependiente están restringidos o limitados, entonces los resultados no son puramente continuos. Esto significa que nuestra suposición de errores normales no es estrictamente correcta y puede no ser una buena aproximación.
Para ilustrar esto, la Figura 6.3 muestra un gráfico del ingreso de un individuo (\(x\)) versus la cantidad de seguro adquirido (\(y\)). La muestra en este gráfico representa dos submuestras: aquellos que compraron seguro, correspondientes a \(y>0\), y aquellos que no lo hicieron, correspondientes al “precio” \(y=0\). Ajustar una única línea a estos datos desinformaría a los usuarios sobre los efectos de \(x\) sobre \(y\).
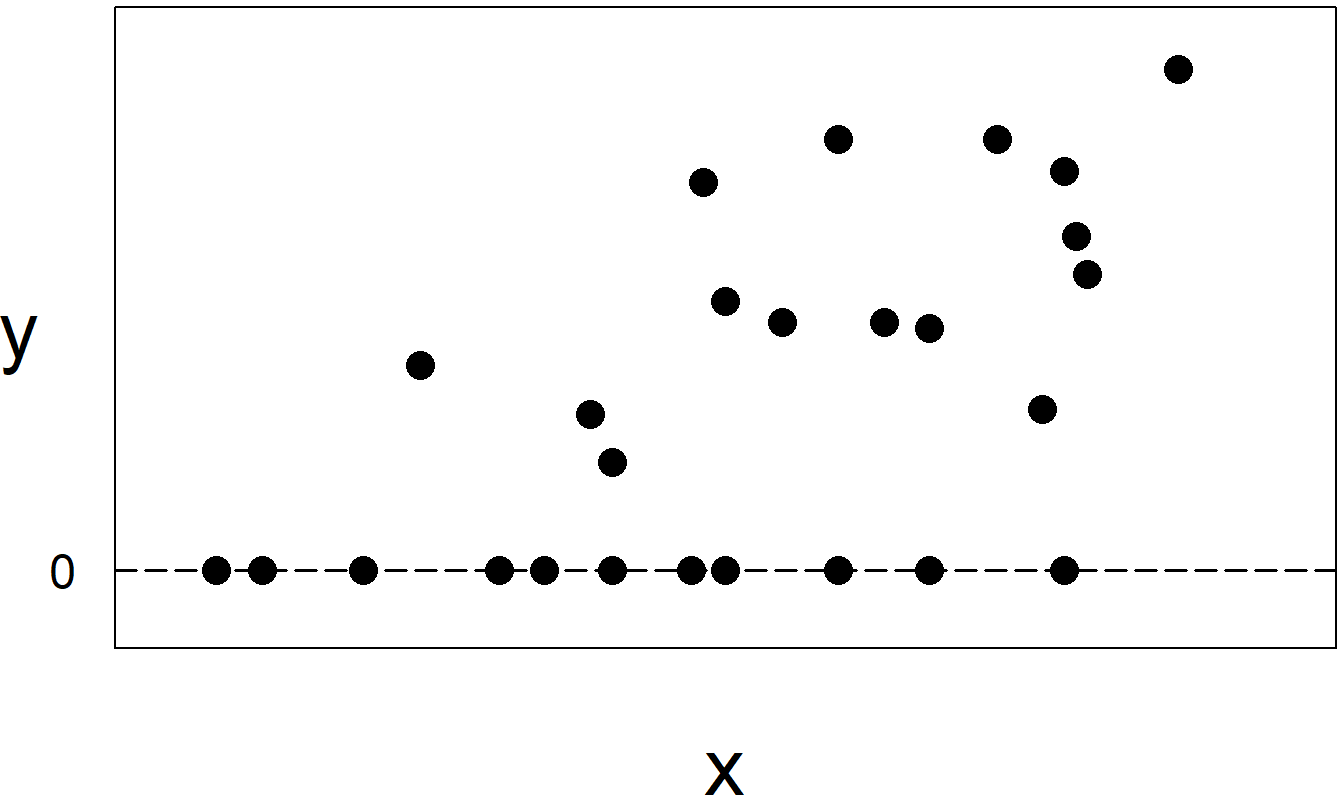
Figura 6.3: Cuando los individuos no compran nada, se registran como ventas de \(y=0\).
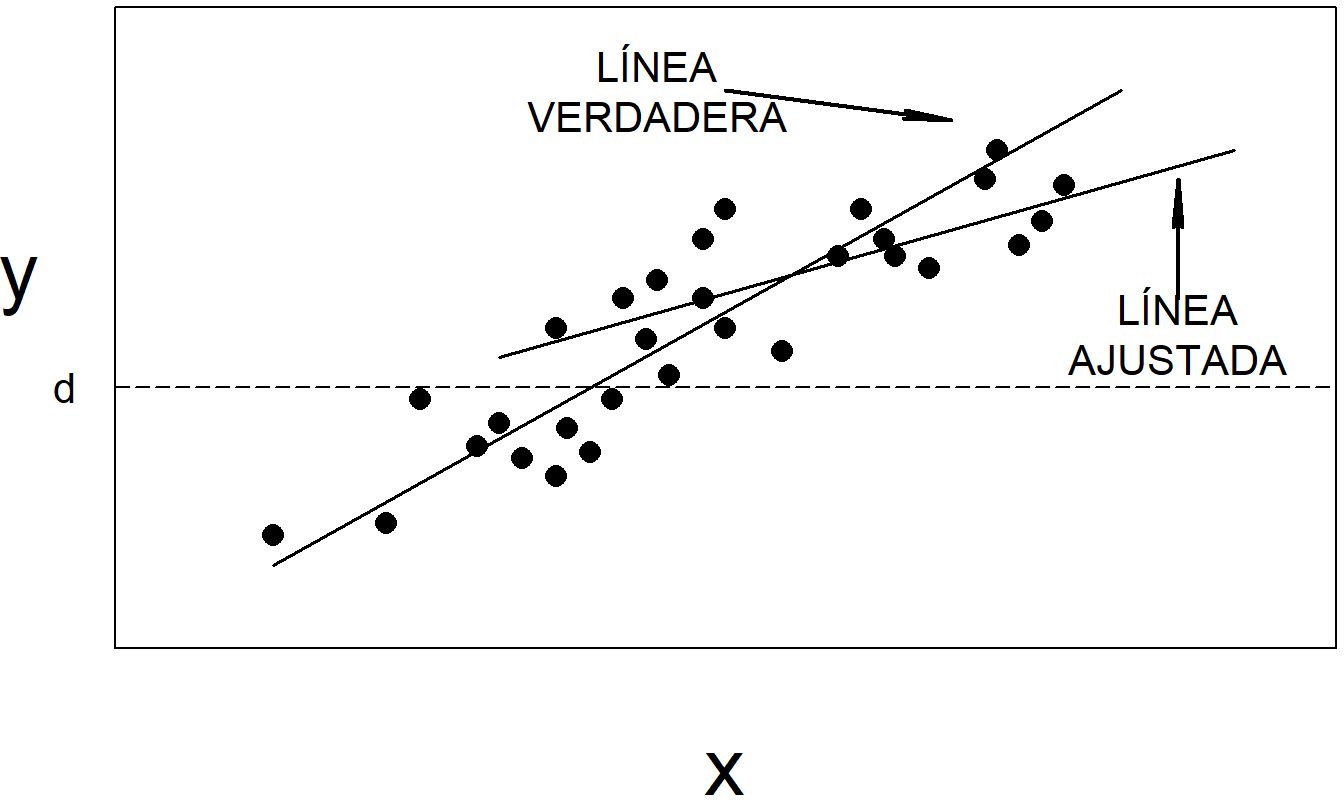
Figura 6.4: Si se omiten las respuestas por debajo de la línea horizontal en \(y=d\), la línea de regresión ajustada puede ser muy diferente de la verdadera línea de regresión.
Si consideráramos solo a aquellos que compraron seguro, entonces todavía tendríamos un límite inferior implícito de cero (si un precio de seguro debe ser mayor que cero). Sin embargo, los precios deben estar cerca de este límite para una región de muestreo dada y, por lo tanto, no representar un problema práctico importante. Al incluir a varias personas que no compraron seguro (y, por lo tanto, gastaron $0 en seguro), nuestra región de muestreo ahora claramente incluye este límite inferior.
Hay varias maneras en las que las variables dependientes pueden estar restringidas o censuradas. La Figura 6.3 ilustra el caso en el que el valor de \(y\) no puede ser inferior a cero. Como otro ejemplo, los siniestros de seguros a menudo están restringidos a ser menores o iguales a un límite superior especificado en la póliza de seguro. Si la censura es severa, los mínimos cuadrados ordinarios producen resultados sesgados. En el Capítulo 15 se describen enfoques especializados, conocidos como modelos de regresión censurada, para manejar este problema.
La Figura 6.4 ilustra otra limitación comúnmente encontrada en el valor de la variable dependiente. Para esta ilustración, suponga que \(y\) representa una pérdida asegurada y que \(d\) representa el deducible de una póliza de seguro. En este escenario, es práctica común que las aseguradoras no registren pérdidas por debajo de \(d\) (generalmente no son reportadas por los asegurados). En este caso, se dice que los datos están truncados. No es sorprendente que existan modelos de regresión truncada para manejar esta situación. Como regla general, los datos truncados representan una fuente de sesgo más grave que los datos censurados. Cuando los datos están truncados, no tenemos valores de las variables dependientes y, por lo tanto, tenemos menos información que cuando los datos están censurados. Consulte el Capítulo 15 para obtener más detalles.
6.3.4 Variables Omitidas y Endógenas
Por supuesto, los analistas prefieren incluir todas las variables importantes. Sin embargo, un problema común es que puede que no tengamos los recursos ni la previsión para recopilar y analizar todos los datos relevantes. Además, a veces se nos prohíbe incluir ciertas variables. Por ejemplo, en la tarificación de seguros, generalmente se nos impide usar la etnia como una variable de tarificación. Además, hay muchas tablas de mortalidad y otras tablas de decremento que son “unisex”, es decir, no distinguen entre géneros.
Omitir variables importantes puede afectar nuestra capacidad para ajustar la función de regresión; esto puede afectar el rendimiento dentro de la muestra (explicación) así como fuera de la muestra (predicción). Si la variable omitida no está correlacionada con otras variables explicativas, entonces la omisión no afectará la estimación de los coeficientes de regresión. Sin embargo, típicamente este no es el caso. La Sección 3.4.3, el Ejemplo del Refrigerador, ilustra un caso grave en el que la dirección de un resultado estadísticamente significativo se invirtió con la presencia de una variable explicativa. En este ejemplo, encontramos que en una muestra transversal de refrigeradores existía una correlación significativamente positiva entre el precio y el costo anual de energía para operar el refrigerador. Esta correlación positiva era contraintuitiva porque uno esperaría que precios más altos significaran menores gastos anuales en operar un refrigerador. Sin embargo, cuando incluimos varias variables adicionales, en particular, medidas del tamaño de un refrigerador, encontramos una relación significativamente negativa entre el precio y los costos de energía. Nuevamente, al omitir estas variables adicionales, hubo un sesgo importante al usar la regresión para entender la relación entre el precio y los costos de energía.
Las variables omitidas pueden llevar a la presencia de variables explicativas endógenas. Una variable exógena es aquella que se puede considerar “dada” para los propósitos en cuestión. Una variable endógena es aquella que no cumple con el requisito de exogeneidad. Una variable omitida puede afectar tanto a \(y\) como a \(x\) y, en este sentido, inducir una relación entre las dos variables. Si la relación entre \(x\) y \(y\) se debe a una variable omitida, es difícil condicionar en \(x\) al estimar un modelo para \(y\).
Hasta ahora, las variables explicativas han sido tratadas como no estocásticas. Para muchas aplicaciones en ciencias sociales, es más intuitivo considerar que las \(x\) son estocásticas y realizar inferencias condicionales a sus realizaciones. Por ejemplo, bajo esquemas de muestreo comunes, podemos estimar la función de regresión condicional \[ \mathrm{E~}\left(y|x_1, \ldots, x_k \right) = \beta_0 + \beta_1 x_1 + \ldots + \beta_k x_k. \] Esto se conoce como un modelo “basado en el muestreo”.
En la literatura económica, Goldberger (1972) define un modelo estructural como un modelo estocástico que representa una relación causal, no una relación que simplemente captura asociaciones estadísticas. Los modelos estructurales pueden contener fácilmente variables explicativas endógenas. Para ilustrar, consideremos un ejemplo que relaciona reclamaciones y primas. Para muchas líneas de negocio, las clases de primas son simplemente funciones no lineales de factores exógenos como la edad, el género, etc. Para otras líneas de negocio, las primas cobradas son una función del historial de reclamaciones previo. Consideremos las ecuaciones del modelo que relacionan las reclamaciones (\(y_{it}, t=1, 2\)) con las primas (\(x_{it}, t=1, 2\)): \[\begin{eqnarray*} y_{i2} = \beta_{0,C} + \beta_{1,C} y_{i1} + \beta_{2,C} x_{i2} + \varepsilon_{i1} \\ x_{i2} = \beta_{0,P} + \beta_{1,P} y_{i1} + \beta_{2,P} x_{i1} + \varepsilon_{i2}. \end{eqnarray*}\] En este modelo, las reclamaciones y las primas del período actual (\(t=2\)) se ven afectadas por las reclamaciones y primas del período anterior. Este es un ejemplo de un modelo de ecuaciones estructurales que requiere técnicas especiales de estimación. ¡Nuestros procedimientos de estimación habituales están sesgados!
Ejemplo: Raza, Discriminación y Precios de Seguros de Automóviles - Continuación. Aunque Harrington y Niehaus (1998) no encontraron discriminación racial en la tarificación de seguros, sus resultados sobre el acceso al seguro fueron inconclusos. Los aseguradores ofrecen contratos de riesgo “estándar” y “preferido” a los solicitantes que cumplen con estándares restrictivos de suscripción, en comparación con los contratos de riesgo “subestándar” donde los estándares de suscripción son más relajados. Los reclamos esperados son más bajos para los contratos de riesgo estándar y preferido, y por lo tanto, las primas son más bajas, que para los contratos subestándar. Harrington y Niehaus examinaron la proporción de solicitantes a quienes se les ofrecieron contratos subestándar, NSSHARE, y encontraron que estaba significativamente relacionada positivamente con PCTBLACK, la proporción de la población negra. Esto sugiere evidencia de discriminación racial; ellos afirman que esta es una interpretación inapropiada debido al sesgo por variables omitidas.
Harrington y Niehaus argumentan que la proporción de solicitantes a quienes se les ofrecieron contratos subestándar debería estar positivamente relacionada con los costos esperados de los reclamos. Además, los costos esperados de los reclamos están fuertemente relacionados con PCTBLACK, porque las minorías en la muestra tendían a tener ingresos más bajos. Así, las variables no observadas, como los ingresos, tienden a impulsar la relación positiva entre NSSHARE y PCTBLACK. Debido a que los datos se analizan a nivel de código postal y no a nivel individual, el potencial sesgo por variables omitidas hizo que el análisis fuera inconcluso.
6.3.5 Datos Faltantes
En los ejemplos de datos, ilustraciones, estudios de caso y ejercicios de este texto, hay muchas instancias en las que ciertos datos están faltantes o no disponibles para el análisis. En cada caso, los datos no se perdieron de manera descuidada, sino que no estaban disponibles debido a razones sustantivas asociadas con la recolección de datos. Por ejemplo, cuando examinamos los rendimientos de acciones de una muestra de empresas, vimos que algunas empresas no tenían un promedio de ganancias por acción de cinco años. La razón era simplemente que no habían estado en existencia durante cinco años. Como otro ejemplo, al examinar las esperanzas de vida, algunos países no reportaron la tasa de fertilidad total porque les faltaban recursos administrativos para capturar estos datos. Los datos faltantes son un aspecto inescapable al analizar datos en las ciencias sociales.
Cuando la razón para la falta de disponibilidad de datos no está relacionada con los valores reales de los datos, se dice que los datos están faltantes al azar. Existen varias técnicas para manejar datos faltantes al azar, ninguna de las cuales es claramente superior a las otras. Una “técnica” es simplemente ignorar el problema. Por lo tanto, faltar al azar a veces se denomina el caso ignorable de datos faltantes.
Si hay solo unos pocos datos faltantes, en comparación con el número total disponible, una estrategia ampliamente empleada es eliminar las observaciones correspondientes a los datos faltantes. Suponiendo que los datos están faltantes al azar, se pierde poca información al eliminar una pequeña porción de los datos. Además, con esta estrategia, no necesitamos hacer suposiciones adicionales sobre las relaciones entre los datos.
Si los datos faltantes provienen principalmente de una variable, podemos considerar omitir esta variable. Aquí, la motivación es que perdemos menos información al omitir esta variable en comparación con retener la variable pero perder las observaciones asociadas con los datos faltantes.
Otra estrategia es completar, o imputar, los datos faltantes. Hay muchas variaciones de la estrategia de imputación. Todas asumen algún tipo de relaciones entre las variables además de las suposiciones del modelo de regresión. Aunque estos métodos producen resultados razonables, hay que tener en cuenta que cualquier tipo de valores imputados no presenta la misma variabilidad inherente que los datos reales. Así, los resultados de los análisis basados en valores imputados a menudo reflejan menos variabilidad que aquellos con datos reales.
Ejemplo: Gastos de Compañías de Seguros - Continuación. Al examinar la información financiera de las compañías, los analistas a menudo se ven obligados a omitir una cantidad considerable de información al utilizar modelos de regresión para buscar relaciones. Para ilustrar, Segal (2002) examinó los estados financieros de seguros de vida a partir de datos proporcionados por la Asociación Nacional de Comisionados de Seguros (NAIC). Inicialmente, consideró 733 observaciones de empresas-año durante el período 1995-1998. Sin embargo, 154 observaciones fueron excluidas debido a primas, beneficios y otras variables explicativas inconsistentes o negativas. También se excluyeron las pequeñas empresas que representaban 131 observaciones. Las pequeñas empresas consisten en menos de 10 empleados y agentes, costos operativos menores a $1 millón o menos de 1,000 pólizas de vida vendidas. La muestra resultante fue de \(n=448\) observaciones. Las restricciones de muestra se basaron en variables explicativas; este procedimiento no necesariamente sesga los resultados. Segal argumentó que su muestra final seguía siendo representativa de la población de interés. Hubo alrededor de 110 empresas en cada uno de los años 1995-1998. En 1998, los activos agregados de las empresas en la muestra representaban aproximadamente $650 mil millones, un tercio de la industria de seguros de vida.
6.4 Modelos de Datos Faltantes
Para entender los mecanismos que conducen a respuestas no planificadas, los modelamos de manera estocástica. Sea \(r_i\) una variable binaria para la \(i\)-ésima observación, con un uno indicando que esta respuesta se observa y un cero indicando que la respuesta está faltante. Sea \(\mathbf{r} = (r_1, \ldots, r_n)^{\prime}\) que resume la disponibilidad de datos para todos los sujetos. El interés radica en si las respuestas influyen en el mecanismo de datos faltantes. Para la notación, usamos \(\mathbf{Y} = (y_1, \ldots, y_n)^{\prime}\) para ser la colección de todas las respuestas potencialmente observadas.
6.4.1 Faltante al Azar
En el caso en que \(\mathbf{Y}\) no afecta la distribución de \(\mathbf{r}\), seguimos a Rubin (1976) y llamamos a este caso faltante completamente al azar (MCAR). Específicamente, los datos faltantes son MCAR si \(\mathrm{f}(\mathbf{r} | \mathbf{Y}) = \mathrm{f}(\mathbf{r})\), donde f(.) es una función genérica de masa de probabilidad. Una extensión de esta idea se encuentra en Little (1995), donde se añade el adjetivo “dependiente de covariables” cuando \(\mathbf{Y}\) no afecta la distribución de \(\mathbf{r}\), condicionado a las covariables. Si las covariables se resumen como \(\mathbf{X}\), entonces la condición corresponde a la relación \(\mathrm{f}(\mathbf{r} | \mathbf{Y, X}) = \mathrm{f}(\mathbf{r | X})\). Para ilustrar este punto, considere un ejemplo de Little y Rubin (1987) donde \(\mathbf{X}\) corresponde a la edad y \(\mathbf{Y}\) corresponde a los ingresos de todas las observaciones potenciales. Si la probabilidad de estar faltante no depende de los ingresos, entonces los datos faltantes son MCAR. Si la probabilidad de estar faltante varía según la edad pero no por ingresos entre las observaciones dentro de un grupo de edad, entonces los datos faltantes son MCAR dependientes de covariables. Bajo esta última especificación, es posible que los datos faltantes varíen según los ingresos. Por ejemplo, las personas más jóvenes pueden ser menos propensas a responder una encuesta. Esto muestra que la característica “faltante al azar” depende del propósito del análisis. Específicamente, es posible que un análisis de los efectos conjuntos de edad e ingresos pueda encontrar patrones graves de datos faltantes, mientras que un análisis de ingresos controlado por edad no sufre patrones graves de sesgo.
Little y Rubin (1987) abogan por modelar los mecanismos de datos faltantes. Para ilustrar, considere un enfoque de máxima verosimilitud utilizando un modelo de selección para el mecanismo de datos faltantes. Ahora, particione \(\mathbf{Y}\) en componentes observados y faltantes utilizando la notación \(\mathbf{Y} =\{\mathbf{Y}_{obs}, \mathbf{Y}_{miss}\}\). Con el enfoque de máxima verosimilitud, basamos la inferencia en las variables aleatorias observadas. Por lo tanto, usamos una verosimilitud proporcional a la función conjunta \(\mathrm{f}(\mathbf{r}, \mathbf{Y}_{obs})\). También especificamos un modelo de selección especificando la función de masa condicional \(\mathrm{f}(\mathbf{r} | \mathbf{Y})\).
Supongamos que las respuestas observadas y las distribuciones del modelo de selección se caracterizan por vectores de parámetros \(\boldsymbol \theta\) y \(\boldsymbol \psi\), respectivamente. Entonces, con la relación \(\mathrm{f}(\mathbf{r}, \mathbf{Y}_{obs},\boldsymbol \theta, \boldsymbol \psi) = \mathrm{f}(\mathbf{Y}_{obs}, \boldsymbol \theta) \times \mathrm{f}(\mathbf{r} | \mathbf{Y}_{obs}, \boldsymbol \psi)\), podemos expresar la verosimilitud logarítmica de las variables aleatorias observadas como
\[ L(\boldsymbol \theta, \boldsymbol \psi) = \mathrm{ln~} \mathrm{f}(\mathbf{r}, \mathbf{Y}_{obs}, \boldsymbol \theta, \boldsymbol \psi) = \mathrm{ln~} \mathrm{f}(\mathbf{Y}_{obs}, \boldsymbol \theta) + \mathrm{ln~} \mathrm{f}(\mathbf{r} | \mathbf{Y}_{obs}, \boldsymbol \psi). \] (Véase la Sección 11.9 si desea un repaso sobre la inferencia de verosimilitud). En el caso en que los datos son MCAR, entonces \(\mathrm{f}(\mathbf{r} | \mathbf{Y}_{obs}, \boldsymbol \psi) = \mathrm{f}(\mathbf{r} | \boldsymbol \psi)\) no depende de \(\mathbf{Y}_{obs}\). Little y Rubin (1987) también consideran el caso en que la distribución del modelo del mecanismo de selección no depende de \(\mathbf{Y}_{miss}\) pero puede depender de \(\mathbf{Y}_{obs}\). En este caso, lo llaman datos faltantes al azar (MAR).
En los casos tanto de MAR como de MCAR, vemos que la verosimilitud puede maximizarse sobre los parámetros, por separado para cada caso. En particular, si uno está interesado únicamente en el estimador de máxima verosimilitud de \(\boldsymbol \theta\), entonces el mecanismo del modelo de selección puede ser “ignorado”. Por lo tanto, ambas situaciones a menudo se denominan caso ignorables.
Ejemplo: Gastos Dentales. Sea \(y\) el gasto anual en dentista de un hogar y \(x\) el ingreso. Considere los siguientes cinco mecanismos de selección.
- El hogar no es seleccionado (faltante) con una probabilidad sin tener en cuenta el nivel de gasto dental. En este caso, el mecanismo de selección es MCAR.
- El hogar no es seleccionado si el gasto dental es menor a $100. En este caso, el mecanismo de selección depende de la respuesta observada y faltante. El mecanismo de selección no puede ser ignorado.
- El hogar no es seleccionado si el ingreso es menor a $20,000. En este caso, el mecanismo de selección es MCAR, dependiente de covariables. Es decir, suponiendo que el propósito del análisis es entender los gastos dentales condicionado al conocimiento del ingreso, estratificar según el ingreso no sesga gravemente el análisis.
- La probabilidad de que un hogar sea seleccionado aumenta con el gasto dental. Por ejemplo, supongamos que la probabilidad de ser seleccionado es una función lineal de \(\exp(\psi y_i)/(1+ \exp(\psi y_i))\). En este caso, el mecanismo de selección depende de la respuesta observada y faltante. El mecanismo de selección no puede ser ignorado.
- El hogar es seguido durante \(T\) = 2 períodos. En el segundo período, un hogar no es seleccionado si el gasto del primer período es menor a $100. En este caso, el mecanismo de selección es MAR. Es decir, el mecanismo de selección se basa en una respuesta observada.
Los segundos y cuartos mecanismos de selección representan situaciones donde el mecanismo de selección debe ser modelado explícitamente; estos son casos no ignorables. En estas situaciones, sin ajustes explícitos, los procedimientos que ignoran el efecto de selección pueden producir resultados gravemente sesgados. Para ilustrar una corrección para el sesgo de selección en un caso simple, presentamos un ejemplo de Little y Rubin (1987). La Sección 6.4.2 describe mecanismos adicionales.
Ejemplo: Alturas Históricas. Little y Rubin (1987) discuten datos de Wachter y Trusell (1982) sobre \(y\), la altura de hombres reclutados para servir en el ejército. La muestra está sujeta a censura en el sentido de que se impusieron estándares mínimos de altura para la admisión en el ejército. Así, el mecanismo de selección es
\[ r_i = \left\{ \begin{array}{ll} 1 & y_i > c_i \\ 0 & \mathrm{de lo contrario} \\ \end{array} \right. , \] donde \(c_i\) es el estándar mínimo de altura conocido impuesto en el momento del reclutamiento. El mecanismo de selección es no ignorables porque depende de la altura del individuo, \(y\).
Para este ejemplo, se dispone de información adicional para proporcionar inferencia de modelos confiables. Específicamente, basándonos en otros estudios de alturas masculinas, podemos suponer que la población de alturas sigue una distribución normal. Así, la verosimilitud de las observaciones puede escribirse y la inferencia puede proceder directamente. Para ilustrar, supongamos que \(c_i = c\) es constante. Sean \(\mu\) y \(\sigma\) la media y la desviación estándar de \(y\). Supongamos además que tenemos una muestra aleatoria de \(n + m\) hombres en la que \(m\) hombres están por debajo del estándar mínimo de altura \(c\) y observamos \(\mathbf{Y}_{obs} = (y_1, \ldots, y_n)^{\prime}\). La distribución conjunta para los observables es
\[\begin{eqnarray*} \mathrm{f}(\mathbf{r}, \mathbf{Y}_{obs}, \mu, \sigma) &=& \mathrm{f}(\mathbf{Y}_{obs}, \mu, \sigma) \times \mathrm{f}(\mathbf{r} | \mathbf{Y}_{obs}) \\ &=& \left\{ \prod_{i=1}^n \mathrm{f}(y_i | y_i > c) \times \mathrm{Pr}(y_i > c) \right\} \times \left\{\mathrm{Pr}(y_i \leq c)\right\}^m. \end{eqnarray*}\] Ahora, sean \(\phi\) y \(\Phi\) la densidad y la función de distribución para la distribución normal estándar. Así, la verosimilitud logarítmica es \[\begin{eqnarray*} L(\mu, \sigma) &=& \mathrm{ln~} \mathrm{f}(\mathbf{r}, \mathbf{Y}_{obs}, \mu, \sigma) \\ &=& \sum_{i=1}^n \mathrm{ln}\left\{ \frac{1}{\sigma} \phi \left( \frac{y_i-\mu}{\sigma} \right) \right\} + m~ \mathrm{ln}\left\{ \Phi \left( \frac{c-\mu}{\sigma}\right) \right\} . \end{eqnarray*}\] Esto es fácil de maximizar en \(\mu\) y \(\sigma\). Si se ignoraran los mecanismos de censura, entonces se derivarían estimaciones de los datos observados a partir de la “verosimilitud logarítmica,” \[ \sum_{i=1}^n \mathrm{ln}\left\{ \frac{1}{\sigma} \phi \left( \frac{y_i-\mu}{\sigma} \right) \right\}, \] lo que daría resultados diferentes y sesgados.
6.4.2 Datos Faltantes No Ignorables
Para los datos faltantes no ignorables, Little (1995) recomienda:
- Evitar respuestas faltantes siempre que sea posible utilizando procedimientos de seguimiento adecuados.
- Recoger covariables que sean útiles para predecir los valores faltantes.
- Recoger la mayor cantidad de información posible sobre la naturaleza del mecanismo de datos faltantes.
Para el último punto, si se sabe poco sobre el mecanismo de datos faltantes, es difícil emplear un procedimiento estadístico robusto para corregir el sesgo de selección.
Existen muchos modelos de mecanismos de datos faltantes. Una visión general aparece en Little y Rubin (1987). Little (1995) examina el problema de la deserción. En lugar de revisar esta literatura en desarrollo, presentamos un modelo ampliamente utilizado para datos faltantes no ignorables.
Procedimiento de Dos Etapas de Heckman
Heckman (1976) asume que el mecanismo de respuesta de muestreo está gobernado por la variable latente (no observada) \(r_i^{\ast}\) donde \[ r_i^{\ast} = \mathbf{z}_i^{\prime} \boldsymbol \gamma + \eta_i. \] Las variables en \(\mathbf{z}_i\) pueden o no incluir las variables en \(\mathbf{x}_i\). Observamos \(y_i\) si \(r_i^{\ast}>0\), es decir, si \(r_i^{\ast}\) cruza el umbral 0. Así, observamos \[ r_i = \left\{ \begin{array}{ll} 1 & r_i^{\ast}>0 \\ 0 & \mathrm{de lo contrario} \\ \end{array} \right. . \] Para completar la especificación, asumimos que {(\(\varepsilon_i,\eta_i\))} son distribuidos idénticamente e independientemente, y que la distribución conjunta de {(\(\varepsilon_i,\eta_i\))} es bivariada normal con medias cero, varianzas \(\sigma^2\) y \(\sigma_{\eta}^2\), y correlación \(\rho\). Note que si el parámetro de correlación \(\rho\) es igual a cero, entonces los modelos de respuesta y selección son independientes. En este caso, los datos son MCAR y los procedimientos de estimación habituales son no sesgados y asintóticamente eficientes.
Bajo estas suposiciones, cálculos básicos de la normal multivariada muestran que \[ \mathrm{E~}(y_i | r_i^{\ast}>0) = \mathbf{x}_i^{\prime} \boldsymbol \beta + \beta_{\lambda} \lambda(\mathbf{z}_i^{\prime} \boldsymbol \gamma), \] donde \(\beta_{\lambda} = \rho \sigma\) y \(\lambda(a)=\phi(a)/\Phi(a)\). Aquí, \(\lambda(.)\) es la inversa de la llamada “razón de Mills.” Este cálculo sugiere el siguiente procedimiento en dos etapas para estimar los parámetros de interés.
Procedimiento de Dos Etapas de Heckman
- Utilice los datos {(\(r_i, \mathbf{z}_i\))} y un modelo de regresión probit para estimar \(\boldsymbol \gamma\). Llame a este estimador \(\mathbf{g}_H\).
- Utilice el estimador de la etapa (1) para crear una nueva variable explicativa, \(x_{i,K+1} = \lambda(\mathbf{z}_i^{\prime}\mathbf{g}_H)\). Realice un modelo de regresión utilizando las \(K\) variables explicativas \(\mathbf{x}_i\), así como la variable explicativa adicional \(x_{i,K+1}\). Use \(\mathbf{b}_H\) y \(b_{\lambda,H}\) para denotar los estimadores de \(\boldsymbol \beta\) y \(\beta_{\lambda}\), respectivamente.
El Capítulo 11 introducirá las regresiones probit. También observamos que el método de dos etapas no funciona en ausencia de covariables para predecir la respuesta y, para fines prácticos, requiere variables en \(\mathbf{z}\) que no están en \(\mathbf{x}\) (ver Little y Rubin, 1987).
Para probar el sesgo de selección, podemos probar la hipótesis nula \(H_0:\beta_{\lambda}=0\) en la segunda etapa debido a la relación \(\beta_{\lambda}= \rho \sigma\). Al realizar esta prueba, se deben usar errores estándar corregidos por heterocedasticidad. Esto se debe a que la varianza condicional \(\mathrm{Var}(y_i | r_i^{\ast}>0)\) depende de la observación \(i\). Específicamente, \(\mathrm{Var}(y_i | r_i^{\ast}>0) = \sigma^2 (1-\rho^2 \delta_i),\) donde \(\delta_i= \lambda_i(\lambda_i + \mathbf{z}_i^{\prime} \boldsymbol \gamma)\) y \(\lambda_i = \phi(\mathbf{z}_i^{\prime} \boldsymbol \gamma)/\Phi(\mathbf{z}_i^{\prime} \boldsymbol \gamma).\)
Este procedimiento asume normalidad para las variables latentes de selección para formar las variables aumentadas. Existen otras formas de distribución en la literatura, incluyendo las distribuciones logística y uniforme. Una crítica más profunda, planteada por Little (1985), es que el procedimiento se basa en suposiciones que no se pueden probar utilizando los datos disponibles. Esta crítica es análoga al ejemplo de alturas históricas donde nos basamos en gran medida en la curva normal para inferir la distribución de alturas por debajo del punto de censura. A pesar de estas críticas, el procedimiento de Heckman se usa ampliamente en las ciencias sociales.
Algoritmo EM
La Sección 6.4.2 se ha centrado en introducir modelos específicos de no respuesta no ignorables. Los modelos generales robustos de no respuesta no están disponibles. En cambio, una estrategia más apropiada es centrarse en una situación específica, recoger la mayor cantidad de información posible sobre la naturaleza del problema de selección y luego desarrollar un modelo para este problema de selección específico.
El algoritmo EM es un dispositivo computacional para calcular los parámetros del modelo. Aunque es específico para cada modelo, ha encontrado aplicaciones en una amplia variedad de modelos que involucran datos faltantes. Computacionalmente, el algoritmo itera entre los pasos de “E”, para la expectativa condicional, y “M”, para la maximización. El paso E encuentra la expectativa condicional de los datos faltantes dado los datos observados y los valores actuales de los parámetros estimados. Esto es análogo a la tradición de imputar datos faltantes. Una innovación clave del algoritmo EM es que se imputan estadísticas suficientes para los valores faltantes, no los puntos de datos individuales. Para el paso M, se actualizan las estimaciones de los parámetros maximizando una log-verosimilitud observada. Tanto las estadísticas suficientes como la log-verosimilitud dependen de la especificación del modelo.
Existen muchas introducciones al algoritmo EM en la literatura. Little y Rubin (1987) proporcionan un tratamiento detallado.
6.5 Aplicación: Eficiencia en el Costo de los Gestores de Riesgos
Esta sección examina datos de una encuesta sobre la eficiencia en el costo de las prácticas de gestión de riesgos. Las prácticas de gestión de riesgos son actividades llevadas a cabo por una empresa para minimizar el costo potencial de futuras pérdidas, como el evento de un incendio en un almacén o un accidente que lesione a los empleados. Esta sección desarrolla un modelo que se puede utilizar para hacer afirmaciones sobre el costo de la gestión de riesgos.
Un esquema del proceso de modelado de regresión es el siguiente. Comenzamos proporcionando una introducción al problema y dando un breve contexto sobre los datos. Ciertas teorías previas nos llevarán a presentar un ajuste preliminar del modelo. Usando técnicas diagnósticas, será evidente que varias suposiciones que sustentan este modelo no están en acuerdo con los datos. Esto nos llevará a volver al principio y comenzar el análisis desde cero. Lo que aprendemos de un examen detallado de los datos nos llevará a postular algunos modelos revisados. Finalmente, para comunicar ciertos aspectos del nuevo modelo, exploraremos presentaciones gráficas del modelo recomendado.
Introducción
Los datos para este estudio fueron proporcionados por la Profesora Joan Schmit y se discuten en más detalle en el artículo “Cost effectiveness of risk management practices,” Schmit y Roth (1990). Los datos provienen de un cuestionario enviado a 374 gestores de riesgos de grandes organizaciones con sede en EE. UU. El propósito del estudio fue relacionar la eficacia en costos con la filosofía de gestión de controlar la exposición de la empresa a diversas pérdidas por propiedad y accidentes, después de ajustar por efectos de la empresa como el tamaño y el tipo de industria.
Primero, algunas advertencias. Los datos de encuestas a menudo se basan en muestras de conveniencia, no en muestras probabilísticas. Al igual que con todos los conjuntos de datos observacionales, la metodología de regresión es una herramienta útil para resumir los datos. Sin embargo, debemos ser cautelosos al hacer inferencias basadas en este tipo de conjunto de datos. Para esta encuesta en particular, 162 gestores devolvieron encuestas completas, resultando en una buena tasa de respuesta del \(43\%\). Sin embargo, para las variables incluidas en el análisis (definidas más adelante), solo se completaron 73 formularios, resultando en una tasa de respuesta completa del \(20\%\). ¿Por qué una diferencia tan dramática? Los gestores, al igual que la mayoría de las personas, generalmente no tienen problemas en responder a consultas sobre sus actitudes u opiniones acerca de diversos temas. Cuando se les pregunta sobre hechos concretos, en este caso el tamaño de los activos de la empresa o las primas de seguros, o bien consideran que la información es confidencial y son reacios a responder incluso cuando se les garantiza anonimato, o simplemente no están dispuestos a tomarse el tiempo para buscar la información. Desde el punto de vista del encuestador, esto es desafortunado porque, por lo general, los datos “actitudinales” son imprecisos (alta varianza en comparación con la media) en comparación con los datos financieros concretos. El inconveniente es que estos últimos datos a menudo son difíciles de obtener. De hecho, para esta encuesta, se enviaron varios cuestionarios previos para determinar la disposición de los gestores a responder preguntas específicas. A partir de los cuestionarios previos, los investigadores redujeron drásticamente el número de preguntas financieras que planeaban hacer.
Una medida de la eficacia en el costo de la gestión de riesgos, FIRMCOST, es la variable dependiente. Esta variable se define como las primas totales por propiedad y accidentes y las pérdidas no aseguradas como un porcentaje de los activos totales. Es un proxy para los gastos anuales asociados con eventos asegurables, estandarizados por el tamaño de la empresa. Aquí, para las variables financieras, ASSUME es el monto de retención por ocurrencia como porcentaje de los activos totales, CAP indica si la empresa posee una compañía de seguros cautiva, SIZELOG es el logaritmo de los activos totales e INDCOST es una medida del riesgo de la industria de la empresa. Las variables actitudinales incluyen CENTRAL, una medida de la importancia de los gestores locales en la elección de la cantidad de riesgo a retener, y SOPH, una medida del grado de importancia en el uso de herramientas analíticas, como la regresión, en la toma de decisiones de gestión de riesgos.
En el artículo, los investigadores describieron varias debilidades de las definiciones utilizadas, pero argumentan que estas definiciones proporcionan información útil, basada en la disposición de los gestores de riesgos a obtener información confiable. Los investigadores también describieron varias teorías sobre relaciones que podrían ser confirmadas por los datos. Específicamente, hipotetizaron:
- Existe una relación inversa entre la retención de riesgo (ASSUME) y el costo (FIRMCOST). La idea detrás de esta teoría es que mayores montos de retención deberían significar menores gastos para una empresa, resultando en menores costos.
- El uso de una compañía de seguros cautiva (CAP) resulta en menores costos. Presumiblemente, una cautiva se usa solo cuando es costo-efectiva y, en consecuencia, esta variable debería indicar menores costos si se utiliza efectivamente.
- Existe una relación inversa entre la medida de centralización (CENTRAL) y el costo (FIRMCOST). Presumiblemente, los gestores locales podrían tomar decisiones más costo-efectivas porque están más familiarizados con las circunstancias locales relacionadas con la gestión de riesgos que los gestores ubicados centralmente.
- Existe una relación inversa entre la medida de sofisticación (SOPH) y el costo (FIRMCOST). Presumiblemente, herramientas analíticas más sofisticadas ayudan a las empresas a gestionar el riesgo de manera más eficaz, resultando en menores costos.
Análisis Preliminar
Para probar las teorías descritas anteriormente, se puede utilizar el marco de análisis de regresión. Para ello, se plantea el modelo
\[ \small{ \begin{array}{ll} \text{FIRMCOST} &=&\beta_0 +\beta_1 \text{ ASSUME}+\beta_{2}\text{ CAP} +\beta_{3}\text{ SIZELOG}+\beta_4\text{ INDCOST} \\ &&+\beta_5\text{ CENTRAL}+\beta_6\text{ SOPH}+ \varepsilon. \end{array} } \]
Con este modelo, cada teoría se puede interpretar en términos de los coeficientes de regresión. Por ejemplo, \(\beta_1\) se puede interpretar como el cambio esperado en el costo por unidad de cambio en el nivel de retención (ASSUME). Así, si la primera hipótesis es verdadera, esperamos que \(\beta_1\) sea negativo. Para probar esto, podemos estimar \(b_{1}\) y usar nuestras pruebas de hipótesis para decidir si \(b_{1}\) es significativamente menor que cero. Las variables SIZELOG e INDCOST se incluyen en el modelo para controlar los efectos de estas variables. Estas variables no están directamente bajo el control del gestor de riesgos y, por lo tanto, no son de interés principal. Sin embargo, la inclusión de estas variables puede explicar una parte importante de la variabilidad.
Los datos de 73 gestores fueron ajustados utilizando este modelo de regresión. La Tabla 6.2 resume el modelo ajustado.
| Coeficiente | Error Estándar | \(t\)-Estadístico | |
|---|---|---|---|
| (Intercept) | 59.765 | 19.065 | 3.135 |
| ASSUME | -0.300 | 0.222 | -1.353 |
| CAP | 5.498 | 3.848 | 1.429 |
| SIZELOG | -6.836 | 1.923 | -3.555 |
| INDCOST | 23.078 | 8.304 | 2.779 |
| CENTRAL | 0.133 | 1.441 | 0.092 |
| SOPH | -0.137 | 0.347 | -0.394 |
El coeficiente de determinación ajustado es \(R_{a}^{2}=18.8\%\), el ratio \(F\) es 3.78 y la desviación estándar residual es \(s=14.56\).
Con base en las estadísticas resumidas del modelo de regresión, podemos concluir que las medidas de centralización y sofisticación no tienen un impacto en nuestra medida de eficacia en costos. Para ambas variables, el ratio \(t\) es bajo, menos de 1.0 en valor absoluto. El efecto de la retención de riesgo parece ser solo algo importante. El coeficiente tiene el signo apropiado, aunque está solo 1.35 errores estándar por debajo de cero. Esto no se consideraría estadísticamente significativo al nivel del 5%, aunque sí al nivel del 10% (el valor \(p\) es 9%). Quizás lo más desconcertante es el coeficiente asociado con la variable CAP. Teorizamos que este coeficiente sería negativo. Sin embargo, en nuestro análisis de los datos, el coeficiente resulta ser positivo y está 1.43 errores estándar por encima de cero. Esto no solo nos lleva a desmentir nuestra teoría, sino también a buscar nuevas ideas que estén en concordancia con la información aprendida de los datos. Schmit y Roth sugieren razones que pueden ayudarnos a interpretar los resultados de nuestras pruebas de hipótesis. Por ejemplo, sugieren que los gestores en la muestra pueden no tener las herramientas más sofisticadas disponibles cuando gestionan riesgos, lo que resulta en un coeficiente no significativo asociado con SOPH. También discutieron sugerencias alternativas, así como interpretaciones para los otros resultados de las pruebas de hipótesis.
¿Qué tan robusto es este modelo? La Sección 6.2 enfatizó algunos de los peligros de trabajar con un modelo inadecuado. Algunos lectores pueden sentirse incómodos con el modelo seleccionado anteriormente porque dos de las seis variables tienen \(t\)-ratios menores a 1 en valor absoluto y cuatro de las seis tienen \(t\)-ratios menores a 1.5 en valor absoluto. Quizás aún más importante, los histogramas de los residuos estandarizados y las palancas, en la Figura 6.5, muestran que varias observaciones son puntos atípicos y de alta influencia. Para ilustrar, el residuo más grande resulta ser \(e_{15}=83.73\). La suma de cuadrados del error es \(Error~SS\) = \((n-(k+1))s^{2}\) = \((73-7)(14.56)^{2}=13,987\). Así, la 15ª observación representa el 50.1% de la suma de cuadrados del error \((=83.73^{2}/13,987)\), sugiriendo que esta única observación de las 73 tiene un impacto dominante en el ajuste del modelo. Además, los gráficos de residuos estandarizados versus valores ajustados, no presentados aquí, mostraron evidencia de residuos heterocedásticos. Con base en estas observaciones, parece razonable evaluar la robustez del modelo.
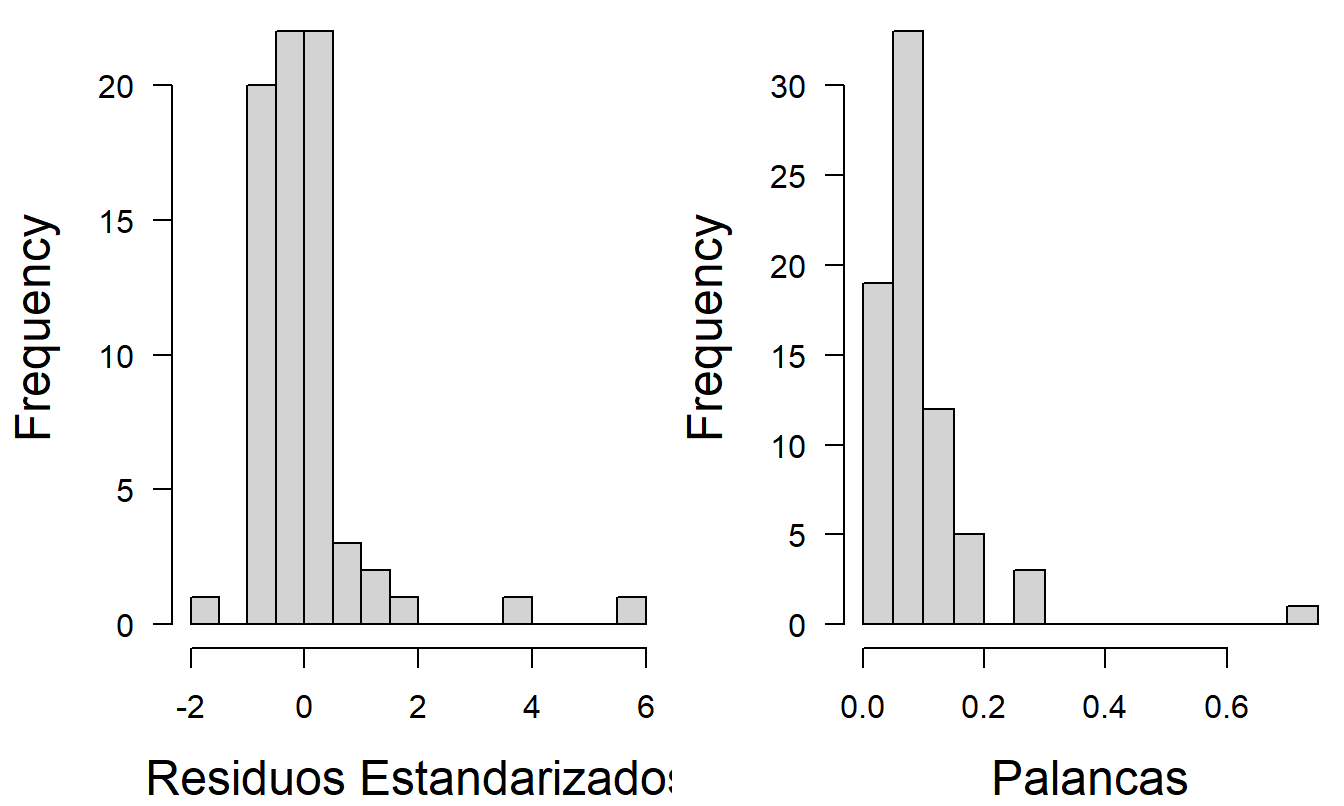
Figura 6.5: Histogramas de residuos estandarizados y palancas del ajuste preliminar del modelo de regresión.
Código R para producir la Tabla 6.2 y la Figura 6.5
Volviendo a lo Básico
Para entender mejor los datos, comenzamos examinando las estadísticas resumen básicas en la Tabla 6.3 y los histogramas correspondientes en la Figura 6.6. En la Tabla 6.3, el valor más alto de FIRMCOST es 97.55, que está más de cinco desviaciones estándar por encima de la media \([10.97+5(16.16)=91.77]\). Un examen de los datos muestra que este punto es la observación 15, la misma observación que fue un punto atípico en el ajuste preliminar de la regresión. Sin embargo, el histograma de FIRMCOST en la Figura 6.6 revela que este no es el único punto inusual. Otras dos observaciones tienen valores inusualmente altos de FIRMCOST, resultando en una distribución sesgada hacia la derecha. El histograma, en la Figura 6.6, de la variable ASSUME muestra que esta distribución también está sesgada hacia la derecha, posiblemente debido únicamente a dos grandes observaciones. De las estadísticas resumen básicas en la Tabla 6.3, vemos que el valor más alto de ASSUME está más de siete desviaciones estándar por encima de la media. Esta observación podría resultar influyente en el ajuste posterior del modelo de regresión. El diagrama de dispersión de FIRMCOST versus ASSUME en la Figura 6.6 nos dice que la observación con el valor más alto de FIRMCOST no es la misma que la observación con el valor más alto de ASSUME.
| Media | Mediana | Desviación Estándar | Mínimo | Máximo | |
|---|---|---|---|---|---|
| FIRMCOST | 10.973 | 6.08 | 16.159 | 0.20 | 97.55 |
| ASSUME | 2.574 | 0.51 | 8.445 | 0.00 | 61.82 |
| CAP | 0.342 | 0.00 | 0.478 | 0.00 | 1.00 |
| SIZELOG | 8.332 | 8.27 | 0.963 | 5.27 | 10.60 |
| INDCOST | 0.418 | 0.34 | 0.216 | 0.09 | 1.22 |
| CENTRAL | 2.247 | 2.00 | 1.256 | 1.00 | 5.00 |
| SOPH | 21.192 | 23.00 | 5.304 | 5.00 | 31.00 |
Fuente: Schmit y Roth, (1990)
A partir de los histogramas de SIZELOG, INDCOST, CENTRAL y SOPH, vemos que estas distribuciones no están fuertemente sesgadas. Tomar logaritmos del tamaño de los activos totales de la empresa ha servido para hacer la distribución más simétrica que en las unidades originales. A partir del histograma y las estadísticas resumen, vemos que CENTRAL es una variable discreta, que toma valores del uno al cinco. La otra variable discreta es CAP, una variable binaria que toma solo valores cero y uno. El histograma y el gráfico de dispersión correspondiente a CAP no se presentan aquí. Es más informativo proporcionar una tabla de medias de cada variable por niveles de CAP, como en la Tabla 6.4. A partir de esta tabla, vemos que 25 de las 73 empresas encuestadas tienen aseguradoras cautivas. Además, por un lado, el FIRMCOST promedio para las empresas con aseguradoras cautivas \((CAP = 1)\) es mayor que para las que no tienen \((CAP = 0)\). Por otro lado, al pasar a la escala logarítmica, sucede lo contrario; es decir, el COSTLOG promedio para las empresas con aseguradoras cautivas \((CAP = 1)\) es mayor que para las que no tienen \((CAP = 0)\).
| \(n\) | FIRMCOST | ASSUME | SIZELOG | INDCOST | CENTRAL | SOPH | COSTLOG | |
|---|---|---|---|---|---|---|---|---|
| CAP = 0 | 48 | 9.954 | 1.175 | 8.196 | 0.399 | 2.250 | 21.521 | 1.820 |
| CAP = 1 | 25 | 12.931 | 5.258 | 8.592 | 0.455 | 2.240 | 20.560 | 1.595 |
| TOTAL | 73 | 10.973 | 2.574 | 8.332 | 0.418 | 2.247 | 21.192 | 1.743 |
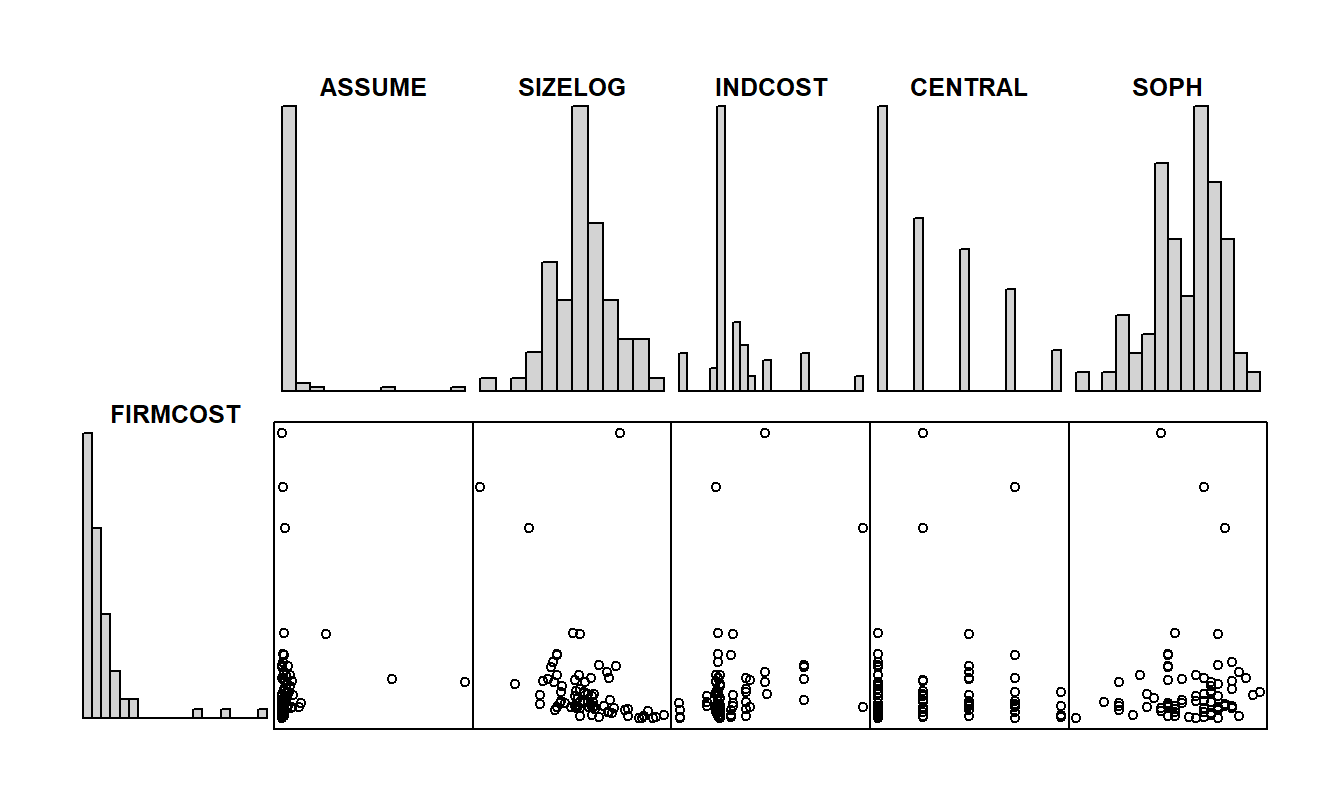
Figura 6.6: Histogramas y gráficos de dispersión de FIRMCOST y varias variables explicativas. Las distribuciones de FIRMCOST y ASSUME están fuertemente sesgadas hacia la derecha. Hay una relación negativa entre FIRMCOST y SIZELOG, aunque no lineal.
Código R para producir las Tablas 6.3 y 6.4 y la Figura 6.6
Al examinar las relaciones entre pares de variables, en la Figura 6.6 observamos algunas de las relaciones que fueron evidentes en el ajuste preliminar de la regresión. Hay una relación inversa entre FIRMCOST y SIZELOG, y el gráfico de dispersión sugiere que esta relación podría ser no lineal. También hay una relación positiva leve entre FIRMCOST e INDCOST y no se observan relaciones aparentes entre FIRMCOST y ninguna de las otras variables explicativas. Estas observaciones se refuerzan con la tabla de correlaciones dada en la Tabla 6.4. Nota que la tabla oculta una característica que es evidente en los gráficos de dispersión: el efecto de las observaciones inusualmente grandes.
| COSTLOG | FIRMCOST | ASSUME | CAP | SIZELOG | INDCOST | CENTRAL | |
|---|---|---|---|---|---|---|---|
| FIRMCOST | 0.713 | ||||||
| ASSUME | 0.165 | 0.039 | |||||
| CAP | -0.088 | 0.088 | 0.231 | ||||
| SIZELOG | -0.637 | -0.366 | -0.209 | 0.196 | |||
| INDCOST | 0.395 | 0.326 | 0.249 | 0.122 | -0.102 | ||
| CENTRAL | -0.054 | 0.014 | -0.068 | -0.004 | -0.08 | -0.085 | |
| SOPH | 0.144 | 0.048 | 0.062 | -0.087 | -0.209 | 0.093 | 0.283 |
Debido al sesgo de la distribución y al efecto de las observaciones inusualmente grandes, una transformación de la variable de respuesta podría llevar a resultados más útiles. La Figura 6.7 muestra el histograma de COSTLOG, definido como el logaritmo de FIRMCOST. La distribución es mucho menos sesgada que la distribución de FIRMCOST. La variable COSTLOG también se incluyó en la matriz de correlaciones en la Tabla 6.4. A partir de esta tabla, la relación entre SIZELOG parece ser más fuerte con COSTLOG que con FIRMCOST. La Figura 6.8 muestra varios gráficos de dispersión que ilustran la relación entre COSTLOG y las variables explicativas. La relación entre COSTLOG y SIZELOG parece ser lineal. Es más fácil interpretar estos gráficos de dispersión que los de la Figura 6.6 debido a la ausencia de los grandes valores inusuales de la variable dependiente.
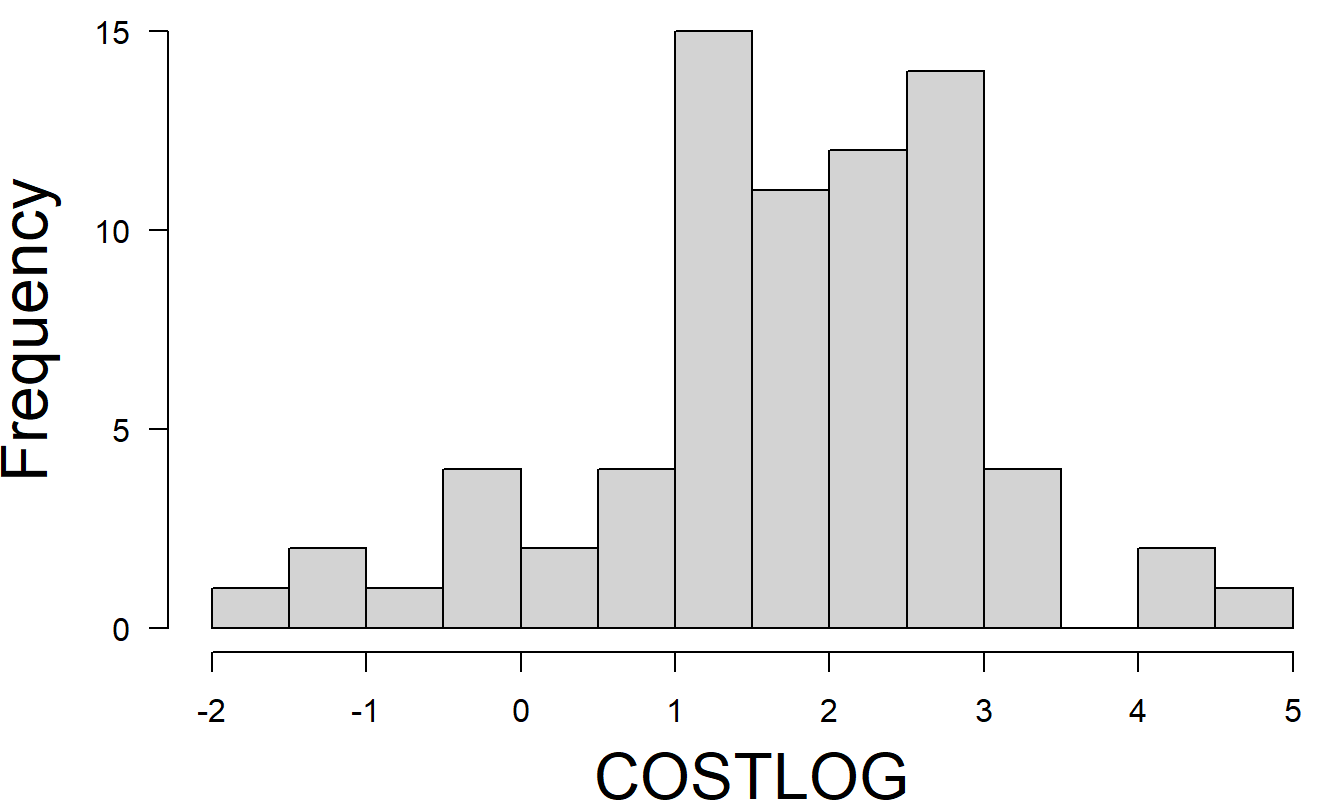
Figura 6.7: Histograma de COSTLOG (el logaritmo natural de FIRMCOST). La distribución de COSTLOG es menos sesgada que la de FIRMCOST.
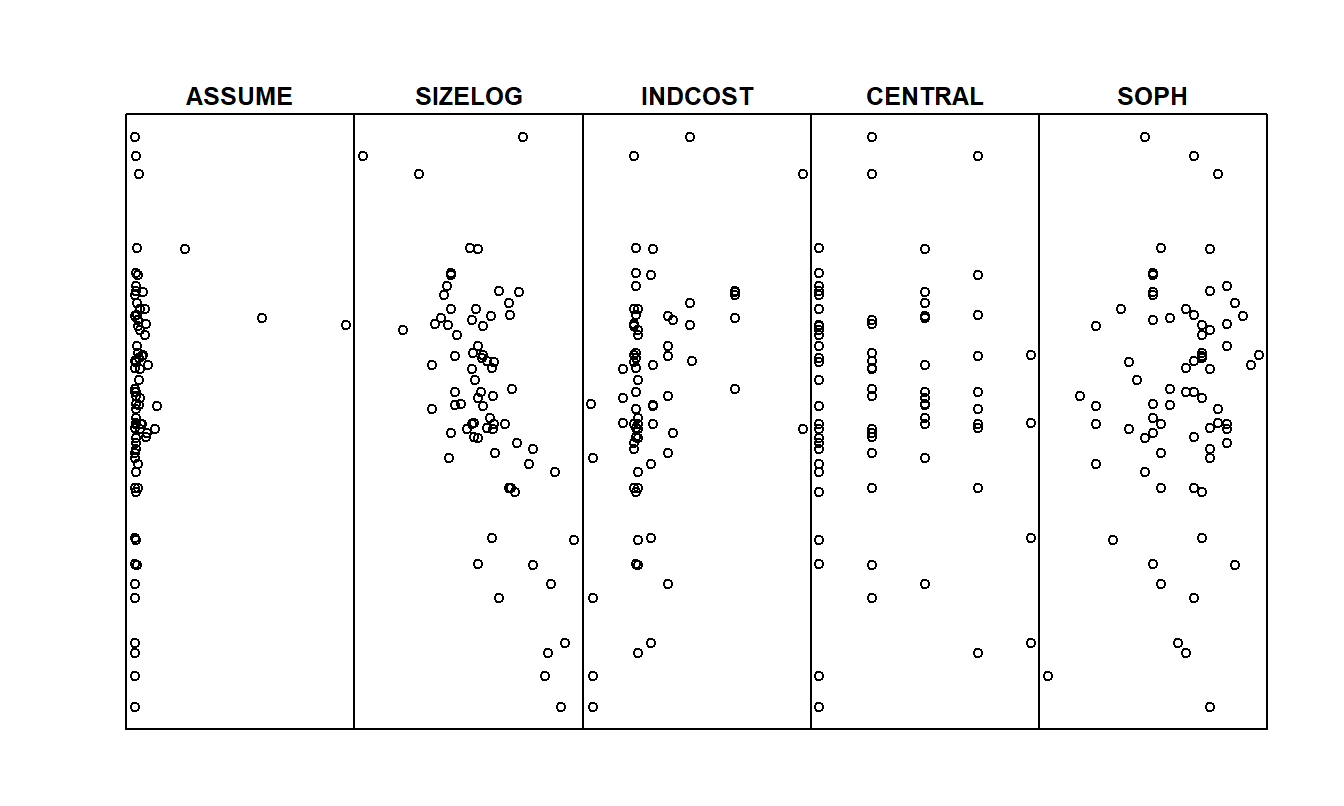
Figura 6.8: Gráficos de dispersión de COSTLOG versus varias variables explicativas. Hay una relación negativa entre COSTLOG y SIZELOG y una relación positiva leve entre COSTLOG e INDCOST.
Código R para producir la Tabla 6.5 y las Figuras 6.7 y 6.8
Algunos Modelos Nuevos
Ahora, exploramos el uso de COSTLOG como la variable dependiente. Este enfoque se basa en el trabajo de la subsección anterior y en los gráficos de residuos del ajuste preliminar de la regresión. Como primer paso, ajustamos un modelo con todas las variables explicativas. Por lo tanto, este modelo es el mismo que el ajuste preliminar de la regresión, excepto que usa COSTLOG en lugar de FIRMCOST como la variable dependiente. Este modelo sirve como un punto de referencia útil para nuestro trabajo posterior. La Tabla 6.6 resume el ajuste.
| Coeficiente | Error Estándar | \(t\)-Estadístico | |
|---|---|---|---|
| (Intercept) | 7.643 | 1.155 | 6.617 |
| ASSUME | -0.008 | 0.013 | -0.609 |
| CAP | 0.015 | 0.233 | 0.064 |
| SIZELOG | -0.787 | 0.116 | -6.752 |
| INDCOST | 1.905 | 0.503 | 3.787 |
| CENTRAL | -0.080 | 0.087 | -0.916 |
| SOPH | 0.002 | 0.021 | 0.116 |
Aquí, \(R_{a}^{2}=48\%\), \(F\)-ratio \(=12.1\) y \(s=0.882\). La Figura 6.9 muestra que la distribución de los residuos estandarizados es menos sesgada que la correspondiente en la Figura 6.5. La distribución de los apalancamientos muestra que todavía hay observaciones altamente influyentes. (De hecho, la distribución de los apalancamientos parece ser la misma que en la Figura 6.5. ¿Por qué?) Cuatro de las seis variables tienen \(t\)-ratios menores que uno en valor absoluto, lo que sugiere que debemos continuar buscando un mejor modelo.
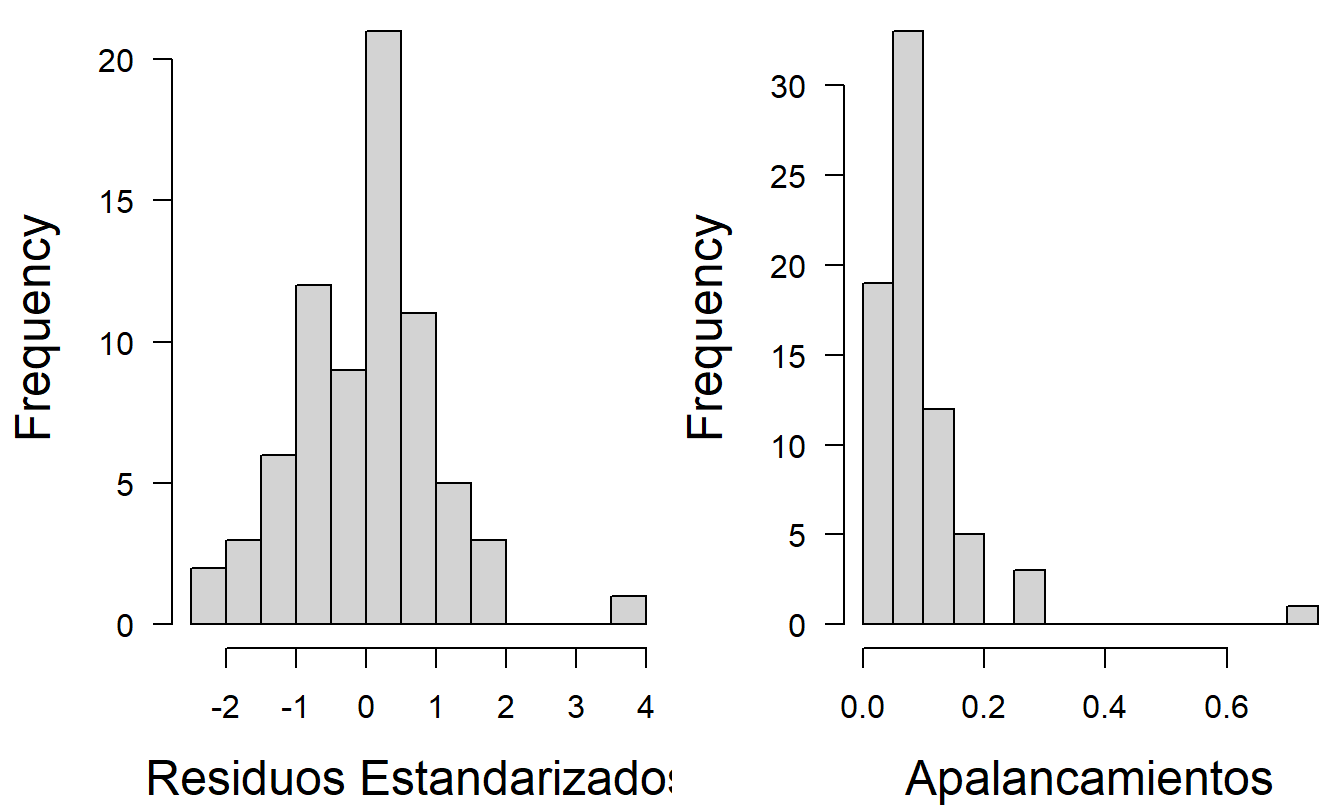
Figura 6.9: Histogramas de residuos estandarizados y apalancamientos utilizando COSTLOG como la variable dependiente.
Para continuar con la búsqueda, se realizó una regresión por pasos (aunque la salida no se reproduce aquí). La salida de esta técnica de búsqueda, así como el modelo de regresión ajustado arriba, sugiere usar las variables SIZELOG e INDCOST para explicar la variable dependiente COSTLOG.
Podemos realizar una regresión usando SIZELOG e INDCOST como variables explicativas. En la Figura 6.10, vemos que el tamaño y la forma de la distribución de los residuos estandarizados son similares a los de la Figura 6.9. Los apalancamientos son mucho menores, lo que refleja la eliminación de varias variables explicativas del modelo. Recuerda que el apalancamiento promedio es \(\bar{h} =(k+1)/n=3/73\approx 0.04\). Así, todavía tenemos tres puntos que superan tres veces el promedio y, por lo tanto, se consideran puntos de alto apalancamiento.
Figura 6.10: Histogramas de residuos estandarizados y apalancamientos usando SIZELOG e INDCOST como variables explicativas.
Código R para producir la Tabla 6.6 y las Figuras 6.9 y 6.10
| Coeficiente | Error Estándar | \(t\)-Estadístico | |
|---|---|---|---|
| (Intercept) | 6.353 | 0.953 | 6.666 |
| SIZELOG | -0.773 | 0.101 | -7.626 |
| INDCOST | 6.264 | 1.610 | 3.889 |
| INDCOSTSQ | -3.585 | 1.265 | -2.833 |
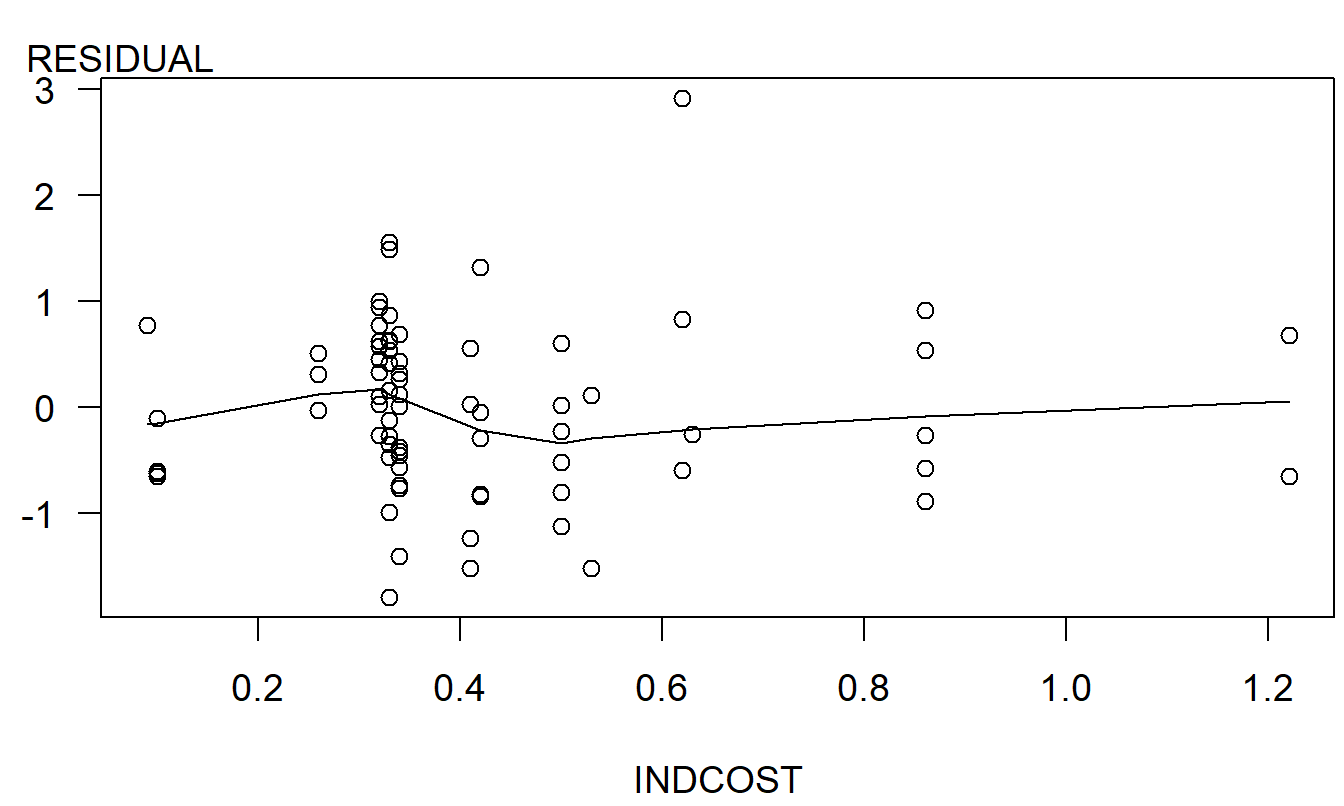
Figura 6.11: Gráfico de dispersión de residuos versus INDCOST. La curva ajustada suave (usando lowess) sugiere un término cuadrático en INDCOST.
Código R para producir la Tabla 6.7 y la Figura 6.11
Los gráficos de residuos versus las variables explicativas revelan algunos patrones sutiles. El gráfico de dispersión de residuos versus INDCOST, en la Figura 6.11, muestra una tendencia cuadrática leve en INDCOST. Para verificar si esta tendencia es importante, la variable INDCOST fue elevada al cuadrado y utilizada como una variable explicativa en un modelo de regresión. Los resultados de este ajuste están en la Tabla 6.6.
A partir del \(t\)-ratio asociado con \((INDCOST)^{2}\), vemos que la variable parece ser importante. El signo es razonable, indicando que la tasa de incremento de COSTLOG disminuye a medida que INDCOST aumenta. Es decir, el cambio esperado en COSTLOG por unidad de cambio en INDCOST es positivo y disminuye a medida que INDCOST aumenta.
Los chequeos diagnósticos adicionales del modelo no revelaron patrones adicionales. Por lo tanto, con los datos disponibles, no podemos afirmar ninguna de las cuatro hipótesis introducidas en la subsección de Introducción. Esto no significa que estas variables no sean importantes. Simplemente estamos diciendo que la variabilidad natural de los datos era lo suficientemente grande como para ocultar cualquier relación que pudiera existir. Sin embargo, hemos establecido la importancia del tamaño de la empresa y del riesgo industrial de la empresa.
La Figura 6.12 resume gráficamente las relaciones estimadas entre estas variables. En particular, en el panel inferior derecho, vemos que para la mayoría de las empresas en la muestra, FIRMCOST fue relativamente estable. Sin embargo, para las empresas pequeñas, medida por SIZELOG, el riesgo industrial, medido por INDCOST, fue particularmente importante. Para las empresas pequeñas, vemos que el FIRMCOST ajustado aumenta a medida que la variable INDCOST aumenta, con la tasa de incremento estabilizándose. Aunque el modelo predice teóricamente que FIRMCOST disminuye con un INDCOST grande \((>1.2)\), no había empresas pequeñas en esta área de la región de datos.
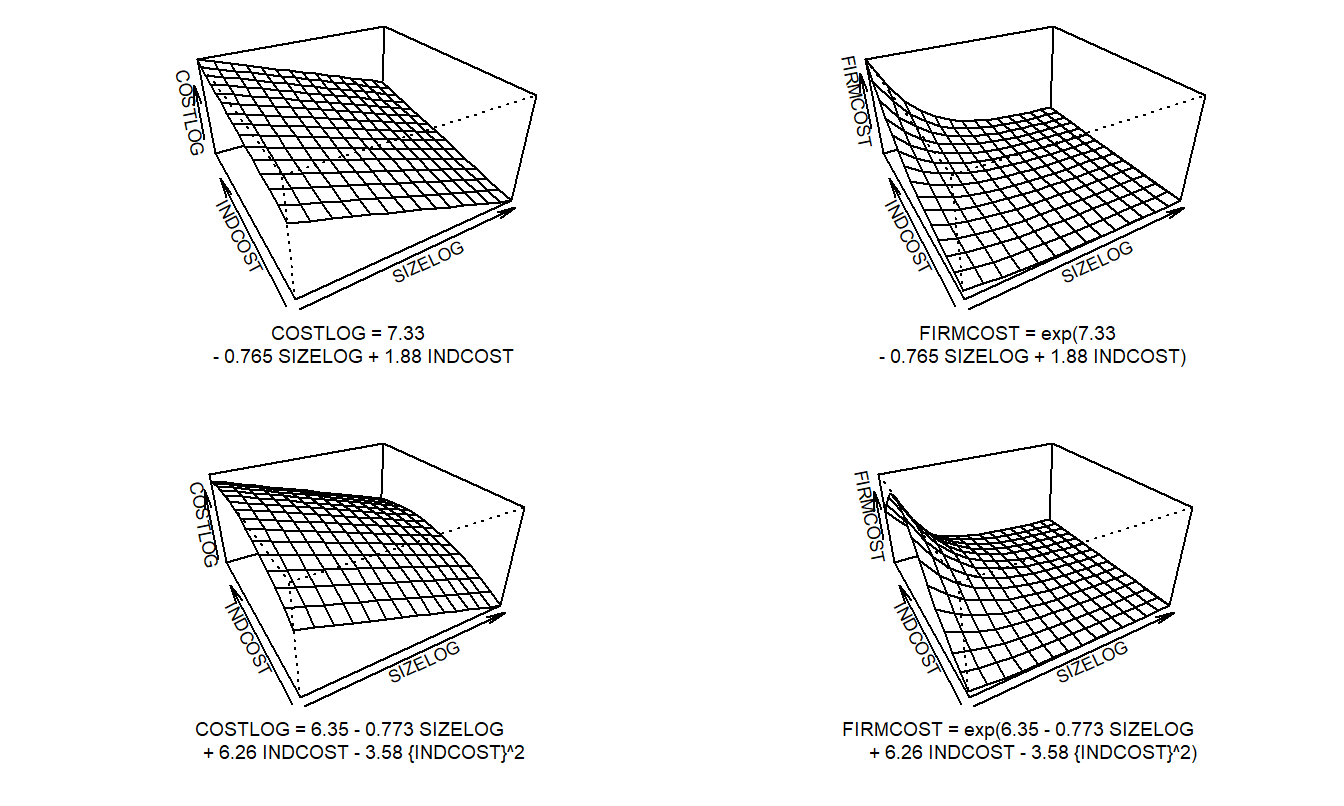
Figura 6.12: Gráfico de cuatro modelos ajustados versus INDCOST y SIZELOG.
6.6 Lecturas Adicionales y Referencias
Este capítulo concluye nuestra Parte I, una introducción a la regresión lineal. Para aprender más sobre la regresión lineal, en la Sección 1.7 proporcionamos referencias a libros de estadística alternativos que introducen el tema. También puedes estar interesado en una presentación más técnica, como el trabajo clásico de Seber (1977) o un trabajo más reciente de Abraham y Ledolter (2006). Para otros enfoques, textos como el de Wooldridge (2009) ofrecen una perspectiva econométrica donde se enfatiza la introducción de la regresión en el contexto de la teoría económica. Alternativamente, libros como el de Agresti y Finlay (2008) brindan una introducción desde una perspectiva más amplia de las ciencias sociales.
Existen muchas explicaciones de la regresión para lectores con diferentes perspectivas y niveles de formación cuantitativa; esto proporciona evidencia adicional de que este es un tema importante para que los actuarios y otros gestores de riesgos financieros lo comprendan. Otra forma de obtener una comprensión más profunda de la regresión lineal es ver cómo se aplica en un contexto de series temporales en la Parte II de este libro o en extensiones a la modelización no lineal en la Parte III.
Consulta Bollen (1989) para una introducción clásica a la modelización de ecuaciones estructurales.
Referencias del Capítulo
- Abraham, Bova and Johannes Ledolter (2006). Introduction to Regression Modeling. Thomson Higher Education, Belmont, CA.
- Agresti, Alan and Barbara Finlay (2008). Statistical Methods for the Social Sciences, Fourth Edition. Prentice Hall, Upper Saddle, NJ.
- Bollen, Kenneth A. (1989). Structural Equations with Latent Variables. New York: Wiley.
- Box, George E. P. (1979). Robustness in the strategy of scientific model building. In R. Launer and G. Wilderson (editors), Robustness in Statistics, pages 201-236, Academic Press, New York.
- Faraway, Julian J. (2005). Linear Models with R. Chapman & Hall/CRC, Boca Raton, Florida.
- Fienberg, S. E (1985). Insurance availability in Chicago. Chapter in Data: A Collection of Problems from Many Fields for the Student and Research Worker. Editors D.F. Andrews and A. M. Herzberg, Springer-Verlag, New York.
- Goldberger, Arthur S. (1972). Structural equation methods in the social sciences. Econometrica 40, 979-1001.
- Harrington, Scott E. and Greg Niehaus (1998). Race, redlining and automobile insurance prices. Journal of Business 71(3), 439-469.
- Heckman, J. J. (1976). The common structure of statistical models of truncation, sample selection and limited dependent variables, and a simple estimator for such models. Ann. Econ. Soc. Meas. 5, 475-492.
- Little, R. J. (1995). Modelling the drop-out mechanism in repeated-measures studies. Journal of the American Statistical Association 90, 1112-1121.
- Little, R. J. and Rubin, D. B. (1987). Statistical Analysis with Missing Data. John Wiley, New York.
- Roberts, Harry V. (1990). Business and economic statistics (with discussion). Statistical Science 4, 372-402.
- Rubin, D. R. (1976). Inference and missing data. Biometrika 63, 581-592.
- Schmit, Joan T. and K. Roth (1990). Cost effectiveness of risk management practices. The Journal of Risk and Insurance 57, No. 3, pages 455-470.
- Seber, G. A. F. (1977). Linear Regression Analysis. John Wiley & Sons, New York.
- Wachter, K. W. and J. Trusell (1982). Estimating historical heights. Journal of the American Statistical Association 77, 279-301.
- Wooldridge, Jeffrey (2009). Introductory Econometrics: A Modern Approach, Fourth Edition. South-Western Publishing, Mason, Ohio.
6.7 Ejercicios
6.1 Segregación por Seguro. ¿Utilizan las compañías de seguros la raza como un factor determinante al ofrecer seguros? Fienberg (1985) recopiló datos de un informe emitido por la Comisión de Derechos Civiles de EE.UU. sobre el número de propietarios de viviendas y pólizas de seguro contra incendios residenciales emitidas en Chicago durante los meses de diciembre de 1977 a febrero de 1978. Las pólizas emitidas se clasificaron como parte del mercado voluntario estándar o del mercado involuntario subestándar. El mercado involuntario consiste en planes de “acceso justo a los seguros” (FAIR); estos son programas de seguros estatales a veces subsidiados por empresas privadas. Estos planes brindan seguros a personas que, de otro modo, serían rechazadas para asegurar su propiedad debido a problemas de alto riesgo. El objetivo principal es comprender la relación entre la actividad de seguros y la variable “raza”, el porcentaje de minorías. Los datos están disponibles para \(n=47\) códigos postales en el área de Chicago. Estos datos también han sido analizados por Faraway (2005).
Para ayudar a controlar el tamaño de la pérdida esperada, Fienberg también recopiló datos de robos e incendios de los departamentos de policía y bomberos de Chicago. Otra variable que proporciona información sobre el tamaño de la pérdida es la antigüedad de la casa. El ingreso mediano, del Censo, proporciona información indirecta sobre el tamaño de la pérdida esperada así como sobre si el solicitante puede permitirse el seguro. La Tabla 6.8 proporciona más detalles sobre estas variables.
| Variable | Descripción | Promedio |
|---|---|---|
| row.names | Código postal | |
| race | Composición racial en porcentaje de minorías | 35 |
| fire | Incendios por 1,000 unidades habitacionales | 12.3 |
| theft | Robos por 1,000 habitantes | 32.4 |
| age | Porcentaje de unidades habitacionales construidas en o antes de 1939 | 60.3 |
| volact | Nuevas pólizas para propietarios más renovaciones, menos cancelaciones y no renovaciones por 100 unidades habitacionales | 6.53 |
| involact | Nuevas pólizas del plan FAIR y renovaciones por 100 unidades habitacionales | 0.615 |
| income | Ingreso familiar mediano | 10696 |
- Produce estadísticas descriptivas de todas las variables, observando los patrones de asimetría para cada variable.
- Crea una matriz de gráficos de dispersión de volact, involact y race. Comenta sobre las tres relaciones pares. ¿Son los patrones consistentes con una hipótesis de discriminación racial?
- Para entender las relaciones entre las variables, produce una tabla de correlaciones.
- Ajusta un modelo lineal usando volact como la variable dependiente y race, fire, theft, age e income como variables explicativas.
d(i). Comenta sobre el signo y la significancia estadística del coeficiente asociado con race.
d(ii). Dos códigos postales resultan tener alta influencia. Repite tu análisis después de eliminar estas dos observaciones. ¿Ha cambiado la significancia de la variable race? ¿Qué pasa con las otras variables explicativas? - Repite el análisis en la parte (d) usando involact como la variable dependiente.
- Define proporción como involact/(volact+involact). Repite el análisis en la parte (d) usando proporción como la variable dependiente.
- Los mismos dos códigos postales tienen alta influencia en las partes (d), (e) y (f). ¿Por qué ocurre esto?
- Este análisis se realiza a nivel de código postal, no a nivel individual. Como enfatizan Harrington y Niehaus (1998), esto introduce un potencial sesgo por variables omitidas. ¿Qué variables se han omitido en el análisis que crees que podrían afectar la disponibilidad del seguro para propietarios y la raza?
- Fienberg señala que la proximidad de un código postal a otro puede afectar la dependencia de las observaciones. Describe cómo podrías incorporar relaciones espaciales en un análisis de regresión.
6.2 Equidad de Género en los Sueldos del Personal Académico. La Universidad de Wisconsin en Madison realizó un estudio titulado “Estudio de Equidad de Género en los Sueldos del Personal Académico”, fechado el 5 de junio de 1992. El propósito principal del estudio fue determinar si las mujeres son tratadas de manera injusta en la determinación de sueldos en una importante universidad de investigación en EE.UU. Para ello, el comité que emitió el informe estudió los sueldos de 1990 de 1,898 miembros de la facultad de la universidad. Es bien conocido que los hombres ganan más que las mujeres. De hecho, el sueldo promedio de 1990 para los 1,528 miembros masculinos de la facultad es 54,478, que es un 28% más alto que el sueldo promedio de 1990 para las miembros femeninas de la facultad, que es 43,315. Sin embargo, se argumenta que los miembros masculinos de la facultad son en general más experimentados (el promedio de años de experiencia es 18.8 años) que las miembros femeninas de la facultad (el promedio de años de experiencia es 11.9 años), y por lo tanto, merecen un sueldo más alto. Al comparar los sueldos de los profesores titulares (controlando así por años de experiencia), los miembros masculinos de la facultad ganaron aproximadamente un 13% más que sus contrapartes femeninas. Aun así, se acuerda en general que los campos en demanda deben ofrecer sueldos más altos para mantener una facultad de primer nivel. Por ejemplo, los sueldos en ingeniería son más altos que los sueldos en humanidades simplemente porque los académicos en ingeniería tienen muchas más oportunidades de empleo fuera de la academia que los académicos en humanidades. Por lo tanto, al considerar los sueldos, también se debe controlar por departamento.
Para controlar estas variables, un estudio de la facultad reporta un análisis de regresión usando el logaritmo del sueldo como la variable dependiente. Las variables explicativas incluyeron información sobre raza, género, rango (ya sea profesor asistente/instructor, profesor asociado o profesor titular), varias medidas de años de experiencia, 98 categorías diferentes de departamentos y una medida de la diferencia de sueldo por departamento. Hubo 109 variables explicativas en total (incluyendo 97 variables binarias departamentales), de las cuales 12 eran variables no departamentales. La Tabla 6.9 reporta las definiciones de variables, estimaciones de parámetros y \(t\)-ratios para las 12 variables no departamentales. La Tabla de ANOVA 6.10 resume el ajuste de la regresión.
| Variable Explicativa | Descripción de la Variable | Estimación del Parámetro | \(t\)-Ratio |
|---|---|---|---|
| INTERCEPT | 10.746 | 261.1 | |
| GENDER | = 1 si es hombre, 0 en caso contrario | 0.016 | 1.86 |
| RACE | = 1 si es blanco, 0 en caso contrario | -0.029 | -2.44 |
| FULL | = 1 si es profesor titular, 0 en caso contrario | 0.186 | 16.42 |
| ASSISTANT | = 1 si es profesor asistente, 0 en caso contrario | -0.205 | -15.93 |
| ANYDOC | = 1 si tiene un título terminal como un Ph.D. | 0.022 | 1.11 |
| COHORT1 | = 1 si fue contratado antes de 1969, 0 en caso contrario | -0.102 | -4.84 |
| COHORT2 | = 1 si fue contratado entre 1969-1985, 0 en caso contrario | -0.046 | -3.48 |
| FULLYEARS | Número de años como profesor titular en UW | 0.012 | 12.84 |
| ASSOCYEARS | Número de años como profesor asociado en UW | -0.012 | -8.65 |
| ASSISYEARS | Número de años como profesor asistente o instructor en UW | 0.002 | 0.91 |
| DIFYRS | Número de años desde la obtención de un título terminal antes de llegar a UW | 0.004 | 4.46 |
| MRKTRATIO | Logaritmo natural de una ‘razón de mercado’ definida como la razón del sueldo promedio en instituciones pares para una disciplina y rango dado | 0.665 | 7.64 |
Fuente: “Estudio de Equidad de Género en los Sueldos del Personal Académico”, 5 de junio de 1992, Universidad de Wisconsin en Madison.
| Fuente | Suma de Cuadrados | \(df\) | Cuadrado Medio | \(F\)-Ratio |
|---|---|---|---|---|
| Regresión | 114.048 | 109 | 1.0463 | 62.943 |
| Error | 29.739 | 1789 | 0.0166 | |
| Total | 143.788 | 1898 |
- Suponga que una miembro femenina de la facultad en el departamento de química siente que su sueldo está por debajo de lo que debería ser. Describa brevemente cómo se puede utilizar este estudio como base para la evaluación del rendimiento.
- Basado en este estudio, ¿cree que los sueldos de las mujeres son significativamente más bajos que los de los hombres?
b(i). Cite argumentos estadísticos que apoyen el hecho de que los hombres no reciben un sueldo significativamente más alto que las mujeres.
b(ii). Cite argumentos estadísticos que apoyen el hecho de que los hombres reciben un sueldo significativamente más alto que las mujeres.
b(iii). Suponga que decide que las mujeres ganan menos que los hombres. Basado en este estudio, ¿cuánto aumentaría los sueldos de las miembros femeninas de la facultad para igualarlos con los de sus contrapartes masculinas?
6.8 Suplementos Técnicos para el Capítulo 6
6.8.1 Efectos de la Especificación Incorrecta del Modelo
Notación. Particiona la matriz de variables explicativas \(\mathbf{X}\) en dos submatrices, cada una con \(n\) filas, de modo que \(\mathbf{X}=(\mathbf{X}_{1} : \mathbf{X}_{2})\). Para simplificar, supongamos que \(\mathbf{X}_{1}\) es una matriz de \(n \times p\). De manera similar, particiona el vector de parámetros \(\boldsymbol \beta =\left( \boldsymbol \beta_{1}^{\prime }, \boldsymbol \beta_{2}^{\prime }\right) ^{\prime }\) de manera que \(\mathbf{X \boldsymbol \beta }=\mathbf{X}_{1} \boldsymbol \beta_{1}+ \mathbf{X}_{2} \boldsymbol \beta_{2}\). Comparamos el modelo completo, o “largo”,
\[ \mathbf{y}=\mathbf{X \boldsymbol \beta }+\boldsymbol \varepsilon = \mathbf{X}_{1} \boldsymbol \beta_{1}+\mathbf{X}_{2} \boldsymbol \beta_{2}+\boldsymbol \varepsilon \]
con el modelo reducido, o “corto”,
\[ \mathbf{y}=\mathbf{X}_{1} \boldsymbol \beta_{1}+\boldsymbol \varepsilon. \]
Esto simplemente generaliza la configuración anterior para permitir la omisión de varias variables.
Efecto del Subajuste. Supongamos que la representación verdadera es el modelo largo pero accidentalmente ejecutamos el modelo corto. Nuestras estimaciones de parámetros al ejecutar el modelo corto están dadas por \(\mathbf{b}_{1}=\mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\mathbf{y}\). Estas estimaciones están sesgadas porque
\[ \begin{array}{ll} \text{Sesgo} &= \text{E }\mathbf{b}_{1}-\boldsymbol \beta_{1} = \text{E}\mathbf{(X}_{1}^{\prime}\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\mathbf{y} -\boldsymbol \beta_{1} \\ &= \mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\text{E }\mathbf{y}-\boldsymbol \beta_{1} \\ &= \mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\left( \mathbf{X}_{1}\boldsymbol \beta_{1}+\mathbf{X}_{2}\boldsymbol \beta_{2}\right) - \boldsymbol \beta_{1} \\ &= \mathbf{(X}_{1}^{\prime}\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\mathbf{X}_{2}\boldsymbol \beta_{2} = \mathbf{A \boldsymbol \beta }_{2}. \end{array} \]
Aquí, \(\mathbf{A}=\mathbf{(X}_{1}^{\prime}\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\mathbf{X}_{2}\) se llama la matriz de alias, o matriz de sesgo. Al ejecutar el modelo corto, la varianza estimada es \(s_{1}^{2}=(\mathbf{y}^{\prime }\mathbf{y}-\mathbf{b}_{1}^{\prime }\mathbf{X}_{1}^{\prime }\mathbf{y})/(n-p)\). Se puede mostrar que
\[\begin{equation} \text{E }s_{1}^{2}=\sigma ^{2}+(n-p)^{-1}\boldsymbol \beta_{2}^{\prime }\left( \mathbf{X}_{2}^{\prime }\mathbf{X}_{2}-\mathbf{X}_{2}^{\prime }\mathbf{X}_{1}\mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\mathbf{X}_{2}\right) \boldsymbol \beta_{2}. \tag{6.3} \end{equation}\]
Así, \(s_{1}^{2}\) es una estimación “sobresesgada” de \(\sigma ^{2}\).
Sean \(\mathbf{x}_{1i}^{\prime }\) y \(\mathbf{x}_{2i}^{\prime }\) las \(i\)-ésimas filas de \(\mathbf{X}_{1}\) y \(\mathbf{X}_{2}\), respectivamente. Usando el modelo corto ajustado, el \(i\)-ésimo valor ajustado es \(\hat{y}_{1i}=\mathbf{x}_{1i}^{\prime }\mathbf{b}_{1}\). La verdadera respuesta esperada \(i\)-ésima es E \(\hat{y}_{1i}=\mathbf{x}_{1i}^{\prime } \boldsymbol \beta_{1} + \mathbf{x}_{2i}^{\prime } \boldsymbol \beta_{2}\). Así, el sesgo del \(i\)-ésimo valor ajustado es
\[ \begin{array}{ll} \text{Sesgo}(\hat{y}_{1i}) &= \text{E }\hat{y}_{1i}-\text{E }y_{i}=\mathbf{x}_{1i}^{\prime }\text{E }\mathbf{b}_{1}-\left( \mathbf{x}_{1i}^{\prime }\boldsymbol \beta_{1}+\mathbf{x}_{2i}^{\prime } \boldsymbol \beta_{2}\right) \\ & =\mathbf{x}_{1i}^{\prime }(\boldsymbol \beta_{1}+\mathbf{A \boldsymbol \beta }_{2})-\left( \mathbf{x}_{1i}^{\prime }\boldsymbol \beta_{1}+\mathbf{x}_{2i}^{\prime }\boldsymbol \beta_{2}\right) =(\mathbf{x}_{1i}^{\prime }\mathbf{A}-\mathbf{x}_{2i}^{\prime })\boldsymbol \beta_{2}. \end{array} \]
Usando esto y la ecuación (6.3), se muestra mediante álgebra directa que
\[\begin{equation} \text{E }s_{1}^{2}=\sigma ^{2}+(n-p)^{-1}\sum_{i=1}^{n}(\text{Sesgo}(\hat{y}_{1i}))^{2}. \tag{6.4} \end{equation}\]
Efecto del Sobreajuste. Supongamos ahora que la representación verdadera es el modelo corto, pero accidentalmente usamos el modelo largo. Con la matriz de alias \(\mathbf{A}=\mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\mathbf{X}_{2}\), podemos reparametrizar el modelo largo
\[ \begin{array}{ll} \mathbf{y} & =\mathbf{X}_{1}\boldsymbol \beta_{1}+\mathbf{X}_{2}\boldsymbol \beta_{2} + \boldsymbol \varepsilon = \mathbf{X}_{1}\left( \boldsymbol \beta_{1}+\mathbf{A \boldsymbol \beta }_{2}\right) + \mathbf{E}_{1}\boldsymbol \beta_{2} + \boldsymbol \varepsilon \\ &= \mathbf{X}_{1}\boldsymbol \alpha_{1}+\mathbf{E}_{1}\boldsymbol \beta_{2} + \boldsymbol \varepsilon \end{array} \]
donde \(\mathbf{E}_{1}=\mathbf{X}_{2}-\mathbf{X}_{1}\mathbf{A}\) y \(\boldsymbol \alpha_{1}=\boldsymbol \beta_{1}+\mathbf{A \boldsymbol \beta}_{2}\). La ventaja de esta nueva parametrización es que \(\mathbf{X}_{1}\) es ortogonal a \(\mathbf{E}_{1}\) porque \(\mathbf{X}_{1}^{\prime }\mathbf{E}_{1}=\mathbf{X}_{1}^{\prime }(\mathbf{X}_{2}-\mathbf{X}_{1}\mathbf{A})=\mathbf{0}\). Con \(\mathbf{X}^{\ast }=(\mathbf{X}_{1}: \mathbf{E}_{1})\) y \(\boldsymbol \alpha =(\boldsymbol \alpha_{1}^{\prime }\boldsymbol \beta_{1}^{\prime })^{\prime }\), el vector de estimaciones de mínimos cuadrados es
\[ \begin{array}{ll} \mathbf{a} &= \begin{bmatrix} \mathbf{a}_{1} \\ \mathbf{b}_{1} \end{bmatrix} = \left( \mathbf{X}^{\ast \prime }\mathbf{X}^{\ast }\right) ^{-1}\mathbf{X}^{\ast \prime }\mathbf{y} \\ & = \begin{bmatrix} \mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1} & 0 \\ 0 & \mathbf{(E}_{1}^{\prime }\mathbf{E}_{1}\mathbf{)}^{-1} \end{bmatrix} \begin{bmatrix} \mathbf{X}_{1}^{\prime }\mathbf{y} \\ \mathbf{E}_{1}^{\prime }\mathbf{y} \end{bmatrix} \\ & = \begin{bmatrix} \mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\mathbf{y} \\ \mathbf{(E}_{1}^{\prime }\mathbf{E}_{1}\mathbf{)}^{-1}\mathbf{E}_{1}^{\prime }\mathbf{y} \end{bmatrix}. \end{array} \]
Desde el modelo verdadero (corto), \(\mathrm{E}~\mathbf{y}=\mathbf{X}_{1}\boldsymbol \beta_{1}\), tenemos que
\[ \mathrm{E}~\mathbf{b}_{2} =(\mathbf{E}_{1}^{\prime }\mathbf{E}_{1})^{-1}\mathbf{E}_{1}^{\prime }\mathrm{E}(\mathbf{y}) =(\mathbf{E}_{1}^{\prime }\mathbf{E}_{1})^{-1}\mathbf{E}_{1}^{\prime }\mathrm{E}~ (\mathbf{X}_{1}\mathbf{\beta}_{1}) =\mathbf{0}, \]
porque \(\mathbf{X}_{1}^{\prime }\mathbf{E}_{1}=\mathbf{0}\). La estimación de mínimos cuadrados de \(\boldsymbol \beta_{1}\) es \(\mathbf{b}_{1}=\mathbf{a}_{1}-\mathbf{Ab}_{2}\). Debido a que
\[ \mathrm{E}~\mathbf{a}_{1}=\mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\mathrm{E}~\mathbf{y}=\boldsymbol \beta_{1} \] bajo el modelo corto, tenemos que \(\mathrm{E}~ \mathbf{b}_{1} = \mathrm{E}~ \mathbf{a}_{1}-\mathbf{A} \mathrm{E}~ \mathbf{b}_{2} = \boldsymbol \beta_{1}-\mathbf{0}=\boldsymbol \beta_{1}\). Así, aunque accidentalmente usemos el modelo largo, \(\mathbf{b}_{1}\) sigue siendo un estimador no sesgado de \(\boldsymbol \beta_{1}\) y \(\mathbf{b}_{2}\) es un estimador no sesgado de \(\mathbf{0}\). Por lo tanto, no hay sesgo en el valor ajustado \(i\)-ésimo porque
\[ \mathrm{E}~\hat{y}_{i}= \mathrm{E}~(\mathbf{x}_{1i}^{\prime }\mathbf{b}_{1}+\mathbf{x}_{2i}^{\prime }\mathbf{b}_{2})=\mathbf{x}_{1i}^{\prime }\boldsymbol \beta_{1}= \mathrm{E}~y_{i} . \]
Estadístico \(C_{p}\). Supongamos inicialmente que la representación verdadera es el modelo largo, pero usamos erróneamente el modelo corto. El valor ajustado \(i\)-ésimo es \(\hat{y}_{1i}=\mathbf{x}_{1i}^{\prime }\mathbf{b}_{1}\), que tiene un error cuadrático medio (MSE)
\[ \text{MSE }\hat{y}_{1i} = \text{E}(\hat{y}_{1i} - \text{E }\hat{y}_{1i})^{2} = \text{Var }\hat{y}_{1i} + \left( \text{Bias }\hat{y}_{1i} \right)^{2}. \]
Para la primera parte, tenemos que
\[ \begin{array}{ll} \mathrm{Var}~\hat{y}_{1i}& =\mathrm{Var}\left( \mathbf{x}_{1i}^{\prime }\mathbf{b}_{1}\right) = \text{Var} \left( \mathbf{x}_{1i}^{\prime } \mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1}\mathbf{X}_{1}^{\prime }\mathbf{y}\right) \\ & = \sigma^{2} \mathbf{x}_{1i} \mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1} \mathbf{x}_{1i}^{\prime }. \end{array} \]
Podemos pensar en \(\mathbf{x}_{1i} \mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1} \mathbf{x}_{1i}^{\prime }\) como la palanca \(i\)-ésima, como en la ecuación (5.3). Así, \(\sum_{i=1}^{n} \mathbf{x}_{1i} \mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1} \mathbf{x}_{1i}^{\prime } = p\), el número de columnas de \(\mathbf{X}_{1}\). Con esto, podemos definir el error total estandarizado
\[ \begin{array}{ll} \frac{\sum_{i=1}^{n} \text{MSE }\hat{y}_{1i}}{\sigma^{2}} & = \frac{\sum_{i=1}^{n} \left( \text{Var }\hat{y}_{1i} + \left( \text{Bias }\hat{y}_{1i} \right)^{2} \right)}{\sigma^{2}} \\ & = \frac{\sigma^{2} \sum_{i=1}^{n} \left( \mathbf{x}_{1i} \mathbf{(X}_{1}^{\prime }\mathbf{X}_{1}\mathbf{)}^{-1} \mathbf{x}_{1i}^{\prime } + \left( \text{Bias }\hat{y}_{1i} \right)^{2} \right)}{\sigma^{2}} \\ &= p + \sigma^{-2} \sum_{i=1}^{n} \left( \text{Bias }\hat{y}_{1i} \right)^{2}. \end{array} \]
Ahora, si \(\sigma^{2}\) es conocido, a partir de la ecuación (6.4), una estimación no sesgada del error total estandarizado es \(p + \frac{(n-p)(s_{1}^{2} - \sigma^{2})}{\sigma^{2}}\). Como \(\sigma^{2}\) es desconocido, debe estimarse. Si no estamos seguros de si el modelo largo o el corto es la representación apropiada, una opción conservadora es usar \(s^{2}\) del modelo largo, o completo. Incluso si el modelo corto es el verdadero, \(s^{2}\) del modelo largo sigue siendo una estimación no sesgada de \(\sigma^{2}\). Así, definimos
\[ C_{p} = p + \frac{(n-p)(s_{1}^{2} - s^{2})}{s^{2}}. \]
Si el modelo corto es correcto, entonces \(\mathrm{E}~s_{1}^{2} = \mathrm{E}~s^{2} = \sigma^{2}\) y \(\mathrm{E}~C_{p} \approx p\). Si el modelo largo es verdadero, entonces \(\mathrm{E}~s_{1}^{2} > \sigma^{2}\) y \(\mathrm{E}~C_{p} > p\).