Capítulo 2 Regresión Lineal Básica
Vista previa del capítulo. Este capítulo considera la regresión en el caso de tener solo una variable explicativa. A pesar de esta aparente simplicidad, la mayoría de las ideas profundas de la regresión pueden desarrollarse en este marco. Al limitarnos al caso de una variable, podemos expresar muchos cálculos usando álgebra simple. Esto nos permitirá desarrollar nuestra intuición sobre las técnicas de regresión al reforzarla con demostraciones simples. Además, podemos ilustrar las relaciones entre dos variables gráficamente porque estamos trabajando en solo dos dimensiones. Las herramientas gráficas resultan ser importantes para desarrollar un vínculo entre los datos y un modelo.
2.1 Correlaciones y Mínimos Cuadrados
La regresión trata sobre relaciones. Específicamente, estudiaremos cómo dos variables, una \(x\) y una \(y\), están relacionadas. Queremos poder responder preguntas como, si cambiamos el nivel de \(x\), ¿qué pasará con el nivel de \(y\)? Si comparamos dos “sujetos” que parecen similares excepto por la medición de \(x\), ¿cómo diferirán sus mediciones de \(y\)? Entender las relaciones entre variables es fundamental para la gestión cuantitativa, particularmente en ciencias actuariales donde la incertidumbre es tan prevalente.
Es útil trabajar con un ejemplo específico para familiarizarnos con conceptos clave. El análisis de ventas de lotería no ha sido parte de la práctica actuarial tradicional, pero es un área de crecimiento en la que los actuarios podrían contribuir.
Ejemplo: Ventas de la Lotería de Wisconsin. Los administradores de la lotería del estado de Wisconsin están interesados en evaluar los factores que afectan las ventas de lotería. Las ventas consisten en boletos de lotería en línea que se venden en establecimientos minoristas seleccionados en Wisconsin. Estos boletos generalmente tienen un precio de $1.00, por lo que el número de boletos vendidos equivale a los ingresos de la lotería. Analizamos las ventas promedio de lotería (SALES) durante un período de cuarenta semanas, de abril de 1998 a enero de 1999, en cincuenta áreas seleccionadas al azar identificadas por código postal (ZIP) dentro del estado de Wisconsin.
Aunque muchas variables económicas y demográficas podrían influir en las ventas, nuestro primer análisis se centra en la población (POP) como un determinante clave. El Capítulo 3 mostrará cómo considerar variables explicativas adicionales. Intuitivamente, parece claro que las áreas geográficas con más personas tendrán mayores ventas. Entonces, otras cosas siendo iguales, un \(x=POP\) más grande significa un \(y=SALES\) más grande. Sin embargo, la lotería es una fuente importante de ingresos para el estado y queremos ser lo más precisos posible.
Una notación adicional será útil posteriormente. En esta muestra, hay cincuenta áreas geográficas y usamos subíndices para identificar cada área. Por ejemplo, \(y_1\) = 1,285.4 representa las ventas para la primera área en la muestra que tiene una población de \(x_1\) = 435. Llamamos al par ordenado (\(x_1\), \(y_1\)) = (435, 1285.4) la primera observación. Extendiendo esta notación, la muestra completa que contiene cincuenta observaciones puede representarse por (\(x_1\), \(y_1\)), …, (\(x_{50}\), \(y_{50}\)). Los puntos suspensivos ( … ) significan que el patrón continúa hasta que se encuentra el último objeto. A menudo hablaremos de un miembro genérico de la muestra, refiriéndonos a (\(x_i\), \(y_i\)) como la \(i\)-ésima observación.
Los conjuntos de datos pueden complicarse, por lo que será útil si comienza trabajando con cada variable por separado. Los dos paneles en la Figura 2.1 muestran histogramas que dan una impresión visual rápida de la distribución de cada variable de forma aislada. La Tabla 2.1 proporciona resúmenes numéricos correspondientes. Para ilustrar, para la variable población (POP), vemos que el área con el menor número contenía 280 personas, mientras que la más grande contenía 39,098. El promedio, sobre 50 códigos postales, fue de 9,311.04. Para nuestra segunda variable, las ventas fueron tan bajas como 189 y tan altas como 33,181.
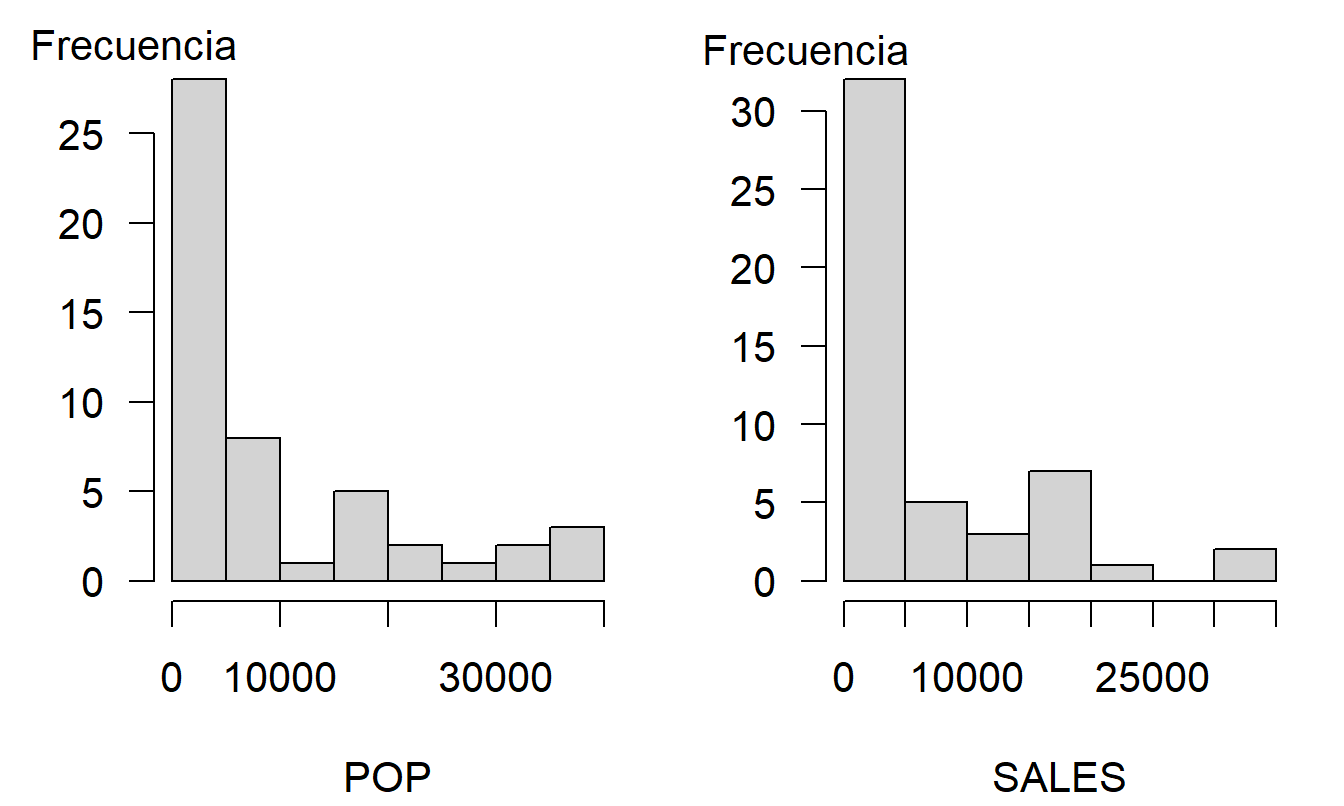
Figura 2.1: Histogramas de Población y Ventas. Cada distribución está sesgada a la derecha, lo que indica que hay muchas áreas pequeñas en comparación con unas pocas áreas con mayores ventas y poblaciones.
| Promedio | Mediana | Desviación Estándar | Mínimo | Máximo | |
|---|---|---|---|---|---|
| POP | 9,311 | 4,406 | 11,098 | 280 | 39,098 |
| SALES | 6,495 | 2,426 | 8,103 | 189 | 33,181 |
| Fuente: Frees y Miller (2003) |
Código R para producir la Figura 2.1 y la Tabla 2.1
Como muestra la Tabla 2.1, las estadísticas resumen básicas dan ideas útiles de la estructura de las características clave de los datos. Después de entender la información en cada variable de forma aislada, podemos comenzar a explorar la relación entre las dos variables.
Gráfico de Dispersión y Coeficientes de Correlación - Herramientas Básicas de Resumen
La herramienta gráfica básica utilizada para investigar la relación entre dos variables es un gráfico de dispersión, como se muestra en la Figura 2.2. Aunque podemos perder los valores exactos de las observaciones al graficar los datos, ganamos una impresión visual de la relación entre la población y las ventas. En la Figura 2.2 vemos que las áreas con poblaciones más grandes tienden a comprar más boletos de lotería. ¿Qué tan fuerte es esta relación? ¿Puede el conocimiento de la población del área ayudarnos a anticipar los ingresos por ventas de lotería? Exploramos estas dos preguntas a continuación.
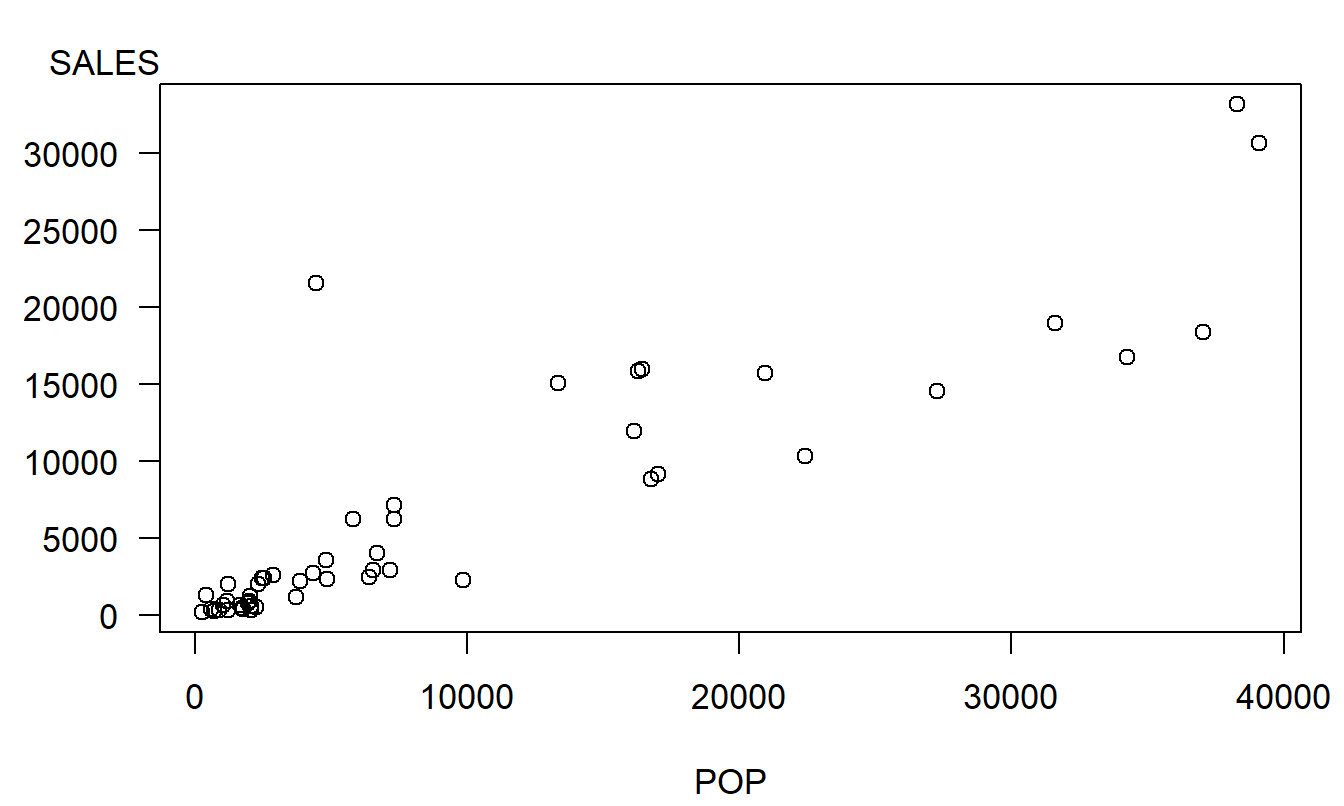
Figura 2.2: Un gráfico de dispersión de los datos de la lotería. Cada uno de los 50 símbolos de la gráfica corresponde a un código postal en el estudio. Esta figura sugiere que las áreas postales con poblaciones más grandes tienen mayores ingresos de lotería.
Código R para Producir la Figura 2.2
Una forma de resumir la fuerza de la relación entre dos variables es a través de una estadística de correlación.
Definición. El coeficiente de correlación ordinario, o de Pearson se define como \[ r = \frac{1}{(n-1)s_xs_y}\sum_{i=1}^{n}\left( x_{i}-\overline{x}\right) \left( y_{i}-\overline{y}\right) . \]
Aquí, usamos la desviación estándar de la muestra \(s_y = \sqrt{(n-1)^{-1} \sum_{i=1}^{n}\left( y_i - \overline{y}\right)^{2}}\) definida en la Sección 1.2, con una notación similar para \(s_x\).
Aunque existen otras estadísticas de correlación, el coeficiente de correlación ideado por Pearson (1895) tiene varias propiedades deseables. Una propiedad importante es que, para cualquier conjunto de datos, \(r\) está acotado entre -1 y 1, es decir, \(-1\leq r\leq 1\). (El Ejercicio 2.3 proporciona pasos para comprobar esta propiedad.) Si \(r\) es mayor que cero, se dice que las variables están correlacionadas positivamente. Si \(r\) es menor que cero, se dice que las variables están correlacionadas negativamente. Cuanto mayor sea el coeficiente en valor absoluto, más fuerte será la relación. De hecho, si \(r=1\), entonces las variables están perfectamente correlacionadas. En este caso, todos los datos se encuentran en una línea recta que pasa por los cuadrantes inferior izquierdo y superior derecho. Si \(r=-1\), entonces todos los datos se encuentran en una línea que pasa por los cuadrantes superior izquierdo e inferior derecho. El coeficiente \(r\) es una medida de una relación lineal entre dos variables.
Se dice que el coeficiente de correlación es invariante a la ubicación y la escala. Así, el centro de ubicación de cada variable no importa en el cálculo de \(r\). Por ejemplo, si agregamos $100 a las ventas de cada código postal, cada \(y_i\) aumentará en 100. Sin embargo, \(\overline{y}\), el precio de compra promedio, también aumentará en 100 de modo que la desviación \(y_i - \overline{y}\) permanece sin cambios, o invariante. Además, la escala de cada variable no importa en el cálculo de \(r\). Por ejemplo, supongamos que dividimos cada población entre 1000, de modo que \(x_i\) ahora representa la población en miles. Así, \(\overline{x}\) también se divide entre 1000 y usted debería verificar que \(s_x\) también se divide entre 1000. Así, la versión estandarizada de \(x_i\), \(\left( x_i-\overline{x}\right) /s_x\), permanece sin cambios, o invariante. Muchos paquetes estadísticos calculan una versión estandarizada de una variable restando el promedio y dividiendo por la desviación estándar. Ahora, usemos \(y_{i,std}=\left( y_i- \overline{y}\right) /s_y\) y \(x_{i,std}=\left( x_i-\overline{x} \right) /s_x\) para que sean las versiones estandarizadas de \(y_i\) y \(x_i\), respectivamente. Con esta notación, podemos expresar el coeficiente de correlación como \(r=(n-1)^{-1}\sum_{i=1}^{n}x_{i,std}\times y_{i,std}.\)
Se dice que el coeficiente de correlación es una medida adimensional. Esto se debe a que hemos eliminado dólares, y todas las demás unidades de medida, considerando las variables estandarizadas \(x_{i,std}\) y \(y_{i,std}\). Debido a que el coeficiente de correlación no depende de las unidades de medida, es una estadística que puede compararse fácilmente entre diferentes conjuntos de datos.
En el mundo de los negocios, el término “correlación” se usa a menudo como sinónimo del término “relación.” Para los propósitos de este texto, utilizamos el término correlación cuando nos referimos únicamente a relaciones lineales. La relación no lineal clásica es \(y=x^{2}\), una relación cuadrática. Considere esta relación y el conjunto de datos ficticios para \(x\), \(\{-2,1,0,1,2\}\). Ahora, como ejercicio (2.2), produzca un gráfico aproximado del conjunto de datos:
\[ \begin{array}{l|rrrrr} \hline i & 1 & 2 & 3 & 4 & 5 \\ \hline x_i & -2 & -1 & 0 & 1 & 2 \\ y_i & 4 & 1 & 0 & 1 & 4 \\ \hline \end{array} \]
El coeficiente de correlación para este conjunto de datos resulta ser \(r=0\) (verifíquelo). Por lo tanto, a pesar de que hay una relación perfecta entre \(x\) y \(y\) (\(=x^{2}\)), hay una correlación cero. Recuerde que los cambios de ubicación y escala no son relevantes en las discusiones sobre correlación, por lo que podríamos cambiar fácilmente los valores de \(x\) y \(y\) para que sean más representativos de un conjunto de datos de negocios.
¿Qué tan fuerte es la relación entre \(y\) y \(x\) para los datos de la lotería? Gráficamente, la respuesta es un gráfico de dispersión, como en la Figura 2.2. Numéricamente, la respuesta principal es el coeficiente de correlación, que resulta ser \(r\) = 0.886 para este conjunto de datos. Interpretamos esta estadística diciendo que SALES y POP están correlacionados (positivamente). La fuerza de la relación es fuerte porque \(r\) = 0.886 está cerca de uno. En resumen, podemos describir esta relación diciendo que hay una fuerte correlación entre SALES y POP.
Método de Mínimos Cuadrados
Ahora comenzamos a explorar la pregunta: “¿Puede el conocimiento de la población ayudarnos a entender las ventas?” Para responder a esta pregunta, identificamos las ventas como la variable de respuesta, o dependiente. La variable de población, que se usa para ayudar a entender las ventas, se llama la variable explicativa, o independiente.
Supongamos que tenemos disponibles los datos de muestra de cincuenta ventas \(\{y_1, \ldots, y_{50} \}\) y tu trabajo es predecir las ventas de un código postal seleccionado al azar. Sin conocimiento de la variable de población, un predictor sensato es simplemente \(\overline{y}=6,495\), el promedio de la muestra disponible. Naturalmente, anticipas que las áreas con mayores poblaciones tendrán mayores ventas. Es decir, si también tienes conocimiento de la población, ¿puede mejorarse esta estimación? Si es así, ¿cuánto?
Para responder a estas preguntas, el primer paso asume una relación lineal aproximada entre \(x\) y \(y\). Para ajustar una línea a nuestro conjunto de datos, usamos el método de mínimos cuadrados. Necesitamos una técnica general para que, si diferentes analistas están de acuerdo en los datos y en la técnica de ajuste, entonces estarán de acuerdo en la línea. Si diferentes analistas ajustan un conjunto de datos usando aproximaciones a ojo, en general llegarán a diferentes líneas, incluso usando el mismo conjunto de datos.
El método comienza con la línea \(y=b_0^{\ast}+b_1^{\ast}x\), donde la intersección y la pendiente, \(b_0^{\ast}\) y \(b_1^{\ast}\), son meramente valores genéricos. Para la \(i\)-ésima observación, \(y_i-\left( b_0^{\ast}+b_1^{\ast}x_i\right)\) representa la desviación del valor observado \(y_i\) de la línea en \(x_i\). La cantidad \[ SS(b_0^{\ast},b_1^{\ast})=\sum_{i=1}^{n}\left( y_i-\left( b_0^{\ast}+b_1^{\ast}x_i\right) \right) ^{2} \] representa la suma de desviaciones cuadradas para esta línea candidata. El método de mínimos cuadrados consiste en determinar los valores de \(b_0^{\ast}\) y \(b_1^{\ast}\) que minimizan \(SS(b_0^{\ast},b_1^{\ast})\). Este es un problema fácil que puede resolverse mediante cálculo, de la siguiente manera. Tomando derivadas parciales con respecto a cada argumento obtenemos \[ \frac{\partial }{\partial b_0^{\ast}}SS(b_0^{\ast},b_1^{\ast})=\sum_{i=1}^{n}(-2)\left( y_i-\left( b_0^{\ast}+b_1^{\ast}x_i\right) \right) \] y \[ \frac{\partial }{\partial b_1^{\ast}}SS(b_0^{\ast},b_1^{\ast})=\sum_{i=1}^{n}(-2x_i)\left( y_i-\left( b_0^{\ast}+b_1^{\ast}x_i\right) \right) . \] Se invita al lector a tomar las segundas derivadas parciales para asegurarse de que estamos minimizando, no maximizando, esta función. Igualando estas cantidades a cero y cancelando términos constantes obtenemos \[ \sum_{i=1}^{n}\left( y_i-\left( b_0^{\ast}+b_1^{\ast}x_i\right) \right) =0 \] y \[ \sum_{i=1}^{n}x_i\left( y_i-\left( b_0^{\ast}+b_1^{\ast}x_i\right) \right) =0, \] que son conocidas como las ecuaciones normales. Resolver estas ecuaciones proporciona los valores de \(b_0^{\ast}\) y \(b_1^{\ast}\) que minimizan la suma de cuadrados.
Definición. Las estimaciones de intersección y pendiente de mínimos cuadrados son
\[ b_1=r\frac{s_y}{s_x}~~~~~\mathrm{y}~~~~~b_0=\overline{y}-b_1 \overline{x}. \] La línea que determinan, \(\widehat{y}=b_0+b_1x\), se llama la línea de regresión ajustada.
Hemos eliminado la notación de asterisco, o estrella, porque \(b_0\) y \(b_1\) ya no son valores “candidatos”.
¿Proporciona este procedimiento una línea sensata para nuestras ventas de lotería de Wisconsin? Anteriormente, calculamos \(r=0.886\). A partir de esto y de las estadísticas básicas resumidas en la Tabla 2.1, tenemos \(b_1 = 0.886 \left( 8,103\right) /11,098=0.647\) y \(b_0 = 6,495-(0.647)9,311 = 469.7\). Esto produce la línea de regresión ajustada \[ \widehat{y} = 469.7 + (0.647)x. \] El sombrero, o “gorro”, encima de la \(y\) nos recuerda que esta \(\widehat{y}\), o \(\widehat{SALES}\), es un valor ajustado. Una aplicación de la línea de regresión es estimar ventas para una población específica, digamos, \(x=10,000\). La estimación es la altura de la línea de regresión, que es \(469.7 + (0.647)(10,000)\) \(= 6,939.7\).
Ejemplo: Resumiendo Simulaciones. El análisis de regresión es una herramienta para resumir datos complejos. En el trabajo práctico, los actuarios a menudo simulan escenarios financieros complicados; a menudo se pasa por alto que la regresión puede usarse para resumir relaciones de interés.
Para ilustrar, Manistre y Hancock (2005) simularon muchas realizaciones de una opción put europea a 10 años y demostraron la relación entre dos medidas de riesgo actuarial, el valor en riesgo (VaR) y la expectativa de cola condicional (CTE). Para un ejemplo, estos autores examinaron rendimientos de acciones distribuidos logarítmicamente con un precio inicial de $100, de modo que en 10 años el precio de la acción estaría distribuido como \[ S(Z)=100 \exp \left( (.08) 10 + .15 \sqrt{10} Z \right), \] basado en un retorno medio anual del 8%, desviación estándar del 15% y el resultado de una variable aleatoria normal estándar \(Z\). La opción put paga la diferencia entre el precio de ejercicio, que se tomará como 110 para este ejemplo, y \(S(Z)\). El valor presente de esta opción es \[ C(Z)= \mathrm{e}^{-0.06(10)} \mathrm{max} \left(0, 110-S(Z) \right), \] basado en una tasa de descuento del 6%.
Para estimar el VaR y el CTE, para cada \(i\), se simularon 1000 variables aleatorias normales estándar i.i.d. y se usaron para calcular 1000 valores presentes, \(C_{i1}, \ldots, C_{i,1000}.\) El percentil 95 de estos valores presentes es la estimación del valor en riesgo, denotado como \(VaR_i.\) El promedio de los 50 valores presentes más altos (\(= (1-.05) \times 1000\)) es la estimación de la expectativa de cola condicional, denotada como \(CTE_i\). Manistre y Hancock (2005) realizaron este cálculo \(i=1, \ldots, 1000\) veces; el resultado se presenta en la Figura 2.3. El diagrama de dispersión muestra una relación fuerte pero no perfecta entre el \(VaR\) y el \(CTE\), el coeficiente de correlación resulta ser \(r=0.782\).
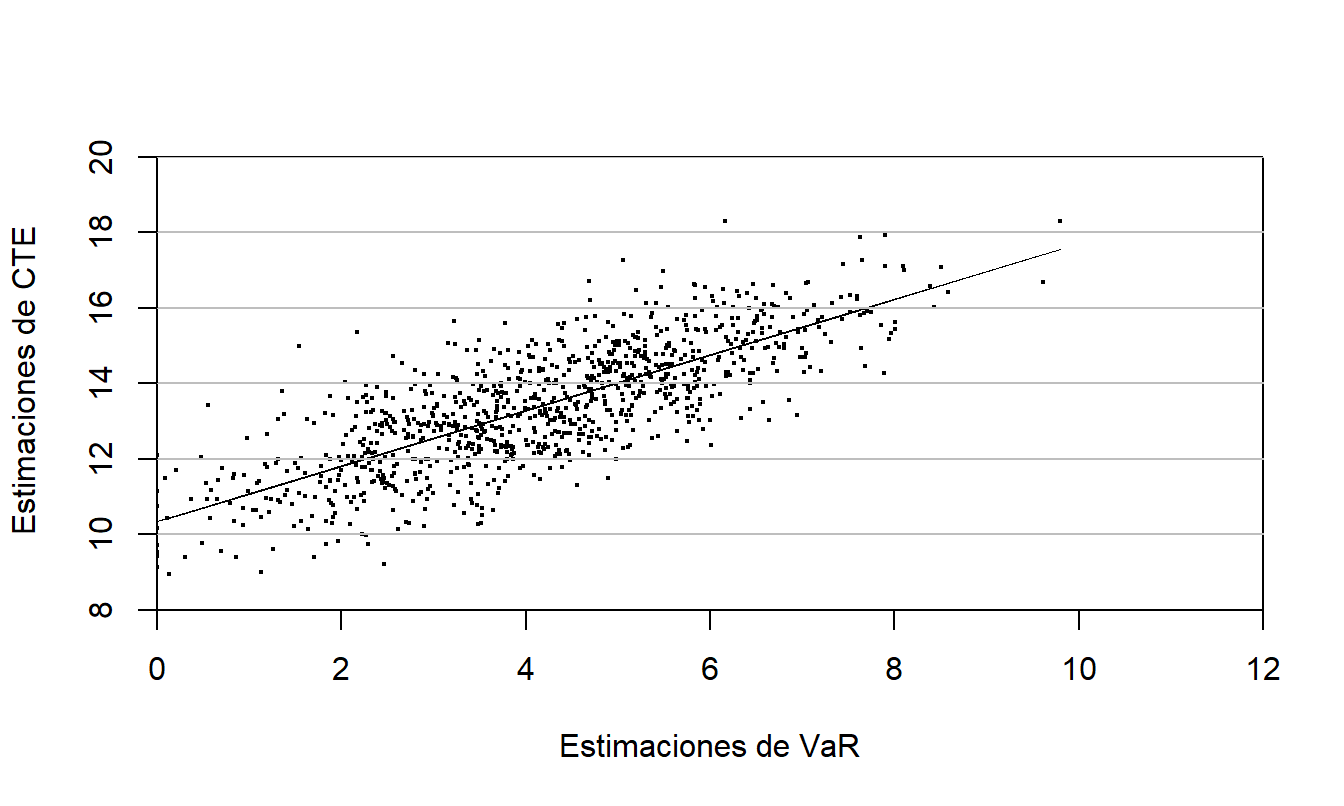
Figura 2.3: Gráfico de la Expectativa de Cola Condicional (CTE) frente al Valor en Riesgo (VaR). Basado en \(n=1,000\) simulaciones de un bono put europeo a 10 años. Fuente: Manistre y Hancock (2005).
Código R para producir la Figura 2.3
2.2 Modelo Básico de Regresión Lineal
El diagrama de dispersión, el coeficiente de correlación y la línea de regresión ajustada son herramientas útiles para resumir la relación entre dos variables para un conjunto de datos específico. Para inferir relaciones generales, necesitamos modelos para representar los resultados de poblaciones amplias.
Este capítulo se centra en un modelo de “regresión lineal básica”. La parte de “regresión lineal” proviene del hecho de que ajustamos una línea a los datos. La parte de “básica” es porque usamos solo una variable explicativa, \(x\). Este modelo también se conoce como una “regresión lineal simple”. Este texto evita este lenguaje porque da la falsa impresión de que las ideas e interpretaciones de regresión con una variable explicativa son siempre sencillas.
Ahora introducimos dos conjuntos de supuestos del modelo básico, las representaciones “observables” y de “error”. Son equivalentes, pero cada una nos ayudará a medida que extendamos los modelos de regresión más allá de lo básico.
\[ {\small \begin{array}{l} \hline \hline &\textbf{Modelo Básico de Regresión Lineal} \\ &\textbf{Supuestos de Muestreo de la Representación Observable} \\ \hline \text{F1}. & \mathrm{E}~y_i=\beta_0 + \beta_1 x_i . \\ \text{F2}. & \{x_1,\ldots ,x_n\} \text{ son variables no estocásticas}. \\ \text{F3}. & \mathrm{Var}~y_i=\sigma ^{2}. \\ \text{F4}. & \{ y_i\} \text{ son variables aleatorias independientes}. \\ \hline\ \end{array} } \]
La “representación observable” se enfoca en variables que podemos ver (u observar), \((x_i,y_i)\). La inferencia sobre la distribución de \(y\) es condicional a las variables explicativas observadas, de modo que podemos tratar \(\{x_1,\ldots ,x_n\}\) como variables no estocásticas (supuesto F2). Al considerar tipos de mecanismos de muestreo para \((x_i,y_i)\), es conveniente pensar en un esquema de muestreo aleatorio estratificado, donde los valores de \(\{x_1,\ldots ,x_n\}\) se tratan como los estratos, o grupos. Bajo el muestreo estratificado, para cada valor único de \(x_i\), tomamos una muestra aleatoria de una población. Para ilustrar, supongamos que se está extrayendo de una base de datos de empresas para comprender el rendimiento de las acciones (\(y\)) y desea estratificar según el tamaño de la empresa. Si la cantidad de activos es una variable continua, entonces podemos imaginar tomar una muestra de tamaño 1 para cada empresa. De esta manera, hipotetizamos una distribución de rendimientos de acciones condicional al tamaño de los activos de la empresa.
Digresión: A menudo verá informes que resumen resultados para los “50 mejores gerentes” o las “100 mejores universidades”, medidos por alguna variable de resultado. En aplicaciones de regresión, asegúrese de no seleccionar observaciones basadas en una variable dependiente, como el rendimiento más alto de las acciones, porque esto es estratificar basado en el \(y\), no en el \(x\). El Capítulo 6 discutirá los procedimientos de muestreo con mayor detalle.
El muestreo estratificado también proporciona motivación para el supuesto F4, la independencia entre respuestas. Se puede motivar el supuesto F1 pensando en \((x_i,y_i)\) como una extracción de una población, donde la media de la distribución condicional de \(y_i\) dado {\(x_i\)} es lineal en la variable explicativa. El supuesto F3 se conoce como homocedasticidad, que discutiremos ampliamente en la Sección 5.7. Ver Goldberger (1991) para más información sobre esta representación.
Un quinto supuesto que a menudo se usa implícitamente es: \[ \text{F5}. \{y_i\} \text{ están distribuidos normalmente}. \] Este supuesto no es necesario para muchos procedimientos de inferencia estadística porque los teoremas del límite central proporcionan normalidad aproximada para muchas estadísticas de interés. Sin embargo, la justificación formal para algunas, como las estadísticas \(t\), requieren este supuesto adicional.
En contraste con la representación observable, un conjunto alternativo de supuestos se enfoca en las desviaciones, o “errores”, en la regresión, definidos como \(\varepsilon_i=y_i-\left( \beta_0 + \beta_1 x_i \right)\).
\[ {\small \begin{array}{l} \hline \hline &\textbf{Modelo Básico de Regresión Lineal} \\ &\textbf{Supuestos de Muestreo de la Representación de Error} \\ \hline \text{E1}. & y_i=\beta_0 + \beta_1 x_i + \varepsilon_i . \\ \text{E2}. & \{x_1,\ldots ,x_n\} \text{ son variables no estocásticas}. \\ \text{E3}. & \mathrm{E}~\varepsilon_i=0 \text{ y } \mathrm{Var}~\varepsilon_i=\sigma ^{2}. \\ \text{E4}. & \{ \varepsilon_i\} \text{ son variables aleatorias independientes}. \\ \hline\ \end{array} } \]
La “representación de error” se basa en la teoría gaussiana de errores (ver Stigler, 1986, para un contexto histórico). El supuesto E1 asume que \(y\) es en parte debido a una función lineal de la variable explicativa observada, \(x\). Otras variables no observadas que influyen en la medición de \(y\) se interpretan como incluidas en el término de “error” \(\varepsilon_i\), que también se conoce como el término de “perturbación”. La independencia de errores, E4, puede motivarse asumiendo que {\(\varepsilon_i\)} se realizan a través de una muestra aleatoria simple de una población desconocida de errores.
Los supuestos E1-E4 son equivalentes a F1-F4. La representación de error proporciona una base útil para motivar las medidas de ajuste (Sección 2.3). Sin embargo, una desventaja de la representación de error es que desvía la atención de las cantidades observables \((x_i,y_i)\) a una cantidad no observable, {\(\varepsilon_i\)}. Para ilustrar, la base de muestreo, ver {\(\varepsilon_i\)} como una muestra aleatoria simple, no es directamente verificable porque no se puede observar directamente la muestra {\(\varepsilon_i\)}. Además, el supuesto de errores aditivos en E1 será problemático cuando consideremos modelos de regresión no lineales.
La Figura 2.4 ilustra algunos de los supuestos del modelo básico de regresión lineal. Los datos (\(x_1,y_1\)), (\(x_2,y_2\)) y (\(x_3,y_3\)) son observados y se representan con los símbolos de trazado circulares opacos. Según el modelo, estas observaciones deben estar cerca de la línea de regresión \(\mathrm{E}~y = \beta_0 + \beta_1 x\). Cada desviación de la línea es aleatoria. A menudo asumimos que la distribución de desviaciones puede representarse por una curva normal, como en la Figura 2.4.
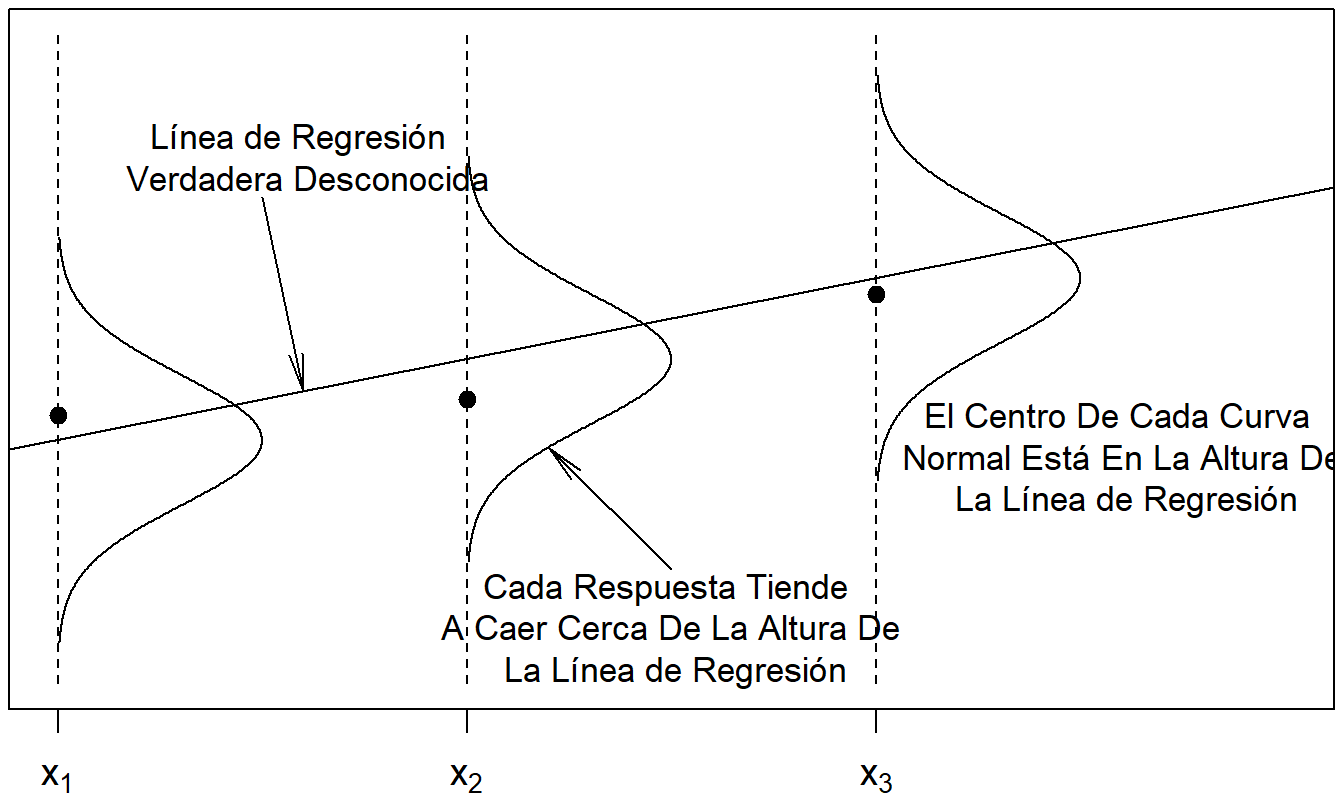
Figura 2.4: La distribución de la respuesta varía según el nivel de la variable explicativa.
Los supuestos del modelo básico de regresión lineal describen la población subyacente. Tabla 2.2 destaca la idea de que las características de esta población pueden resumirse mediante los parámetros \(\beta_0\), \(\beta_1\) y \(\sigma ^{2}\). En la Sección 2.1, resumimos datos de una muestra, introduciendo las estadísticas \(b_0\) y \(b_1\). La Sección 2.3 introducirá \(s^{2}\), la estadística correspondiente al parámetro \(\sigma ^{2}\).
Tabla 2.2. Medidas Resumen de la Población y la Muestra
\[ {\small \begin{array}{llccc}\hline\hline & \text{Resumen} \\ \text{Datos} & \text{Medidas} & \text{Intercepto} & \text{Pendiente} & \text{Varianza} \\\hline \text{Población} & \text{Parámetros} & \beta_0 & \beta_1 & \sigma^2 \\ \text{Muestra} & \text{Estadísticas} & b_0 & b_1 & s^2 \\ \hline \end{array} } \]
2.3 ¿Es Útil el Modelo? Algunas Medidas de Resumen Básicas
Aunque la estadística es la ciencia de resumir datos, también es el arte de argumentar con datos. Esta sección desarrolla algunas de las herramientas básicas usadas para justificar el modelo de regresión lineal básica. Un diagrama de dispersión puede proporcionar una fuerte evidencia visual de que \(x\) influye en \(y\); desarrollar evidencia numérica nos permitirá cuantificar la fuerza de la relación. Además, la evidencia numérica será útil cuando consideremos otros conjuntos de datos donde la evidencia gráfica no sea convincente.
2.3.1 Particionando la Variabilidad
Las desviaciones cuadradas, \(\left( y_i-\overline{y}\right) ^2\), proporcionan una base para medir la dispersión de los datos. Si deseamos estimar la \(i\)-ésima variable dependiente sin conocimiento de \(x\), entonces \(\overline{y}\) es una estimación adecuada y \(y_i- \overline{y}\) representa la desviación de la estimación. Usamos \(Total~SS=\sum_{i=1}^{n}\left( y_i-\overline{y}\right) ^2\), la suma total de cuadrados, para representar la variación en todas las respuestas.
Supongamos ahora que también tenemos conocimiento de \(x\), una variable explicativa. Usando la línea de regresión ajustada, para cada observación podemos calcular el valor ajustado correspondiente, \(\widehat{y}_i = b_0 + b_1x_i\). El valor ajustado es nuestra estimación con conocimiento de la variable explicativa. Como antes, la diferencia entre la respuesta y el valor ajustado, \(y_i- \widehat{y}_i\), representa la desviación de esta estimación. Ahora tenemos dos “estimaciones” de \(y_i\), que son \(\widehat{y}_i\) y \(\overline{y}\). Presumiblemente, si la línea de regresión es útil, entonces \(\widehat{y}_i\) es una medida más precisa que \(\overline{y}\). Para juzgar esta utilidad, descomponemos algebraicamente la desviación total como:
\[\begin{equation} {\small \begin{array}{ccccc} \underbrace{y_i-\overline{y}} & = & \underbrace{y_i-\widehat{y}_i} & + & \underbrace{\widehat{y}_i-\overline{y}} \\ \text{desviación} & = & \text{desviación} & + & \text{desviación} \\ \text{total} & & \text{no explicada} & & \text{explicada} \\ \end{array} \tag{2.1} } \end{equation}\] Interpreta esta ecuación como “la desviación sin conocimiento de \(x\) es igual a la desviación con conocimiento de \(x\) más la desviación explicada por \(x\).” La Figura 2.5 es una representación geométrica de esta descomposición. En la figura, se eligió una observación por encima de la línea, lo que da una desviación positiva de la línea de regresión ajustada, para hacer que el gráfico sea más fácil de leer. Un buen ejercicio es hacer un boceto aproximado correspondiente a la Figura 2.5 con una observación por debajo de la línea de regresión ajustada.
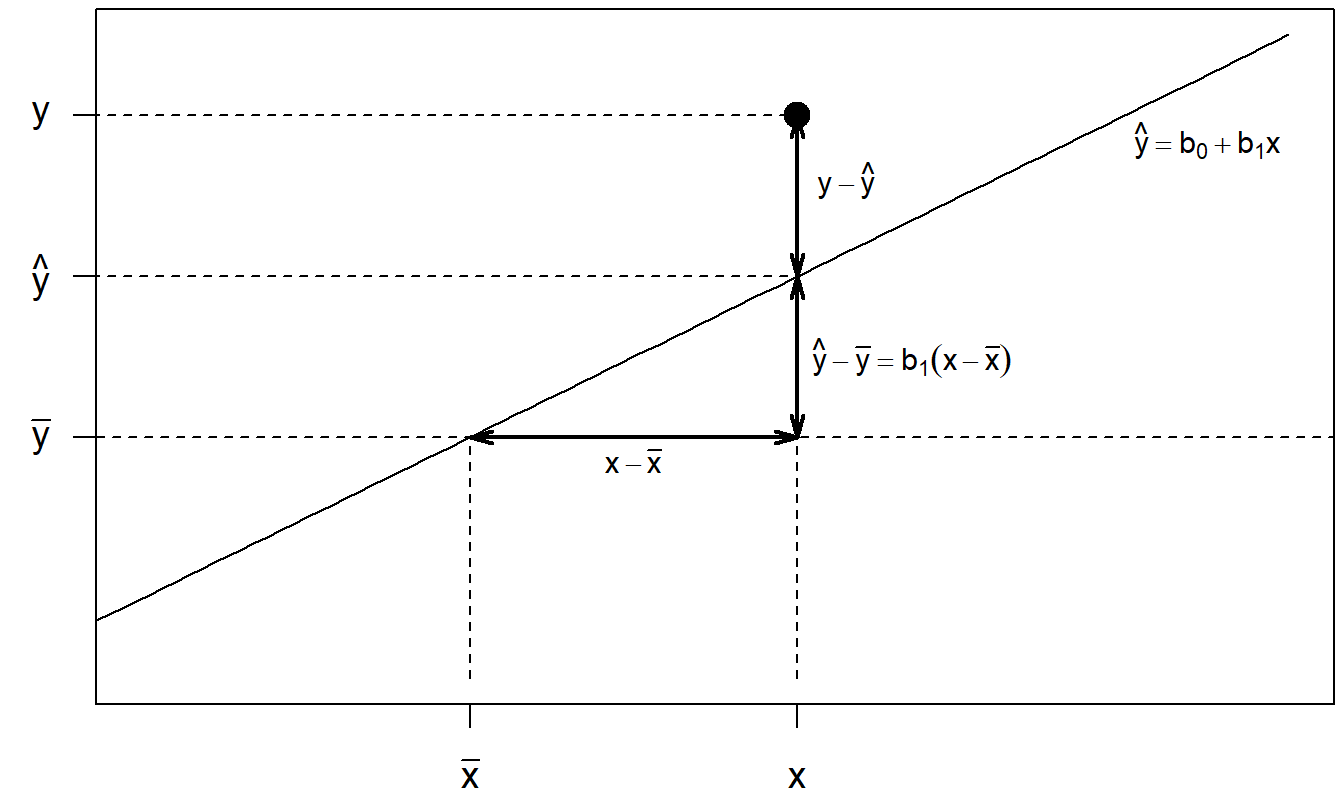
Figura 2.5: Representación geométrica de la descomposición de la desviación.
Ahora, a partir de la descomposición algebraica en la ecuación (2.1), eleva al cuadrado cada lado de la ecuación y suma sobre todas las observaciones. Después de un poco de manipulación algebraica, esto da como resultado \[\begin{equation} \sum_{i=1}^{n}\left( y_i-\overline{y}\right) ^2=\sum_{i=1}^{n}\left( y_i-\widehat{y}_i\right) ^2+\sum_{i=1}^{n}\left( \widehat{y}_i- \overline{y}\right) ^2. \tag{2.2} \end{equation}\] Reescribimos esto como \(Total~SS=Error~SS+Regression~SS\) donde \(SS\) significa suma de cuadrados. Interpretamos:
\(Total~SS\) como la variación total sin conocimiento de \(x\),
\(Error~SS\) como la variación total que queda después de introducir \(x\), y
\(Regression~SS\) como la diferencia entre el \(Total~SS\) y el \(Error~SS\), o la variación total “explicada” mediante el conocimiento de \(x\).
Al elevar al cuadrado el lado derecho de la ecuación (2.1), tenemos el término de producto cruzado \(2\left(y_i-\widehat{y}_i\right) \left( \widehat{y}_i-\overline{y}\right)\). Con la “manipulación algebraica”, se puede comprobar que la suma de los productos cruzados sobre todas las observaciones es cero. Este resultado no es cierto para todas las líneas ajustadas, pero es una propiedad especial de la línea ajustada por mínimos cuadrados.
En muchos casos, la descomposición de la variabilidad se reporta a través de un solo estadístico.
Definición. El coeficiente de determinación se denota por el símbolo \(R^2\), llamado “\(R\)-cuadrado”, y se define como \[ R^2=\frac{Regression~SS}{Total~SS}. \]
Interpretamos \(R^2\) como la proporción de variabilidad explicada por la línea de regresión. En un caso extremo donde la línea de regresión se ajusta perfectamente a los datos, tenemos \(Error~SS=0\) y \(R^2=1\). En el otro caso extremo donde la línea de regresión no proporciona ninguna información sobre la respuesta, tenemos \(Regression~SS=0\) y \(R^2=0\). El coeficiente de determinación está limitado por las desigualdades \(0 \leq R^2 \leq 1\) con valores mayores que implican un mejor ajuste.
2.3.2 El Tamaño de una Desviación Típica: s
En el modelo de regresión lineal básica, la desviación de la respuesta de la línea de regresión, \(y_i-\left( \beta_0+\beta_1x_i\right)\), no es una cantidad observable porque los parámetros \(\beta_0\) y \(\beta_1\) no son observados. Sin embargo, usando los estimadores \(b_0\) y \(b_1\), podemos aproximar esta desviación usando \[ e_i=y_i-\widehat{y}_i=y_i-\left( b_0+b_1x_i\right) , \] conocido como el residuo.
Los residuos serán cruciales para desarrollar estrategias para mejorar la especificación del modelo en la Sección 2.6. Ahora mostramos cómo usar los residuos para estimar \(\sigma ^2\). De un primer curso en estadística, sabemos que si se pudieran observar las desviaciones \(\varepsilon_i\), entonces una estimación deseable de \(\sigma ^2\) sería \((n-1)^{-1}\sum_{i=1}^{n}\left( \varepsilon _i-\overline{\varepsilon }\right) ^2\). Como \(\{\varepsilon_i\}\) no se observan, usamos lo siguiente.
Definición. Un estimador de \(\sigma ^2\), el error cuadrático medio (MSE), se define como \[\begin{equation} s^2=\frac{1}{n-2}\sum_{i=1}^{n}e_i{}^2. \tag{2.3} \end{equation}\] La raíz cuadrada positiva, \(s=\sqrt{s^2},\) se llama la desviación estándar residual.
Comparando las definiciones de \(s^2\) y \((n-1)^{-1}\sum_{i=1}^{n}\left( \varepsilon_i-\overline{\varepsilon }\right) ^2\), verá dos diferencias importantes. Primero, al definir \(s^2\) no hemos restado el residuo promedio de cada residuo antes de elevar al cuadrado. Esto se debe a que el residuo promedio es cero, una propiedad especial de la estimación de mínimos cuadrados (ver Ejercicio 2.14). Este resultado se puede mostrar usando álgebra y está garantizado para todos los conjuntos de datos.
En segundo lugar, al definir \(s^2\) hemos dividido por \(n-2\) en lugar de \(n-1\). Intuitivamente, dividir por \(n\) o \(n-1\) tiende a subestimar \(\sigma ^2\). La razón es que, al ajustar líneas a los datos, necesitamos al menos dos observaciones para determinar una línea. Por ejemplo, debemos tener al menos tres observaciones para que haya alguna variabilidad alrededor de una línea. ¿Cuánta “libertad” hay para la variabilidad alrededor de una línea? Diremos que los grados de libertad del error son el número de observaciones disponibles, \(n\), menos el número de observaciones necesarias para determinar una línea, 2 (con símbolos, \(df=n-2\)). Sin embargo, como vimos en la subsección de estimación de mínimos cuadrados, no necesitamos identificar dos observaciones reales para determinar una línea. La idea es que si un analista conoce la línea y \(n-2\) observaciones, entonces las dos observaciones restantes se pueden determinar, sin variabilidad. Al dividir por \(n-2\), se puede mostrar que \(s^2\) es un estimador insesgado de \(\sigma ^2\).
También podemos expresar \(s^2\) en términos de las sumas de cuadrados. Es decir,
\[ s^2=\frac{1}{n-2}\sum_{i=1}^{n}\left( y_i-\widehat{y}_i\right) ^2= \frac{Error~SS}{n-2}=MSE. \]
Esto nos lleva a la tabla de análisis de varianza o ANOVA:
\[ {\small \begin{array}{llcl} \hline \hline \text{Tabla ANOVA} \\ \hline \text{Fuente} & \text{Suma de Cuadrados} & df & \text{Cuadrado Medio} \\ \hline \text{Regresión} & Regression~SS & 1 & Regression~MS \\ \text{Error} & Error~SS & n-2 & MSE \\ \text{Total} & Total~SS & n-1 & \\ \hline \hline \end{array} } \]
La tabla ANOVA es simplemente un dispositivo de contabilidad utilizado para hacer un seguimiento de las fuentes de variabilidad; aparece rutinariamente en paquetes de software estadístico como parte de los resultados de la regresión. Las figuras de la columna de cuadrados medios se definen como las sumas de cuadrados (\(SS\)) divididas por sus respectivos grados de libertad (\(df\)). En particular, el cuadrado medio de los errores (\(MSE\)) es igual a \(s^2\) y la suma de cuadrados de la regresión es igual al cuadrado medio de la regresión. Esta última propiedad es específica para la regresión con una variable; no es cierta cuando consideramos más de una variable explicativa.
Los grados de libertad del error en la tabla ANOVA son \(n-2\). Los grados de libertad totales son \(n-1\), lo que refleja el hecho de que la suma total de cuadrados se centra en la media (se requieren al menos dos observaciones para una variabilidad positiva). El grado de libertad único asociado con la parte de regresión significa que la pendiente, más una observación, es suficiente información para determinar la línea. Esto se debe a que se necesitan dos observaciones para determinar una línea y al menos tres observaciones para que haya alguna variabilidad alrededor de la línea.
La tabla de análisis de varianza para los datos de la lotería es:
| Suma de Cuadrados | \(df\) | Cuadrado Medio | |
|---|---|---|---|
| Regresión | 2,527,165,015 | 1 | 2,527,165,015 |
| Error | 690,116,755 | 48 | 14,377,432 |
| Total | 3,217,281,770 | 49 |
Código R para Producir la Tabla ANOVA de Lotería
De esta tabla, puede verificar que \(R^2=78.5\%\) y \(s=3,792.\)
2.4 Propiedades de los Estimadores del Coeficiente de Regresión
Las estimaciones de mínimos cuadrados se pueden expresar como una suma ponderada de las respuestas. Para ver esto, define los pesos \[ w_i=\frac{x_i-\overline{x}}{s_x^2(n-1)}. \] Como la suma de las desviaciones de \(x\) (\(x_i-\overline{x}\)) es cero, vemos que \(\sum_{i=1}^{n}w_i=0\). Así, podemos expresar la estimación de la pendiente \[\begin{equation} b_1=r\frac{s_y}{s_x}=\frac{1}{(n-1)s_x^2}\sum_{i=1}^{n}\left( x_i-\overline{x}\right) \left( y_i-\overline{y}\right) =\sum_{i=1}^{n}w_i\left( y_i-\overline{y}\right) =\sum_{i=1}^{n}w_iy_i. \tag{2.4} \end{equation}\]
Los ejercicios piden al lector verificar que \(b_0\) también puede expresarse como una suma ponderada de las respuestas, por lo que nuestra discusión se refiere a ambos coeficientes de regresión. Dado que los coeficientes de regresión son sumas ponderadas de respuestas, pueden verse afectados drásticamente por observaciones inusuales (ver Sección 2.6).
Como \(b_1\) es una suma ponderada, es sencillo derivar la esperanza y la varianza de esta estadística. Por la linealidad de las esperanzas y la Suposición F1, tenemos \[ \mathrm{E}~b_1=\sum_{i=1}^{n}w_i~\mathrm{E}~y_i=\beta_0\sum_{i=1}^{n}w_i+\beta_1\sum_{i=1}^{n}w_ix_i=\beta_1. \] Es decir, \(b_1\) es un estimador imparcial de \(\beta_1\). Aquí, la suma \(\sum_{i=1}^{n}w_ix_i\) \(=\) \(\left[ s_x^2(n-1)\right] ^{-1}\sum_{i=1}^{n}\left( x_i-\overline{x}\right) x_i\) \(=\left[s_x^2(n-1)\right] ^{-1}\sum_{i=1}^{n}\left( x_i-\overline{x}\right) ^2=1.\) A partir de la definición de los pesos, una sencilla algebra también muestra que \(\sum_{i=1}^{n}w_i^2=1/\left( s_x^2(n-1)\right)\). Además, la independencia de las respuestas implica que la varianza de la suma es la suma de las varianzas, y así tenemos \[ \mathrm{Var}~b_1 =\sum_{i=1}^{n}w_i^2\mathrm{Var}~y_i=\frac{\sigma^2}{s_x^2(n-1)}. \] Sustituyendo \(\sigma ^2\) por su estimador \(s^2\) y tomando raíces cuadradas se obtiene lo siguiente.
Definición. El error estándar de \(b_1\), la desviación estándar estimada de \(b_1\), se define como \[\begin{equation} se(b_1)=\frac{s}{s_x\sqrt{n-1}}. \tag{2.5} \end{equation}\]
Esta es nuestra medida de la fiabilidad, o precisión, del estimador de la pendiente. Usando la ecuación (2.5), vemos que \(se(b_1)\) está determinado por tres cantidades: \(n\), \(s\) y \(s_x\), de la siguiente manera:
- Si tenemos más observaciones, de manera que \(n\) sea mayor, entonces \(se(b_1)\) será menor, manteniendo todo lo demás constante.
- Si las observaciones tienen una mayor tendencia a estar más cerca de la línea, de manera que \(s\) sea menor, entonces \(se(b_1)\) será menor, manteniendo todo lo demás constante.
- Si los valores de la variable explicativa están más dispersos, de manera que \(s_x\) aumenta, entonces \(se(b_1)\) será menor, manteniendo todo lo demás constante.
Valores menores de \(se(b_1)\) ofrecen una mejor oportunidad para detectar relaciones entre \(y\) y \(x\). La Figura 2.6 ilustra estas relaciones. Aquí, el diagrama de dispersión en el medio tiene el valor más pequeño de \(se(b_1)\). Comparado con el gráfico del medio, el gráfico de la izquierda tiene un valor mayor de \(s\) y por lo tanto \(se(b_1)\). Comparado con el gráfico de la derecha, el gráfico del medio tiene un valor mayor de \(s_x\), y por lo tanto un valor menor de \(se(b_1)\).
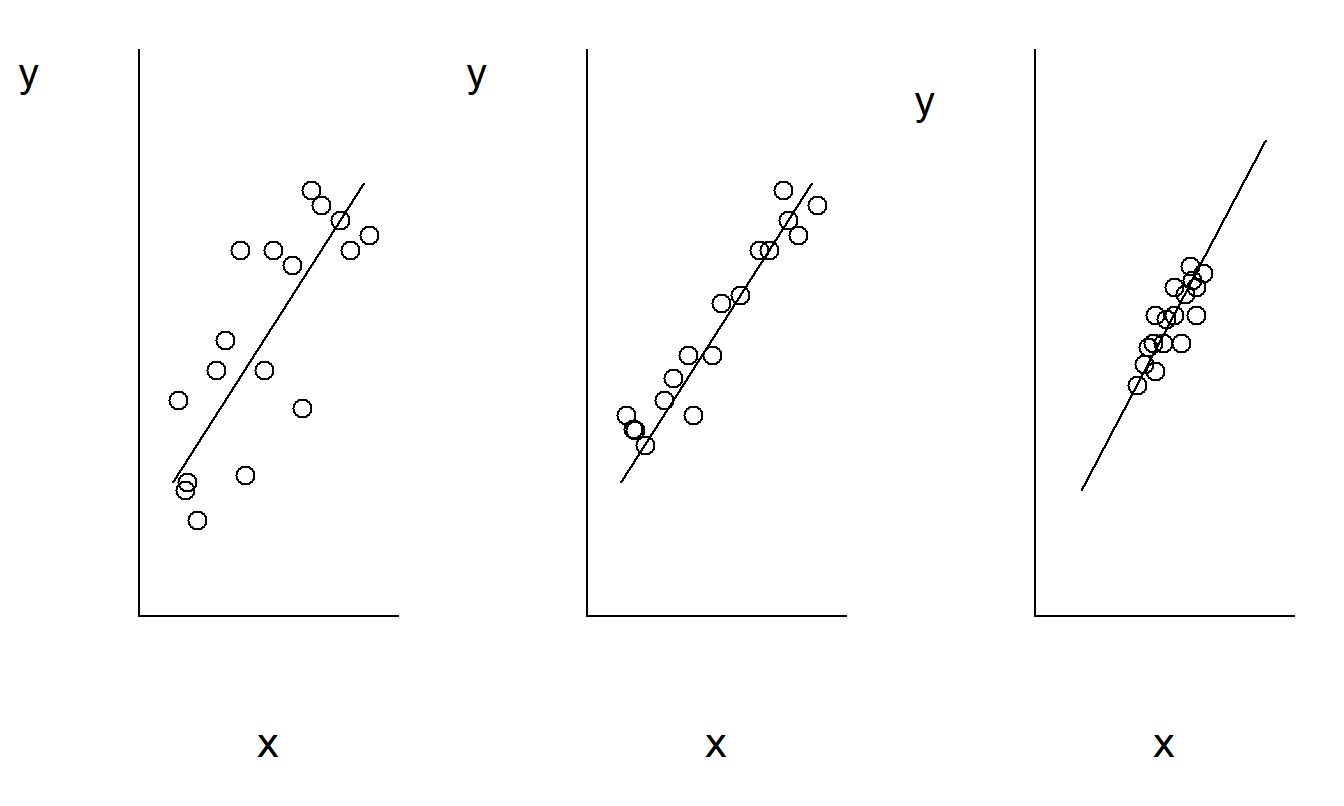
Figura 2.6: Estos tres diagramas de dispersión muestran la misma relación lineal entre \(y\) y \(x\). El gráfico a la izquierda muestra una mayor variabilidad alrededor de la línea que el gráfico del medio. El gráfico a la derecha muestra una desviación estándar menor en \(x\) que el gráfico del medio.
Código R para producir la Figura 2.6
La ecuación (2.4) también implica que el coeficiente de regresión \(b_1\) sigue una distribución normal. Es decir, recordemos de la estadística matemática que las combinaciones lineales de variables aleatorias normales también son normales. Así, si se cumple la Suposición F5, entonces \(b_1\) sigue una distribución normal. Además, existen varias versiones de los teoremas del límite central para sumas ponderadas (ver, por ejemplo, Serfling, 1980). Así, como se discute en la Sección 1.4, si las respuestas \(y_i\) están siquiera aproximadamente distribuidas normalmente, entonces será razonable usar una aproximación normal para la distribución muestral de \(b_1\). Usando \(se(b_1)\) como la desviación estándar estimada de \(b_1\), para valores grandes de \(n\) tenemos que \(\left( b_1-\beta_1\right) /se(b_1)\) tiene una distribución normal estándar aproximada. Aunque no lo probaremos aquí, bajo la Suposición F5 \(\left( b_1-\beta_1\right) /se(b_1)\) sigue una distribución \(t\) con grados de libertad \(df=n-2\).
2.5 Inferencia Estadística
Una vez que hemos ajustado un modelo con un conjunto de datos, podemos hacer una serie de afirmaciones importantes. Generalmente, es útil pensar en estas afirmaciones en tres categorías: (i) pruebas de ideas hipotetizadas, (ii) estimaciones de parámetros del modelo y (iii) predicciones de nuevos resultados.
2.5.1 ¿Es Importante la Variable Explicativa?: La Prueba t
Respondemos a la pregunta de si la variable explicativa es importante investigando si \(\beta_1=0\). La lógica es que si \(\beta_1=0\), entonces el modelo de regresión lineal básico ya no incluye una variable explicativa \(x\). Por lo tanto, traducimos nuestra pregunta sobre la importancia de la variable explicativa en una pregunta más específica que puede ser respondida utilizando el marco de pruebas de hipótesis. Esta pregunta más específica es: ¿es válida la hipótesis nula \(H_0:\beta_1=0\)? Respondemos a esta pregunta observando la estadística de prueba:
\[ {\small t-\mathrm{ratio}=\frac{\mathrm{valor~estimado~del~parámetro~-~valor~hipotetizado}} {\mathrm{error~estándar~del~estimador}}. } \]
En el caso de \(H_0:\beta_1=0\), examinamos la razón t \(t(b_1)=b_1/se(b_1)\) porque el valor hipotetizado de \(\beta_1\) es 0. Esta es la estandarización apropiada porque, bajo la hipótesis nula y las suposiciones del modelo descritas en la Sección 2.4, la distribución muestral de \(t(b_1)\) se puede demostrar que sigue una distribución t con \(df=n-2\) grados de libertad. Así, para probar la hipótesis nula \(H_0\) contra la alternativa \(H_{a}:\beta_1\neq 0\), rechazamos \(H_0\) a favor de \(H_{a}\) si \(|t(b_1)|\) excede un valor t. Aquí, este valor t es un percentil de la distribución t usando \(df=n-2\) grados de libertad. Denotamos el nivel de significancia como \(\alpha\) y este valor t como \(t_{n-2,1-\alpha /2}\).
Ejemplo: Ventas de Lotería - Continuación. Para el ejemplo de ventas de lotería, la desviación estándar residual es \(s=3,792\). En la Tabla 2.1, tenemos \(s_x = 11,098\). Por lo tanto, el error estándar de la pendiente es \(se(b_1) = 3792/(11098\sqrt{50-1})=0.0488\). Según la Sección 2.1, la estimación de la pendiente es \(b_1=0.647\). Por lo tanto, la estadística t es \(t(b_1) = 0.647/0.0488 = 13.4\). Interpretamos esto diciendo que la pendiente está 13.4 errores estándar por encima de cero. Para el nivel de significancia, usamos el valor habitual de \(\alpha\) = 5%. El percentil 97.5 de una distribución t con \(df=50-2=48\) grados de libertad es \(t_{48,0.975}=2.011\). Dado que \(|13.4|>2.011\), rechazamos la hipótesis nula de que la pendiente \(\beta_1 = 0\) a favor de la alternativa de que \(\beta_1 \neq 0\).
Tomar decisiones comparando una razón t con un valor t se llama una prueba t. Probar \(H_0:\beta_1=0\) frente a \(H_{a}:\beta_1\neq 0\) es solo una de las muchas pruebas de hipótesis que se pueden realizar, aunque es la más común. Tabla 2.3 describe procedimientos alternativos para la toma de decisiones. Estos procedimientos son para probar \(H_0:\beta_1 = d\) donde \(d\) es un valor prescrito por el usuario que puede ser igual a cero o cualquier otro valor conocido. Por ejemplo, en nuestro ejemplo de la Sección 2.7, usaremos \(d=1\) para probar teorías financieras sobre el mercado de valores.
Tabla 2.3 Procedimientos de Toma de Decisiones para Probar \(H_0:\beta_1 = d\)
\[ {\small \begin{array}{c|c} \hline \text{Hipótesis Alternativa } (H_{a}) & \text{Procedimiento: Rechazar } H_0 \text{ a favor de } H_{a} \text{ si} \\ \hline \beta_1>d & t-\mathrm{ratio}>t_{n-2,1-\alpha }. \\ \beta_1<d & t-\mathrm{ratio}<-t_{n-2,1-\alpha }. \\ \beta_1\neq d & |t-\mathrm{ratio}\mathit{|}>t_{n-2,1-\alpha /2}. \\ \end{array} }\\ {\small \begin{array}{l} \hline \text{Notas: El nivel de significancia es } \alpha . \text{Aquí, }t_{n-2,1-\alpha} \text{ es el percentil } (1-\alpha )\\ ~~\text{de la distribución }t \text{ con } df=n-2 \text{ grados de libertad.}\\ ~~\text{La estadística de prueba es }t-\mathrm{ratio} = (b_1 -d)/se(b_1) . \\ \hline \end{array} } \]
Alternativamente, se pueden construir valores de probabilidad (\(p\)-) y compararlos con los niveles de significancia dados. El valor \(p\)- es una estadística resumen útil para el analista de datos ya que permite al lector del informe entender la fuerza de la desviación de la hipótesis nula. Tabla 2.4 resume el procedimiento para calcular los valores \(p\)-.
Tabla 2.4 Valores de Probabilidad para Probar \(H_0:\beta_1 = d\)
\[ {\small \begin{array}{c|ccc} \hline \text{Hipótesis} & & & \\ \text{Alternativa } (H_a) & \beta_1>d & \beta_1<d & \beta_1\neq d \\ \hline p-value & \Pr(t_{n-2}>t-\mathrm{ratio}) & \Pr(t_{n-2}<t-\mathrm{ratio}) & \Pr (|t_{n-2}|>|t-\mathrm{ratio}\mathit{|}) \\\hline \end{array} }\\ {\small \begin{array}{l} \hline \text{Notas: Aquí, }t_{n-2} \text{ es una variable aleatoria distribuida como }t \text{ con } df=n-2 \text{ grados de libertad.}\\ ~~\text{La estadística de prueba es }t-\mathrm{ratio} = (b_1 -d)/se(b_1) . \\ \hline \end{array} } \]
Otra forma interesante de abordar la cuestión de la importancia de una variable explicativa es a través del coeficiente de correlación. Recuerda que el coeficiente de correlación es una medida de la relación lineal entre \(x\) e \(y\). Denotemos esta estadística por \(r(y,x)\). Esta cantidad no se ve afectada por cambios de escala en ninguna de las variables. Por ejemplo, si multiplicamos la variable \(x\) por el número \(b_1\), entonces el coeficiente de correlación permanece sin cambios. Además, las correlaciones no cambian con los desplazamientos aditivos. Así, si agregamos un número, digamos \(b_0\), a cada variable \(x\), entonces el coeficiente de correlación permanece sin cambios. Usar un cambio de escala y un desplazamiento aditivo en la variable \(x\) puede utilizarse para producir el valor ajustado \(\widehat{y}=b_0+b_1x\). Por lo tanto, usando la notación, tenemos \(|r(y,x)|=r(y,\widehat{y})\). Así, podemos interpretar que la correlación entre las respuestas y la variable explicativa es igual a la correlación entre las respuestas y los valores ajustados. Esto lleva al siguiente hecho algebraico interesante: \(R^2=r^2.\) Es decir, el coeficiente de determinación es igual al cuadrado del coeficiente de correlación. Esto es mucho más fácil de interpretar si uno piensa en \(r\) como la correlación entre los valores observados y los ajustados. Consulta el Ejercicio 2.13 para los pasos útiles para confirmar este resultado.
2.5.2 Intervalos de Confianza
Los investigadores a menudo citan el mecanismo formal de pruebas de hipótesis para responder a la pregunta: “¿Tiene la variable explicativa una influencia real en la respuesta?” Una pregunta de seguimiento natural es: “¿En qué medida afecta \(x\) a \(y\)?” Hasta cierto punto, se puede responder utilizando el tamaño del \(t\)-ratio o el valor de \(p\). Sin embargo, en muchos casos, un intervalo de confianza para la pendiente es más útil.
Para introducir los intervalos de confianza para la pendiente, recordemos que \(b_1\) es nuestro estimador puntual de la verdadera pendiente desconocida \(\beta_1\). La Sección 2.4 argumentó que este estimador tiene un error estándar \(se(b_1)\) y que \(\left( b_1-\beta_1\right) /se(b_1)\) sigue una distribución \(t\) con \(n-2\) grados de libertad. Las declaraciones de probabilidad se pueden invertir para obtener intervalos de confianza. Usando esta lógica, tenemos el siguiente intervalo de confianza para la pendiente \(\beta_1\).
Definición. Un intervalo de confianza del \(100(1-\alpha)\)% para la pendiente \(\beta_1\) es \[\begin{equation} b_1\pm t_{n-2,1-\alpha /2} ~se(b_1). \tag{2.6} \end{equation}\]
Al igual que con las pruebas de hipótesis, \(t_{n-2,1-\alpha /2}\) es el percentil (1-\(\alpha\) /2) de la distribución \(t\) con \(df=n-2\) grados de libertad. Debido a la naturaleza bilateral de los intervalos de confianza, el percentil es 1 - (1 - nivel de confianza) / 2. En este texto, por simplicidad, generalmente usamos un intervalo de confianza del 95%, por lo que el percentil es 1-(1-0.95)/2 = 0.975. El intervalo de confianza proporciona un rango de confiabilidad que mide la utilidad de la estimación.
En la Sección 2.1, establecimos que la estimación de la pendiente por mínimos cuadrados para el ejemplo de ventas de lotería es \(b_1=0.647\). La interpretación es que si la población de un código postal difiere en 1,000, entonces esperamos que las ventas promedio de lotería difieran en $647. ¿Qué tan confiable es esta estimación? Resulta que \(se(b_1)=0.0488\) y, por lo tanto, un intervalo de confianza aproximado del 95% para la pendiente es \[ 0.647\pm (2.011)(.0488), \] o (0.549, 0.745). De manera similar, si la población difiere en 1,000, un intervalo de confianza del 95% para el cambio esperado en las ventas es (549, 745). Aquí, usamos el valor \(t\) \(t_{48,0.975}=2.011\) porque hay 48 (= \(n\)-2) grados de libertad y, para un intervalo de confianza del 95%, necesitamos el percentil 97.5.
2.5.3 Intervalos de Predicción
En la Sección 2.1, mostramos cómo usar los estimadores de mínimos cuadrados para predecir las ventas de lotería para un código postal, fuera de nuestra muestra, con una población de 10,000. Dado que la predicción es una tarea tan importante para los actuarios, formalizamos el procedimiento para que pueda ser utilizado regularmente.
Para predecir una observación adicional, asumimos que el nivel de la variable explicativa es conocido y se denota por \(x_{\ast}\). Por ejemplo, en nuestro ejemplo anterior de ventas de lotería usamos \(x_{\ast} = 10,000\). También asumimos que la observación adicional sigue el mismo modelo de regresión lineal que las observaciones en la muestra.
Usando nuestros estimadores de mínimos cuadrados, nuestra predicción puntual es \(\widehat{y}_{\ast} = b_0 + b_1 x_{\ast}\), la altura de la línea de regresión ajustada en \(x_{\ast}\). Podemos descomponer el error de predicción en dos partes:
\[ \begin{array}{ccccc} \underbrace{y_{\ast} - \widehat{y}_{\ast}} & = & \underbrace{\beta_0 - b_0 + \left( \beta_1 - b_1 \right) x_{\ast}} & + & \underbrace{\varepsilon_{\ast}} \\ {\small \text{error de predicción}} & {\small =} & {\small \text{error en la estimación de la }} & {\small +} & {\small \text{desviación de la observación adicional}} \\ & & {\small \text{línea de regresión en } x}_{\ast} & & {\small \text{respuesta de su media}} \end{array} \]
Se puede demostrar que el error estándar de la predicción es \[ se(pred) = s \sqrt{1+\frac{1}{n}+\frac{\left( x_{\ast}-\overline{x}\right) ^2}{(n-1)s_x^2}}. \] Al igual que con \(se(b_1)\), los términos \(n^{-1}\) y \(\left(x_{\ast}-\overline{x} \right) ^2/\left[ (n-1)s_x^2\right]\) se acercan a cero a medida que el tamaño de la muestra \(n\) se vuelve grande. Por lo tanto, para grandes \(n\), tenemos que \(se(pred)\approx s\), lo que refleja que el error en la estimación de la línea de regresión en un punto se vuelve insignificante y la desviación de la respuesta adicional de su media se convierte en la única fuente de incertidumbre.
Definición. Un intervalo de predicción del \(100(1-\alpha)\)% en \(x_{\ast}\) es \[\begin{equation} \widehat{y}_{\ast} \pm t_{n-2,1-\alpha /2} ~se(pred) \tag{2.7} \end{equation}\] donde el valor \(t\) \(t_{n-2,1-\alpha /2}\) es el mismo que se usa para la prueba de hipótesis y el intervalo de confianza.
Por ejemplo, la predicción puntual en \(x_{\ast} = 10,000\) es \(\widehat{y}_{\ast}\)= 469.7 + 0.647 (10000) = 6,939.7. El error estándar de esta predicción es \[ se(pred) = 3,792 \sqrt{1+\frac{1}{50} + \frac{\left( 10,000-9,311\right)^2}{(50-1)(11,098)^2}} = 3,829.6. \] Con un valor \(t\) igual a 2.011, esto da lugar a un intervalo de predicción aproximado del 95% \[ 6,939.7 \pm (2.011)(3,829.6) = 6,939.7 \pm 7,701.3 = (-761.6, ~14,641.0). \] Interpretamos estos resultados señalando primero que nuestra mejor estimación de ventas de lotería para un código postal con una población de 10,000 es 6,939.70. Nuestro intervalo de predicción del 95% representa un rango de confiabilidad para esta predicción. Si pudiéramos observar muchos códigos postales, cada uno con una población de 10,000, en promedio esperaríamos que aproximadamente 19 de cada 20, o el 95%, tendrían ventas de lotería entre 0 y 14,641. Es habitual truncar el límite inferior del intervalo de predicción a cero si se considera que los valores negativos de la respuesta son inapropiados.
Código R para producir los análisis de la Sección 2.5
2.6 Construyendo un Mejor Modelo: Análisis de Residuos
Las disciplinas cuantitativas calibran modelos con datos. La estadística lleva esto un paso más allá, utilizando las discrepancias entre las suposiciones y los datos para mejorar la especificación del modelo. Examinaremos las suposiciones del modelo de la Sección 2.2 a la luz de los datos y utilizaremos cualquier desajuste para especificar un mejor modelo; este proceso se conoce como verificación diagnóstica (como cuando vas al médico y él o ella realiza pruebas diagnósticas para revisar tu salud).
Comenzaremos con la representación del error de la Sección 2.2. Bajo este conjunto de suposiciones, las desviaciones {\(\varepsilon_i\)} son idénticamente e independientemente distribuidas (i.i.d), y bajo la suposición F5, distribuidas normalmente. Para evaluar la validez de estas suposiciones, se usan los residuos (observados) {\(e_i\)} como aproximaciones para las desviaciones (no observadas) {\(\varepsilon_i\)}. El tema básico es que si los residuos están relacionados con una variable o muestran algún otro patrón reconocible, entonces deberíamos poder aprovechar esta información y mejorar la especificación de nuestro modelo. Los residuos deberían contener poca o ninguna información y representar solo la variación natural de la muestra que no se puede atribuir a ninguna fuente específica. Análisis de residuos es el ejercicio de verificar los residuos en busca de patrones.
Existen cinco tipos de discrepancias en el modelo que los analistas comúnmente buscan. Si se detectan, las discrepancias pueden corregirse con los ajustes apropiados en la especificación del modelo.
Problemas de Especificación del Modelo
- Falta de Independencia. Puede haber relaciones entre las desviaciones {\(\varepsilon_i\)} de modo que no sean independientes.
- Heterocedasticidad. La suposición E3 indica que todas las observaciones tienen una variabilidad común (aunque desconocida), conocida como homocedasticidad. Heterocedasticidad es el término usado cuando la variabilidad varía según la observación.
- Relaciones entre Desviaciones del Modelo y Variables Explicativas. Si una variable explicativa tiene la capacidad de ayudar a explicar la desviación \(\varepsilon\), entonces deberíamos poder usar esta información para predecir mejor \(y\).
- Distribuciones No Normales. Si la distribución de la desviación representa una desviación seria de la normalidad, entonces los procedimientos de inferencia usuales ya no son válidos.
- Puntos Inusuales. Las observaciones individuales pueden tener un gran efecto en el ajuste del modelo de regresión, lo que significa que los resultados pueden ser sensibles al impacto de una sola observación.
Esta lista servirá al lector durante el estudio del análisis de regresión. Por supuesto, con solo una introducción a los modelos básicos aún no hemos visto modelos alternativos que podrían usarse cuando encontramos estas discrepancias en el modelo. En la Parte II de este libro sobre modelos de series temporales, estudiaremos la falta de independencia entre datos ordenados en el tiempo. El Capítulo 5 considerará la heterocedasticidad con más detalle. La introducción a la regresión lineal múltiple en el Capítulo 3 será nuestra primera vista sobre cómo manejar las relaciones entre {\(\varepsilon_i\)} y variables explicativas adicionales. Sin embargo, ya hemos tenido una introducción al efecto de las distribuciones normales, viendo que los gráficos \(qq\) pueden detectar la no normalidad y que las transformaciones pueden ayudar a inducir la normalidad aproximada. En esta sección, discutimos los efectos de los puntos inusuales.
Gran parte del análisis de residuos se realiza examinando un residuo estandarizado, que es un residuo dividido por su error estándar. Un error estándar aproximado del residuo es \(s\); en el Capítulo 3 daremos una definición matemática precisa. Hay dos razones por las que a menudo examinamos residuos estandarizados en lugar de residuos básicos. Primero, si las respuestas están distribuidas normalmente, entonces los residuos estandarizados son aproximadamente realizaciones de una distribución normal estándar. Esto proporciona una distribución de referencia para comparar los valores de los residuos estandarizados. Por ejemplo, si un residuo estandarizado supera dos en valor absoluto, esto se considera inusualmente grande y la observación se llama outlier (punto atípico). Segundo, dado que los residuos estandarizados son adimensionales, podemos transferir la experiencia de un conjunto de datos a otro. Esto es cierto independientemente de si la distribución de referencia normal es aplicable o no.
Puntos Atípicos y Puntos de Alta Influencia
Otra parte importante del análisis de residuos es la identificación de observaciones inusuales en un conjunto de datos. Debido a que las estimaciones de regresión son promedios ponderados con pesos que varían según la observación, algunas observaciones son más importantes que otras. Esta ponderación es más importante de lo que muchos usuarios del análisis de regresión se dan cuenta. De hecho, el ejemplo a continuación demuestra que una sola observación puede tener un efecto dramático en un gran conjunto de datos.
Hay dos direcciones en las que un punto de datos puede ser inusual: la dirección horizontal y la dirección vertical. Por “inusual”, nos referimos a que una observación bajo consideración parece estar lejos de la mayoría del conjunto de datos. Una observación que es inusual en la dirección vertical se llama punto atípico. Una observación que es inusual en la dirección horizontal se llama punto de alta influencia. Una observación puede ser tanto un punto atípico como un punto de alta influencia.
Ejemplo: Puntos Atípicos y Puntos de Alta Influencia. Considera el conjunto de datos ficticio de 19 puntos más tres puntos, etiquetados como A, B y C, que se muestra en la Figura 2.7 y Tabla 2.5. Piensa en los primeros 19 puntos como observaciones “buenas” que representan algún tipo de fenómeno. Queremos investigar el efecto de agregar un solo punto aberrante.
Tabla 2.5. 19 Puntos Base Más Tres Tipos de Observaciones Inusuales
\[ \small{ \begin{array}{c|cccccccccc|ccc} \hline Variables & &&&&&&&&& & A & B & C \\ \hline x & 1.5 & 1.7 & 2.0 & 2.2 & 2.5 & 2.5 & 2.7 & 2.9 & 3.0 & 3.5 & 3.4 & 9.5 & 9.5 \\ y & 3.0 & 2.5 & 3.5 & 3.0 & 3.1 & 3.6 & 3.2 & 3.9 & 4.0 & 4.0 & 8.0 & 8.0 & 2.5 \\ \hline x & 3.8 & 4.2 & 4.3 & 4.6 & 4.0 & 5.1 & 5.1 & 5.2 & 5.5 & & & & \\ y & 4.2 & 4.1 & 4.8 & 4.2 & 5.1 & 5.1 & 5.1 & 4.8 & 5.3 & & & & \\ \hline \end{array} } \]
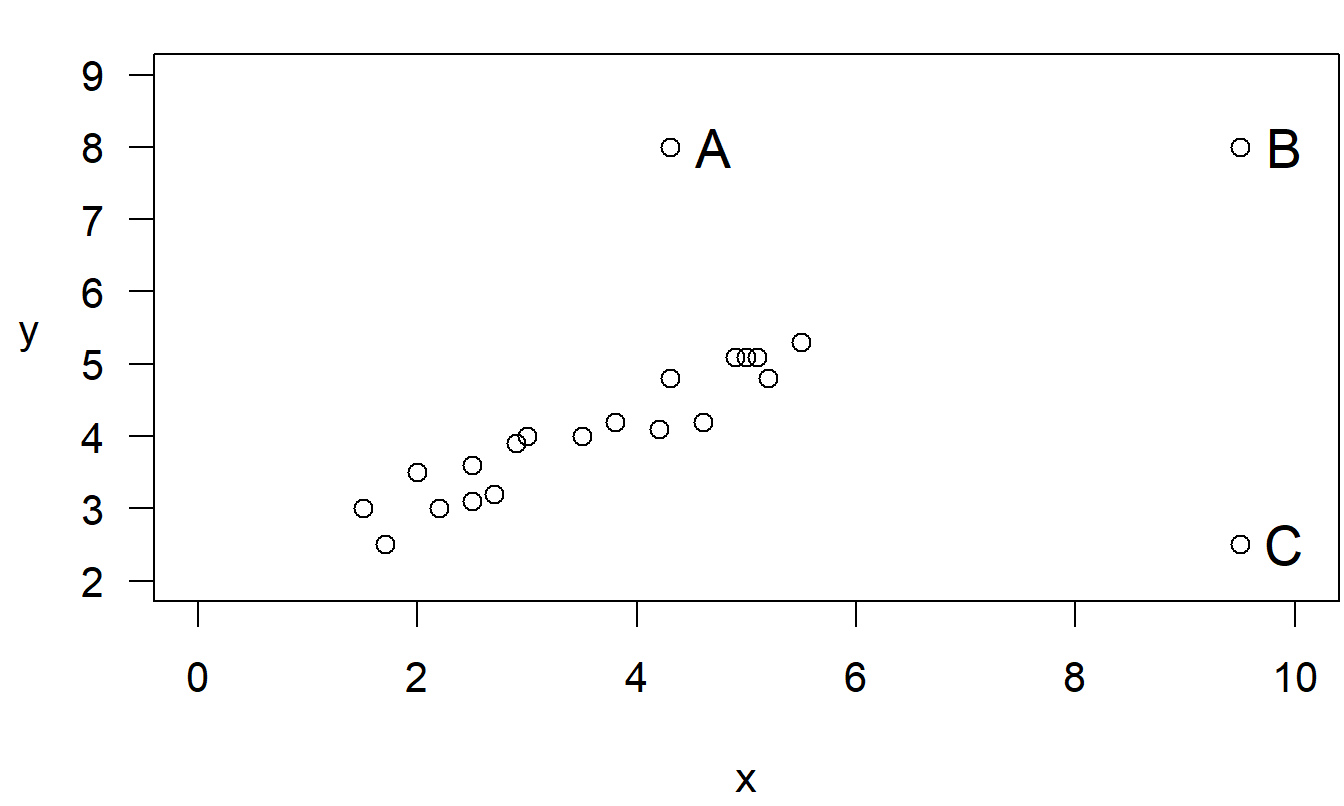
Figura 2.7: Gráfico de dispersión de 19 puntos base más tres puntos inusuales, etiquetados A, B, y C.
Código R para Producir la Figura 2.7
Para investigar el efecto de cada tipo de punto aberrante, Tabla 2.6 resume los resultados de cuatro regresiones separadas. La primera regresión es para los diecinueve puntos base. Las otras tres regresiones utilizan los diecinueve puntos base más cada tipo de observación inusual.
Tabla 2.6. Resultados de Cuatro Regresiones
\[ {\small \begin{array}{l|rrrrr} \hline Datos & b_0 & b_1 & s & R^2(\%) & t(b_1) \\ \hline 19 \text{ Puntos Base} & 1.869 & 0.611 & 0.288 & 89.0 & 11.71 \\ 19 \text{ Puntos Base} ~+~ A & 1.750 & 0.693 & 0.846 & 53.7 & 4.57 \\ 19 \text{ Puntos Base} ~+~ B & 1.775 & 0.640 & 0.285 & 94.7 & 18.01 \\ 19 \text{ Puntos Base} ~+~ C & 3.356 & 0.155 & 0.865 & 10.3 & 1.44 \\ \hline \end{array} } \]
Tabla 2.6 muestra que una línea de regresión proporciona un buen ajuste para los diecinueve puntos base. El coeficiente de determinación, \(R^2\), indica que alrededor del 89% de la variabilidad ha sido explicada por la línea. El tamaño del error típico, \(s\), es de aproximadamente 0.29, pequeño en comparación con la dispersión en los valores de \(y\). Además, el cociente \(t\) para el coeficiente de la pendiente es grande.
Cuando se agrega el punto atípico A a los diecinueve puntos base, la situación empeora dramáticamente. El \(R^2\) baja del 89% al 53.7% y \(s\) aumenta de aproximadamente 0.29 a alrededor de 0.85. La línea de regresión ajustada en sí no cambia mucho, aunque nuestra confianza en las estimaciones ha disminuido.
Un punto atípico es inusual en el valor de \(y\), pero “inusual en el valor de \(y\)” depende del valor de \(x\). Para ver esto, mantén el valor de \(y\) del Punto A igual, pero aumenta el valor de \(x\) y llama al punto B.
Cuando se agrega el punto B a los diecinueve puntos base, la línea de regresión proporciona un ajuste mejor. El punto B está cerca de estar en la línea de ajuste de regresión generada por los diecinueve puntos base. Así, la línea de regresión ajustada y el tamaño del error típico, \(s\), no cambian mucho. Sin embargo, \(R^2\) aumenta del 89% a casi el 95%. Si pensamos en \(R^2\) como \(1-(Error~SS)/(Total~SS)\), al agregar el punto B hemos aumentado \(Total~SS\), la desviación total cuadrada en los \(y\), aunque el \(Error~SS\) se mantiene relativamente sin cambios. El punto B no es un punto atípico, pero es un punto de alta influencia.
Para mostrar cuán influyente es este punto, reduce considerablemente el valor de \(y\) y llama a este el nuevo punto C. Cuando se agrega este punto a los diecinueve puntos base, la situación empeora dramáticamente. El coeficiente \(R^2\) baja del 89% al 10%, y el \(s\) más que se triplica, de 0.29 a 0.87. Además, los coeficientes de la línea de regresión cambian drásticamente.
La mayoría de los usuarios de la regresión al principio no creen que un punto de veinte pueda tener un efecto tan dramático en el ajuste de la regresión. El ajuste de una línea de regresión siempre puede mejorarse eliminando un punto atípico. Si el punto es un punto de alta influencia y no un punto atípico, no está claro si el ajuste mejorará cuando el punto sea eliminado.
¡Simplemente porque puedes mejorar dramáticamente un ajuste de regresión omitiendo una observación no significa que siempre debas hacerlo! El objetivo del análisis de datos es comprender la información en los datos. A lo largo del texto, encontraremos muchos conjuntos de datos donde los puntos inusuales proporcionan alguna de la información más interesante sobre los datos. El objetivo de esta subsección es reconocer los efectos de los puntos inusuales; el Capítulo 5 proporcionará opciones para manejar puntos inusuales en tu análisis.
Todas las disciplinas cuantitativas, como contabilidad, economía, programación lineal, etc., practican el arte del análisis de sensibilidad. El análisis de sensibilidad es una descripción de los cambios globales en un sistema debido a un pequeño cambio local en un elemento del sistema. Examinar los efectos de observaciones individuales en el ajuste de regresión es un tipo de análisis de sensibilidad.
Ejemplo: Ventas de Lotería – Continuación. La Figura 2.8 muestra un valor atípico; el punto en la parte superior izquierda del gráfico representa un código postal que incluye a Kenosha, Wisconsin. Las ventas para este código postal son inusualmente altas dada su población. Kenosha está cerca de la frontera con Illinois; los residentes de Illinois probablemente participen en la lotería de Wisconsin, lo que aumenta efectivamente el potencial de ventas en Kenosha. Tabla 2.7 resume el ajuste de la regresión tanto con como sin este código postal.
Tabla 2.7. Resultados de la Regresión con y sin Kenosha
\[ {\small \begin{array}{l|rrrrr} \hline \text{Datos} & b_0 & b_1 & s & R^2(\%) & t(b_1) \\ \hline \text{Con Kenosha} & 469.7 & 0.647 & 3,792 & 78.5 & 13.26 \\ \text{Sin Kenosha} & -43.5 & 0.662 & 2,728 & 88.3 & 18.82 \\ \hline \end{array} } \]
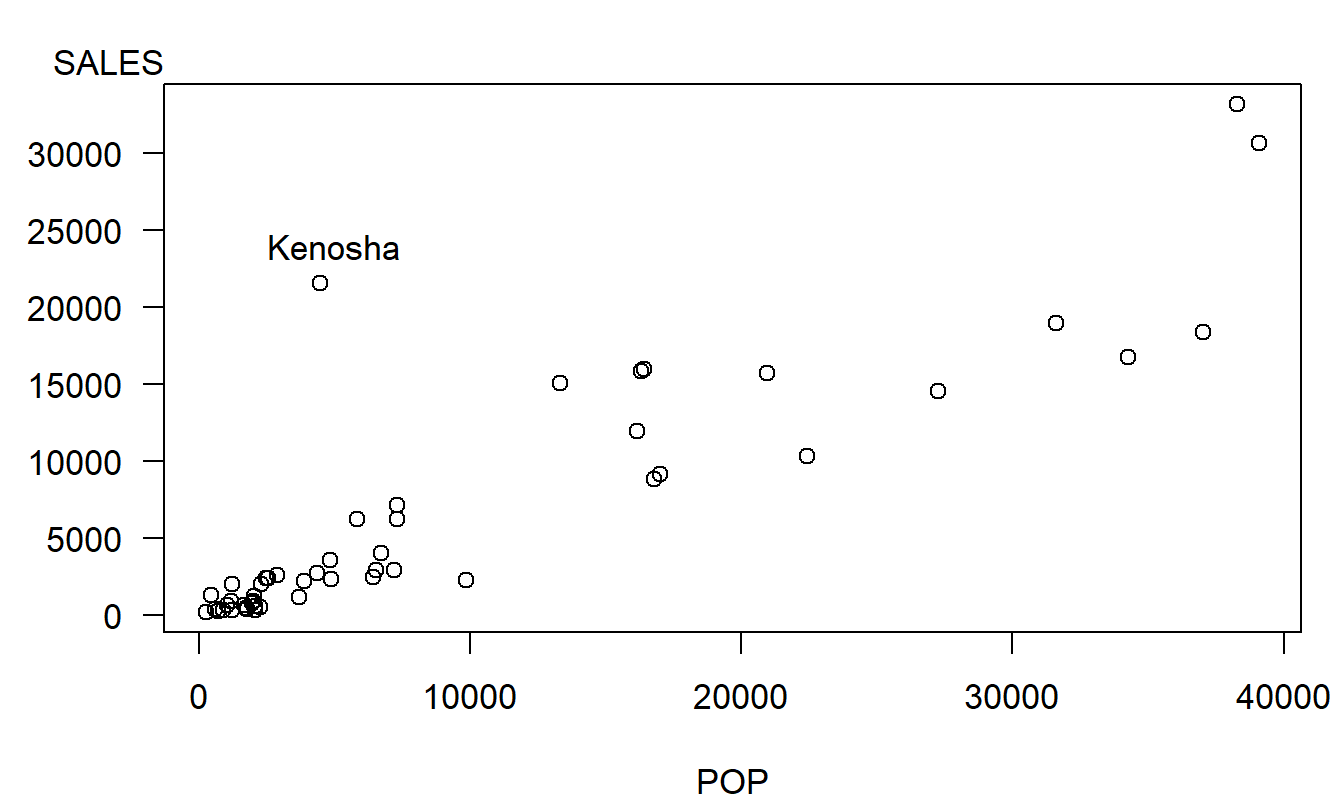
Figura 2.8: Gráfico de dispersión de SALES versus POP, con el valor atípico correspondiente a Kenosha marcado.
Código R para producir la Figura 2.8 y la Tabla 2.7
Para los propósitos de inferencia sobre la pendiente, la presencia de Kenosha no altera los resultados de manera dramática. Ambas estimaciones de la pendiente son cualitativamente similares y los correspondientes valores \(t\) son muy altos, muy por encima de los umbrales para la significancia estadística. Sin embargo, hay diferencias notables al evaluar la calidad del ajuste. El coeficiente de determinación, \(R^2\), aumentó del 78.5% al 88.3% al eliminar Kenosha. Además, nuestro “desviación típica” \(s\) disminuyó en más de $1,000. Esto es particularmente importante si queremos ajustar nuestros intervalos de predicción.
Para verificar la exactitud de nuestras suposiciones, también es común revisar la suposición de normalidad. Una forma de hacerlo es mediante el gráfico \(qq\), introducido en la Sección 1.2. Los dos paneles en las Figuras 2.9 son gráficos \(qq\) con y sin el código postal de Kenosha. Recuerda que los puntos “cercanos” a una línea indican normalidad aproximada. En el panel derecho de la Figura 2.9, la secuencia parece ser lineal, por lo que los residuos están aproximadamente distribuidos de manera normal. Este no es el caso en el panel izquierdo, donde la secuencia de puntos parece aumentar dramáticamente para grandes cuantiles. Lo interesante es que la no-normalidad de la distribución se debe a un solo valor atípico, no a un patrón de sesgo común a todas las observaciones.
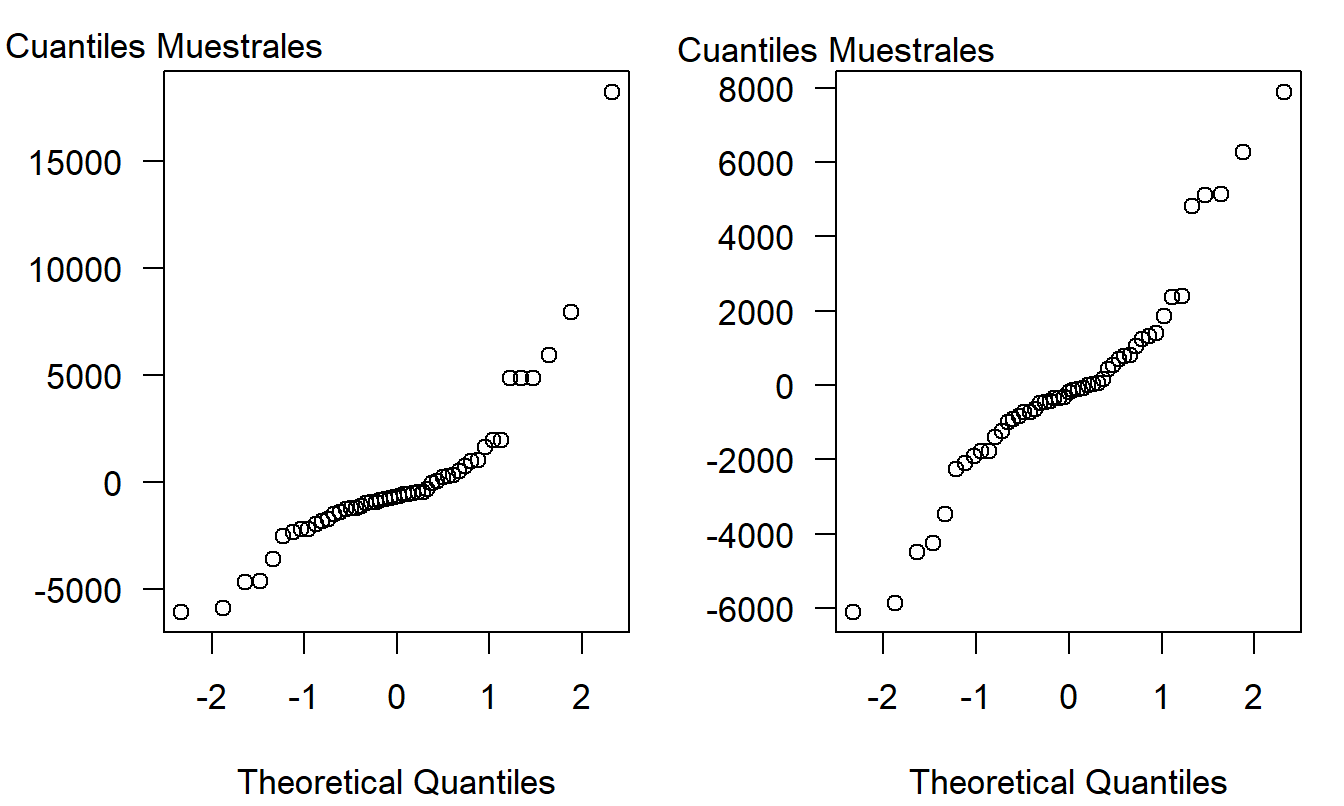
Figura 2.9: Gráficos \(qq\) de los residuos de la Lotería de Wisconsin. El panel izquierdo se basa en los 50 puntos. El panel derecho se basa en 49 puntos, residuos de una regresión después de eliminar Kenosha.
Código R para producir la Figura 2.9
2.7 Aplicación: Modelo de Valoración de Activos Financieros
En esta sección, estudiamos una aplicación financiera, el Modelo de Valoración de Activos Financieros, a menudo conocido por el acrónimo CAPM. El nombre es algo engañoso, ya que el modelo realmente trata sobre rendimientos basados en activos de capital, no sobre los precios en sí mismos. Los tipos de activos que examinamos son valores de acciones que se negocian en un mercado activo, como la Bolsa de Valores de Nueva York (NYSE). Para una acción en la bolsa, podemos relacionar los rendimientos con los precios mediante la siguiente expresión:
\[ {\small \mathrm{rendimiento =}\frac{\mathrm{precio~al~final~de~un~período+dividendos-precio~al~inicio~de~un~período}}{\mathrm{precio~al~inicio~de~un~período}}. } \]
Si podemos estimar los rendimientos que genera una acción, entonces el conocimiento del precio al inicio de un período financiero genérico nos permite estimar el valor al final del período (precio final más dividendos). Por lo tanto, seguimos la práctica estándar y modelamos los rendimientos de una acción.
Una idea intuitivamente atractiva, y una de las características básicas del CAPM, es que debería haber una relación entre el rendimiento de una acción y el mercado. Una justificación es simplemente que si las fuerzas económicas hacen que el mercado mejore, entonces esas mismas fuerzas deberían actuar sobre una acción individual, sugiriendo que también debería mejorar. Como se mencionó anteriormente, medimos el rendimiento de una acción a través del rendimiento. Para medir el rendimiento del mercado, existen varios índices de mercado que resumen el rendimiento de cada bolsa. Usaremos el índice “ponderado por igual” del Standard & Poor’s 500. El Standard & Poor’s 500 es la colección de las 500 empresas más grandes que se negocian en la NYSE, donde “grande” es identificado por Standard & Poor’s, una organización de calificación de servicios financieros. El índice ponderado por igual se define asumiendo que se crea una cartera invirtiendo un dólar en cada una de las 500 empresas.
Otra justificación para una relación entre los rendimientos de las acciones y el mercado proviene de la teoría de la economía financiera. Esta es la teoría CAPM, atribuida a Sharpe (1964) y Lintner (1965) y basada en las ideas de diversificación de cartera de Harry Markowitz (1959). Otros factores iguales, los inversionistas desearían seleccionar un rendimiento con un alto valor esperado y una baja desviación estándar, esta última siendo una medida de riesgo. Una de las propiedades deseables de usar desviaciones estándar como medida de riesgo es que es sencillo calcular la desviación estándar de una cartera. Solo es necesario conocer la desviación estándar de cada acción y las correlaciones entre acciones. Una acción notable es una libre de riesgo, es decir, una acción que teóricamente tiene una desviación estándar cero. Los inversionistas a menudo utilizan un bono del Tesoro de EE. UU. a 30 días como una aproximación de una acción libre de riesgo, argumentando que la probabilidad de default del gobierno de EE. UU. dentro de 30 días es insignificante. Positando la existencia de un activo libre de riesgo y algunas otras condiciones suaves, bajo la teoría CAPM existe una frontera eficiente llamada la línea de mercado de valores. Esta frontera especifica el rendimiento mínimo esperado que los inversionistas deberían exigir para un nivel específico de riesgo. Para estimar esta línea, podemos usar la ecuación: \[ \mathrm{E}~r = \beta_0 + \beta_1 r_m \] donde \(r\) es el rendimiento de la acción y \(r_m\) es el rendimiento del mercado. Interpretamos \(\beta_1 r_m\) como una medida de la cantidad de rendimiento de la acción que se atribuye al comportamiento del mercado.
Probar la teoría económica, o modelos que surgen de cualquier disciplina, implica recolectar datos. La teoría CAPM trata sobre rendimientos ex-ante (antes del hecho), aunque solo podemos probar con rendimientos ex-post (después del hecho). Antes del hecho, los rendimientos son desconocidos y hay toda una distribución de rendimientos. Después del hecho, solo hay una realización única del rendimiento de la acción y del mercado. Debido a que se requieren al menos dos observaciones para determinar una línea, los modelos CAPM se estiman usando datos de acciones y del mercado recopilados a lo largo del tiempo. De esta manera, se pueden realizar varias observaciones. Para los propósitos de nuestras discusiones, seguimos la práctica estándar en la industria de valores y examinamos precios mensuales.
Datos
Para ilustrar, considere los rendimientos mensuales durante el período de cinco años desde enero de 1986 hasta diciembre de 1990, inclusive. Específicamente, usamos los rendimientos de la acción de Lincoln National Insurance Corporation como la variable dependiente (\(y\)) y los rendimientos del mercado del índice Standard & Poor’s 500 como la variable explicativa (\(x\)). En ese momento, Lincoln era una gran compañía de seguros multirama, con sede en el medio oeste de EE. UU., específicamente en Fort Wayne, Indiana. Debido a que era bien conocida por su gestión prudente y estabilidad, es una buena compañía para comenzar nuestro análisis de la relación entre el mercado y una acción individual.
Comenzamos interpretando algunas estadísticas básicas, en la Tabla 2.8, en términos de teoría financiera. Primero, un inversionista en Lincoln estará preocupado de que el rendimiento promedio de cinco años, \(\overline{y}=0.00510\), esté por debajo del rendimiento del mercado, \(\overline{x}=0.00741\). Los estudiantes de teoría de intereses reconocen que los rendimientos mensuales se pueden convertir a una base anual usando la capitalización geométrica. Por ejemplo, el rendimiento anual de Lincoln es \((1.0051)^{12}-1=0.062946\), o aproximadamente 6.29 por ciento. Esto se compara con un rendimiento anual de 9.26% (= (1\(00((1.00741)^{12}-1\))) para el mercado. Una medida de riesgo, o volatilidad, que se usa en finanzas es la desviación estándar. Así, interprete \(s_y\) = 0.0859 \(>\) 0.05254 = \(s_x\) para significar que una inversión en Lincoln es más riesgosa que la del mercado. Otro aspecto interesante de la Tabla 2.8 es que el rendimiento más bajo del mercado, -0.22052, está 4.338 desviaciones estándar por debajo de su promedio ((-0.22052-0.00741)/0.05254 = -4.338). Esto es muy inusual con respecto a una distribución normal.
| Promedio | Mediana | Desviación Estándar | Mínimo | Máximo | |
|---|---|---|---|---|---|
| LINCOLN | 0.0051 | 0.0075 | 0.0859 | -0.2803 | 0.3147 |
| MARKET | 0.0074 | 0.0142 | 0.0525 | -0.2205 | 0.1275 |
| Fuente: Center for Research on Security Prices, University of Chicago |
A continuación, examinamos los datos a lo largo del tiempo, como se muestra gráficamente en la Figura 2.10. Estos son gráficos de dispersión de los rendimientos versus el tiempo, llamados gráficos de series temporales. En la Figura 2.10, se puede ver claramente el rendimiento más bajo del mercado y un vistazo rápido al eje horizontal revela que este punto inusual está en octubre de 1987, el momento del conocido colapso del mercado.
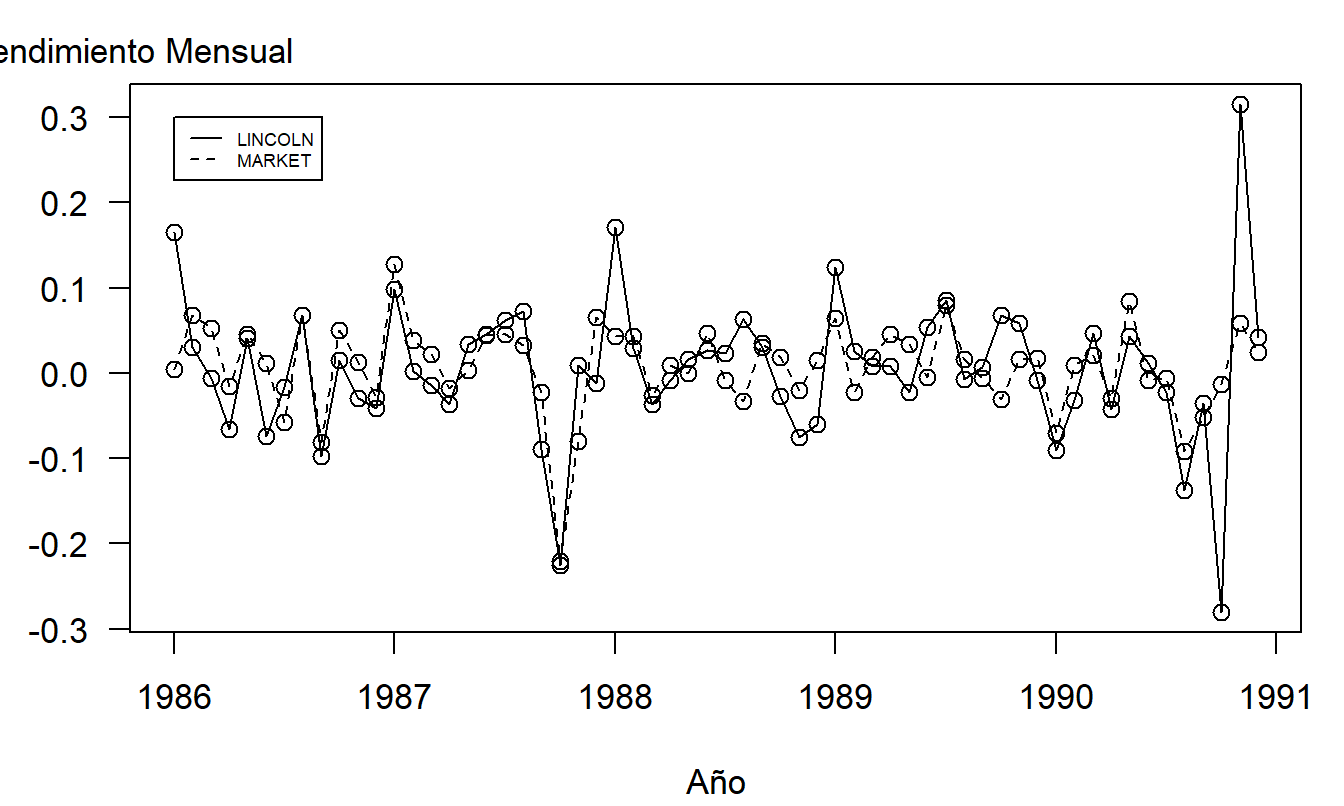
Figura 2.10: Gráfico de series temporales de los rendimientos de la Lincoln National Corporation y del mercado. Hay 60 rendimientos mensuales durante el período de enero de 1986 a diciembre de 1990.
El gráfico de dispersión en la Figura 2.11 resume gráficamente la relación entre el rendimiento de Lincoln y el rendimiento del mercado. El colapso del mercado es claramente evidente en la Figura 2.11 y representa un punto de alta influencia. Con la línea de regresión (descrita a continuación) superpuesta, los dos puntos atípicos que se pueden ver en la Figura 2.10 también son evidentes. A pesar de estas anomalías, el gráfico en la Figura 2.11 sugiere que hay una relación lineal entre los rendimientos de Lincoln y del mercado.
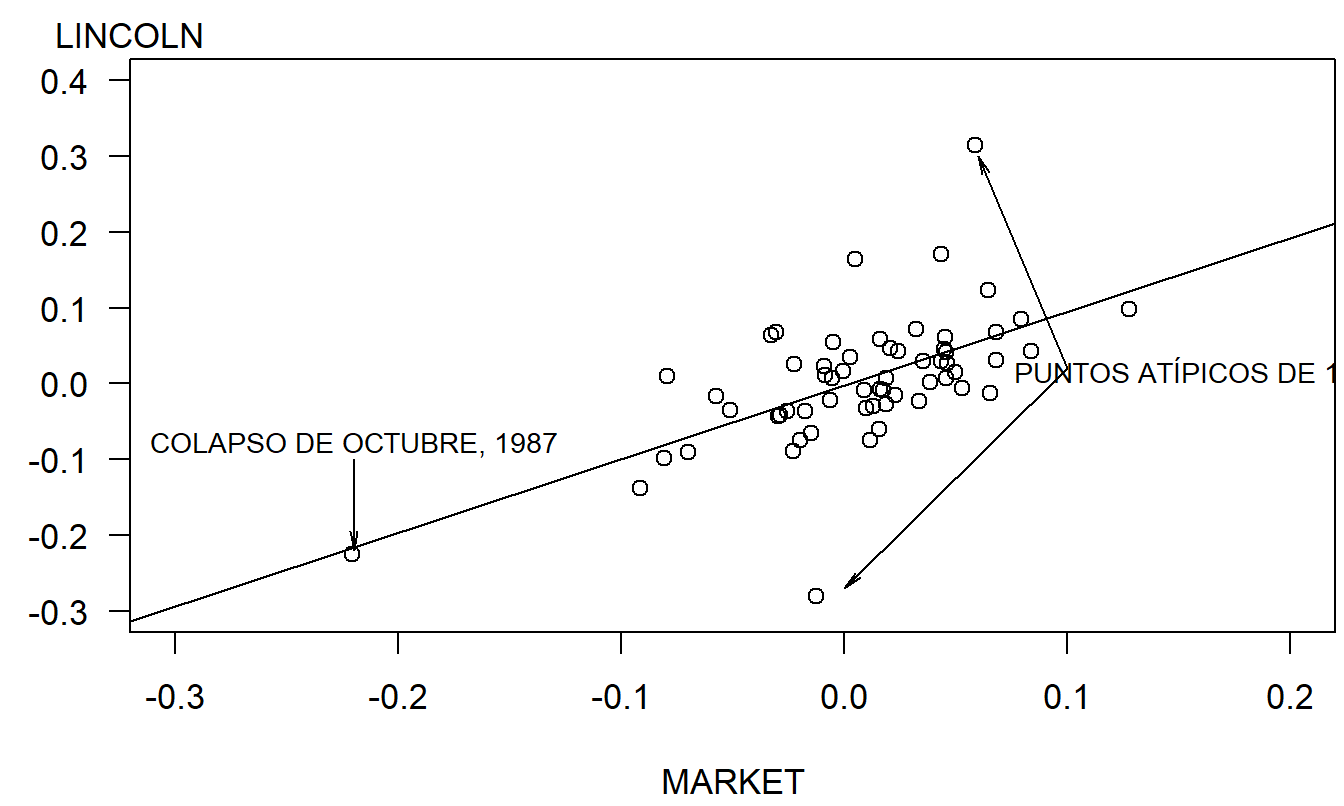
Figura 2.11: Gráfico de dispersión del rendimiento de Lincoln versus el rendimiento del índice S&P 500. La línea de regresión está superpuesta, lo que nos permite identificar el colapso del mercado y dos puntos atípicos.
Código R para producir la Tabla 2.8 y las Figuras 2.10 y 2.11
Puntos Inusuales
Para resumir la relación entre el mercado y el rendimiento de Lincoln, se ajustó un modelo de regresión. La regresión ajustada es
\[ \widehat{LINCOLN}=-0.00214+0.973 MARKET. \]
El error estándar estimado resultante, \(s = 0.0696\), es menor que la desviación estándar de los rendimientos de Lincoln, \(s_y=0.0859\). Por lo tanto, el modelo de regresión explica parte de la variabilidad de los rendimientos de Lincoln. Además, el estadístico \(t\) asociado con la pendiente \(b_1\) resulta ser \(t(b_1)=5.64\), lo cual es significativamente alto. Un aspecto decepcionante es que el estadístico \(R^2=35.4\%\) se puede interpretar como que el mercado explica solo un poco más de un tercio de la variabilidad. Por lo tanto, aunque el mercado es claramente un determinante importante, como lo evidencian el alto estadístico \(t\), solo proporciona una explicación parcial del rendimiento de los rendimientos de Lincoln.
En el contexto del modelo de mercado, podemos interpretar la desviación estándar del mercado, \(s_x\), como riesgo no diversificable. Por lo tanto, el riesgo de un valor puede descomponerse en dos componentes: el componente diversificable y el componente del mercado, que es no diversificable. La idea es que, al combinar varios valores, podemos crear una cartera de valores que, en la mayoría de los casos, reducirá el riesgo de nuestras inversiones en comparación con un solo valor. Nuevamente, la razón para tener un valor es que estamos compensados con rendimientos esperados más altos al tener un valor con mayor riesgo. Para cuantificar el riesgo relativo, no es difícil demostrar que
\[\begin{equation} s_y^2 = b_1^2 s_x^2 + s^2 \frac{n-2}{n-1}. \tag{2.8} \end{equation}\]
El riesgo de un valor se debe al riesgo del mercado más el riesgo de un componente diversificable. Tenga en cuenta que el riesgo del componente del mercado, \(s_x^2\), es mayor para los valores con pendientes más grandes. Por esta razón, los inversores consideran que los valores con pendientes \(b_1\) mayores que uno son “agresivos” y las pendientes menores que uno como “defensivos”.
Análisis de Sensibilidad
El resumen anterior plantea inmediatamente dos cuestiones adicionales. Primero, ¿cuál es el efecto del colapso de octubre de 1987 en la ecuación de regresión ajustada? Sabemos que las observaciones inusuales, como el colapso, pueden influir mucho en el ajuste. Con este fin, se volvió a ejecutar la regresión sin la observación correspondiente al colapso. La motivación para esto es que el colapso de octubre de 1987 representa una combinación de eventos altamente inusuales (la interacción de varios programas de comercio automatizado operados por grandes casas de corretaje de valores) que no deseamos representar con el mismo modelo que nuestras otras observaciones. Eliminando esta observación, la regresión ajustada es
\[ \widehat{LINCOLN} = -0.00181 + 0.956 MARKET, \]
con \(R^2=26.4\%\), \(t(b_1)=4.52\), \(s=0.0702\) y \(s_y=0.0811\). Interpretamos estas estadísticas de la misma manera que el modelo ajustado que incluye el colapso de octubre de 1987. Sin embargo, es interesante notar que la proporción de variabilidad explicada ha disminuido al excluir el punto influyente. Esto sirve para ilustrar un punto importante. Los puntos de alta influencia a menudo son temidos por los analistas de datos porque, por definición, son diferentes de otras observaciones en el conjunto de datos y requieren una atención especial. Sin embargo, al ajustar las relaciones entre variables, también representan una oportunidad porque permiten al analista de datos observar la relación entre variables en rangos más amplios que de otro modo serían posibles. La desventaja es que estas relaciones pueden ser no lineales o seguir un patrón completamente diferente en comparación con las relaciones observadas en la parte principal de los datos.
La segunda pregunta planteada por el análisis de regresión es qué se puede decir sobre las circunstancias inusuales que dieron lugar al comportamiento inusual de los rendimientos de Lincoln en octubre y noviembre de 1990. Una característica útil del análisis de regresión es identificar y plantear la pregunta; no la resuelve. Debido a que el análisis señala claramente dos puntos altamente inusuales, sugiere al analista de datos que vuelva y haga algunas preguntas específicas sobre las fuentes de los datos. En este caso, la respuesta es directa. En octubre de 1990, la compañía Travelers’ Insurance, una competidora, anunció que tomaría una gran amortización en su cartera de bienes raíces debido a un número sin precedentes de incumplimientos hipotecarios. El mercado reaccionó rápidamente a esta noticia, y los inversores asumieron que otras grandes compañías de seguros de vida también anunciarían pronto grandes amortizaciones. Anticipando esta noticia, los inversores trataron de vender sus carteras de, por ejemplo, las acciones de Lincoln, lo que provocó una caída en el precio. Sin embargo, resultó que los inversores reaccionaron en exceso a esta noticia y que la cartera de bienes raíces de Lincoln estaba en realidad en buen estado. Así, los precios rápidamente volvieron a sus niveles históricos.
2.8 Salida Computacional Ilustrativa de Regresión
Las computadoras y los paquetes de software estadístico que realizan cálculos especializados juegan un papel vital en los análisis estadísticos modernos. Las capacidades informáticas económicas han permitido a los analistas de datos centrarse en las relaciones de interés. Es mucho menos importante especificar modelos que sean atractivos únicamente por su simplicidad computacional en comparación con épocas anteriores a la disponibilidad generalizada de computación económica. Un tema importante de este texto es centrarse en las relaciones de interés y confiar en el software estadístico ampliamente disponible para estimar los modelos que especificamos.
Con cualquier paquete de computadora, generalmente las partes más difíciles de operar el paquete son (i) la entrada, (ii) el uso de los comandos y (iii) la interpretación de la salida. Encontrarás que la mayoría de los paquetes estadísticos modernos aceptan archivos en formato de hoja de cálculo o texto, lo que facilita la entrada de datos. Los paquetes de software estadístico para computadoras personales tienen lenguajes de comando basados en menús con facilidades de ayuda en línea fácilmente accesibles. Una vez que decides qué hacer, encontrar los comandos correctos es relativamente fácil.
Esta sección proporciona orientación para interpretar la salida de los paquetes estadísticos. La mayoría de los paquetes estadísticos generan salidas similares. A continuación, se presentan tres ejemplos de paquetes estadísticos estándar: EXCEL, SAS y R. El símbolo de anotación “[.]” marca una cantidad estadística que se describe en la leyenda. Así, esta sección proporciona un enlace entre la notación utilizada en el texto y la salida de algunos de los paquetes estadísticos estándar.
Salida en EXCEL
Regression Statistics
Multiple R 0.886283[F]
R Square 0.785497[k]
Adjusted R Square 0.781028[l]
Standard Error 3791.758[j]
Observations 50[a]
ANOVA
df SS MS F Significance F
Regression 1[m] 2527165015 [p] 2527165015 [s] 175.773[u] 1.15757E-17[v]
Residual 48[n] 690116754.8[q] 14377432.39[t]
Total 49[o] 3217281770 [r]
Coefficients Standard Error t Stat P-value
Intercept 469.7036[b] 702.9061896[d] 0.668230846[f] 0.507187[h]
X Variable 1 0.647095[c] 0.048808085[e] 13.25794257[g] 1.16E-17[i]El Sistema SAS
The REG Procedure
Dependent Variable: SALES
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 1[m] 2527165015[p] 2527165015[s] 175.77[u] <.0001[v]
Error 48[n] 690116755[q] 14377432[t]
Corrected Total 49[o] 3217281770[r]
Root MSE 3791.75848[j] R-Square 0.7855[k]
Dependent Mean 6494.82900[H] Adj R-Sq 0.7810[l]
Coeff Var 58.38119[I]
Parameter Estimates
Parameter Standard
Variable Label DF Estimate Error t Value Pr > |t|
Intercept Intercept 1 469.70360[b] 702.90619[d] 0.67[f] 0.5072[h]
POP POP 1 0.64709[c] 0.04881[e] 13.26[g] <.0001[i]Salida en R
Analysis of Variance Table
Response: SALES
Df Sum Sq Mean Sq F value Pr(>F)
POP 1[m] 2527165015[p] 2527165015[s] 175.77304[u] <2.22e-16[v]***
Residuals 48[n] 690116755[q] 14377432[t]
---
Call: lm(formula = SALES ~ POP)
Residuals:
Min 1Q Median 3Q Max
-6047 -1461 -670 486 18229
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 469.7036[b] 702.9062[d] 0.67[f] 0.51 [h]
POP 0.6471[c] 0.0488[e] 13.26[g] <2e-16 ***[i]
---
Signif. codes: 0 ?***? 0.001 ?**? 0.01 ?*? 0.05 ?.? 0.1 ? ? 1
Residual standard error: 3792[j] on 48[n] degrees of freedom
Multiple R-Squared: 0.785[k], Adjusted R-squared: 0.781[l]
F-statistic: 176[u] on 1[m] and 48[n] DF, p-value: <2e-16[v]Definición de Anotación de Leyenda, Símbolo
[a] Número de observaciones \(n\).
[b] La intersección estimada \(b_0\).
[c] La pendiente estimada \(b_1\).
[d] El error estándar de la intersección, \(se(b_0)\).
[e] El error estándar de la pendiente, \(se(b_1)\).
[f] El valor del \(t\) asociado con la intersección, \(t(b_0) = b_0/se(b_0)\).
[g] El valor del \(t\) asociado con la pendiente, \(t(b_1) = b_1/se(b_1)\).
[h] El valor \(p\) asociado con la intersección; aquí, \(p-value=Pr(|t_{n-2}|>|t(b_0)|)\), donde \(t(b_0)\) es el valor realizado (0.67 aquí) y \(t_{n-2}\) tiene una distribución \(t\) con \(df=n-2\).
[i] El valor \(p\) asociado con la pendiente; aquí, \(p-value=Pr(|t_{n-2}|>|t(b_1)|)\), donde \(t(b_1)\) es el valor realizado (13.26 aquí) y \(t_{n-2}\) tiene una distribución \(t\) con \(df=n-2\).
[j] La desviación estándar residual, \(s\).
[k] El coeficiente de determinación, \(R^2\).
[l] El coeficiente de determinación ajustado por grados de libertad, \(R_{a}^2\). (Este término se definirá en el Capítulo 3.)
[m] Grados de libertad para el componente de regresión. Esto es 1 para una variable explicativa.
[n] Grados de libertad para el componente de error, \(n-2\), para la regresión con una variable explicativa.
[o] Grados de libertad totales, \(n-1\).
[p] La suma de cuadrados de la regresión, \(Regression~SS\).
[q] La suma de cuadrados del error, \(Error~SS\).
[r] La suma total de cuadrados, \(Total~SS\).
[s] El cuadrado medio de la regresión, \(Regression~MS = Regression~SS/1\), para una variable explicativa.
[t] El cuadrado medio del error, \(s^2=Error~MS = Error~SS/(n-2)\), para una variable explicativa.
[u] El \(F-ratio=(Regression~MS)/(Error~MS)\). (Este término se definirá en el Capítulo 3.)
[v] El valor \(p\) asociado con el \(F-ratio\). (Este término se definirá en el Capítulo 3.)
[w] El número de observación, \(i\).
[x] El valor de la variable explicativa para la \(i\)-ésima observación, \(x_i\).
[y] La respuesta para la \(i\)-ésima observación, \(y_i\).
[z] El valor ajustado para la \(i\)-ésima observación, \(\widehat{y}_i\).
[A] El error estándar del ajuste, \(se(\widehat{y}_i)\).
[B] El residual para la \(i\)-ésima observación, \(e_i\).
[C] El residual estandarizado para la \(i\)-ésima observación, \(e_i/se(e_i)\). El error estándar \(se(e_i)\) se definirá en la Sección 5.3.1.
[F] El coeficiente de correlación múltiple es la raíz cuadrada del coeficiente de determinación, \(R=\sqrt{R^2}\). Esto se definirá en el Capítulo 3.
[G] El coeficiente estandarizado es \(b_1s_x/s_y\). Para regresión con una variable explicativa, esto es equivalente a \(r\), el coeficiente de correlación.
[H] La respuesta promedio, \(\overline{y}\).
[I] El coeficiente de variación de la respuesta es \(s_y/\overline{y}\). SAS imprime \(100s_y/\overline{y}\).
2.9 Lecturas Adicionales y Referencias
Relativamente pocas aplicaciones de la regresión son básicas en el sentido de que usan solo una variable explicativa; el propósito del análisis de regresión es reducir las relaciones complejas entre muchas variables. La Sección 2.7 describe una excepción importante a esta regla general, el modelo financiero CAPM; consulta a Panjer et al. (1998) para descripciones actuariales adicionales de este modelo. Campbell et al. (1997) ofrece una perspectiva desde la econometría financiera.
Referencias del Capítulo
- Anscombe, Frank (1973). Graphs in statistical analysis. The American Statistician 27, 17-21.
- Campbell, John Y., Andrew W. Lo and A. Craig MacKinlay (1997). The Econometrics of Financial Markets. Princeton University Press, Princeton, New Jersey.
- Frees, Edward W. and Tom W. Miller (2003). Sales forecasting using longitudinal data models. International Journal of Forecasting 20, 97-111.
- Goldberger, Arthur (1991). A Course in Econometrics. Harvard University Press, Cambridge.
- Koch, Gary J. (1985). A basic demonstration of the [-1, 1] range for the correlation coefficient. American Statistician 39, 201-202.
- Linter, J. (1965). The valuation of risky assets and the selection of risky investments in stock portfolios and capital budgets. Review of Economics and Statistics, 13-37.
- Manistre, B. John and Geoffrey H. Hancock (2005). Variance of the CTE estimator. North American Actuarial Journal 9(2), 129-156.
- Markowitz, Harry (1959). Portfolio Selection: Efficient Diversification of Investments. John Wiley, New York.
- Panjer, Harry H., Phelim P. Boyle, Samuel H. Cox, Daniel Dufresne, Hans U. Gerber, Heinz H. Mueller, Hal W. Pedersen, Stanley R. Pliska, Michael Sherris, Elias S. Shiu and Ken S. Tan (1998). Financial Economics: With Applications to Investment, Insurance and Pensions. Society of Actuaries, Schaumburg, Illinois.
- Pearson, Karl (1895). Royal Society Proceedings 58, 241.
- Serfling, Robert J. (1980). Approximation Theorems of Mathematical Statistics. John Wiley and Sons, New York.
- Sharpe, William F. (1964). Capital asset prices: A theory of market equilibrium under risk. Journal of Finance, 425-442.
- Stigler, Steven M. (1986). The History of Statistics: The Measurement of Uncertainty before 1900. Harvard University Press, Cambridge, MA.
2.10 Ejercicios
Secciones 2.1-2.2
2.1 Considera el siguiente conjunto de datos \[ \begin{array}{l|ccc} \hline i & 1 & 2 & 3 \\ \hline x_i & 2 & -6 & 7 \\ y_i & 3 & 4 & 6\\ \hline \end{array} \]
Ajusta una línea de regresión utilizando el método de mínimos cuadrados. Determina \(r\), \(b_1\) y \(b_0\).
2.2 Una relación perfecta, pero sin correlación. Considera la relación cuadrática \(y=x^2\), con datos
\[ \begin{array}{l|ccccc} \hline i & 1 & 2 & 3 & 4 & 5\\ \hline x_i & -2 & -1 & 0 & 1 & 2 \\ y_i & 4 & 1 & 0 & 1 & 4\\ \hline \end{array} \]
- Produce un gráfico aproximado para este conjunto de datos.
- Verifica que el coeficiente de correlación es \(r=0\).
2.3 Acotación del coeficiente de correlación. Utiliza los siguientes pasos para demostrar que \(r\) está acotado entre -1 y 1 (Estos pasos son de Koch, 1990).
- Deja que \(a\) y \(c\) sean constantes genéricas. Verifica \[\begin{eqnarray*} 0 & \leq & \frac{1}{n-1}\sum_{i=1}^{n}\left( a\frac{x_i-\overline{x}}{s_x}-c \frac{y_i-\overline{y}}{s_y}\right) ^2 \\ &=& a^2+c^2-2acr. \end{eqnarray*}\]
- Utiliza los resultados del apartado (a) para demostrar que \(2ac(r-1)\leq (a-c)^2.\)
- Al tomar \(a=c\), utiliza el resultado del apartado (b) para demostrar que \(r\leq 1\).
- Al tomar \(a=-c\), utiliza los resultados del apartado (b) para demostrar que \(r\geq -1\).
- ¿En qué condiciones es \(r=-1\)? ¿En qué condiciones es \(r=1\)?
2.4 Los coeficientes de regresión son sumas ponderadas. Demuestra que el término de intercepto, \(b_0\), puede expresarse como una suma ponderada de las variables dependientes. Es decir, demuestra que \(b_0=\sum_{i=1}^{n}w_{i,0}y_i.\) Además, expresa los pesos en términos de los pesos de la pendiente, \(w_i\).
2.5 Otra expresión para la pendiente como una suma ponderada
- Utilizando álgebra, establece una expresión alternativa
\[
b_1=\frac{\sum_{i=1}^{n}weight_i~slope_i}{ \sum_{i=1}^{n}weight_i}.
\]
Aquí, \(slope_i\) es la pendiente entre \((x_i,y_i)\) y \((\bar{x},\bar{y})\). Da una forma precisa para el peso \(weight_i\) como una función de la variable explicativa \(x\).
- Supón que \(\bar{x} = 4, \bar{y} = 3, x_1 = 2 \text{ y } y_1= 6\). Determina la pendiente y el peso para la primera observación, es decir, \(slope_1\) y \(weight_1\).
2.6 Considera dos variables, \(y\) y \(x\). Realiza una regresión de \(y\) sobre \(x\) para obtener un coeficiente de pendiente que llamaremos \(b_{1,x,y}\). Realiza otra regresión de \(x\) sobre \(y\) para obtener un coeficiente de pendiente que llamaremos \(b_{1,y,x}\). Demuestra que el coeficiente de correlación entre \(x\) y \(y\) es la media geométrica de los dos coeficientes de pendiente según el signo, es decir, demuestra que \(|r|=\sqrt{ b_{1,x,y}b_{1,y,x}}.\)
2.7 Regresión a través del origen. Considera el modelo \(y_i=\beta_1 x_i + \varepsilon_i\), es decir, regresión con una variable explicativa sin el término de intercepto. Este modelo se llama regresión a través del origen porque la verdadera línea de regresión \(\mathrm{E}y = \beta_1 x\) pasa por el origen (el punto (0, 0)). Para este modelo, la estimación de mínimos cuadrados de \(\beta_1\) es ese número \(b_1\) que minimiza la suma de cuadrados \(\mathrm{SS}(b_1^{\ast} )=\sum_{i=1}^{n}\left( y_i - b_1^{\ast}x_i\right) ^2.\)
Verifica que \[ b_1 = \frac{\sum_{i=1}^{n} x_i y_i}{\sum_{i=1}^{n}x_i^2}. \]
Considera el modelo \(y_i=\beta_1 z_i^2 + \varepsilon_i\), un modelo cuadrático que pasa por el origen. Utiliza el resultado del apartado (a) para determinar la estimación de mínimos cuadrados de \(\beta_1\).
2.8 a. Demuestra que \[ s_y^2=\frac{1}{n-1}\sum_{i=1}^{n}\left( y_i-\overline{y}\right) ^2= \frac{1}{n-1}\left( \sum_{i=1}^{n}y_i^2-n\overline{y}^2\right) . \]
- Sigue los mismos pasos para demostrar que \(\sum_{i=1}^{n}\left( y_i - \overline{y} \right) \left( x_i-\overline{x}\right) =\sum_{i=1}^{n}
x_i y_i - n \overline{x}~\overline{y}.\)
- Demuestra que \[ b_{1}=\frac{\sum_{i=1}^{n}\left( y_i-\overline{y}\right) \left( x_i- \overline{x}\right) }{\sum_{i=1}^{n}\left( x_i - \overline{x} \right) ^2} \]
- Establece la fórmula comúnmente utilizada \[ b_{1}= \frac{\sum_{i=1}^{n}x_iy_i-n\overline{x}~\overline{y}} {\sum_{i=1}^{n}x_i^2 - n\overline{x}^2}. \]
2.9 Interpretación de los coeficientes asociados con una variable explicativa binaria. Supón que \(x_i\) solo toma los valores 0 y 1. De las \(n\) observaciones, \(n_1\) toman el valor \(x=0\). Estas \(n_1\) observaciones tienen un valor promedio \(y\) de \(\overline{y}_1\). Las restantes \(n-n_1\) observaciones tienen el valor \(x=1\) y un valor promedio \(y\) de \(\overline{y}_2\). Utiliza el Ejercicio 2.8 para demostrar que \(b_1 = \overline{y}_2 - \overline{y}_1.\)
2.10 Utilización de Hogares de Cuidado.
Este ejercicio considera los datos de hogares de cuidado proporcionados por el Departamento de Salud y Servicios Familiares de Wisconsin (DHFS) y descritos en el Ejercicio 1.2.
Parte 1: Utiliza los datos del año 2000 y realiza el siguiente análisis.
Correlaciones
a(i). Calcula la correlación entre TPY y LOGTPY. Comenta tu resultado.
a(ii). Calcula la correlación entre TPY, NUMBED y SQRFOOT. ¿Parecen estas variables altamente correlacionadas?
a(iii). Calcula la correlación entre TPY y NUMBED/10. Comenta tu resultado.Diagramas de dispersión. Grafica TPY versus NUMBED y TPY versus SQRFOOT. Comenta los gráficos.
Regresión lineal básica.
c(i). Ajusta un modelo de regresión lineal básico usando TPY como variable de resultado y NUMBED como variable explicativa. Resume el ajuste citando el coeficiente de determinación, \(R^2\), y el estadístico \(t\) para NUMBED.
c(ii). Repite c(i), usando SQRFOOT en lugar de NUMBED. En términos de \(R^2\), ¿cuál modelo se ajusta mejor?
c(iii). Repite c(i), usando LOGTPY como variable de resultado y LOG(NUMBED) como variable explicativa.
c(iv). Repite c(iii), usando LOGTPY como variable de resultado y LOG(SQRFOOT) como variable explicativa.
Parte 2: Ajusta el modelo en la Parte 1.c(i) usando datos de 2001. ¿Son los patrones estables a lo largo del tiempo?
Secciones 2.3-2.4
2.11 Supón que, para un tamaño de muestra de \(n\) = 3, tienes \(e_2\) = 24 y \(e_{3}\) = -1. Determina \(e_{1}\).
2.12 Supón que \(r=0\), \(n=15\) y \(s_y = 10\). Determina \(s\).
2.13 El coeficiente de correlación y el coeficiente de determinación. Usa los siguientes pasos para establecer una relación entre el coeficiente de determinación y el coeficiente de correlación.
- Muestra que \(\widehat{y}_i-\overline{y}=b_1(x_i-\overline{x}).\)
- Usa el apartado (a) para mostrar que \(Regress~SS=\sum_{i=1}^{n}\left(\widehat{y}_i - \overline{y} \right)^2 = b_1^2s_x^2(n-1).\)
- Usa el apartado (b) para establecer que \(R^2=r^2.\)
2.14 Muestra que el residuo promedio es cero, es decir, muestra que \(n^{-1}\sum_{i=1}^{n} e_i=0.\)
2.15 Correlación entre residuos y variables explicativas. Considera una secuencia genérica de pares de números \((x_1,y_1)\), …, \((x_n,y_n)\) con el coeficiente de correlación calculado como
\(r(y,x)=\left[ (n-1)s_ys_x\right] ^{-1}\sum_{i=1}^{n}\left(
y_i-\overline{y}\right) \left( x_i-\overline{x}\right) .\)
- Supón que \(\overline{y}=0\), \(\overline{x}=0\) o ambos \(\overline{x}\) y \(\overline{y}=0\). Luego, verifica que \(r(y,x)=0\) implica \(\sum_{i=1}^{n}y_i x_i=0\) y viceversa.
- Muestra que la correlación entre los residuos y las variables explicativas es cero. Haz esto usando la parte (a) del Ejercicio 2.13 para mostrar que \(\sum_{i=1}^{n} x_i e_i = 0\) y luego aplica la parte (a).
- Muestra que la correlación entre los residuos y los valores ajustados es cero. Haz esto mostrando que \(\sum_{i=1}^n \widehat{y}_i e_i = 0\) y luego aplica la parte (a).
2.16 Correlación y estadísticas \(t\). Usa los siguientes pasos para establecer una relación entre el coeficiente de correlación y el estadístico \(t\) para la pendiente.
Usa álgebra para verificar que \[ R^2=1-\frac{n-2}{n-1}\frac{s^2}{s_y^2}. \]
Usa la parte (a) para establecer la siguiente fórmula rápida para \(s\), \[s = s_y \sqrt{(1-r^2)\frac{n-1}{n-2}}.\]
Usa la parte (b) para mostrar que \[ t(b_1) = \sqrt{n-2}\frac{r}{\sqrt{1-r^2}}. \]
Secciones 2.6-2.7
2.17 Efectos de un punto inusual. Estás analizando un conjunto de datos de tamaño \(n=100\). Has realizado un análisis de regresión usando una variable predictora y notas que el residuo para la décima observación es inusualmente grande.
- Supón que, de hecho, resulta que \(e_{10}=8s\). ¿Qué porcentaje de la suma de cuadrados de los errores, \(Error~SS\), se debe a la décima observación?
- Supón que \(e_{10}=4s\). ¿Qué porcentaje de la suma de cuadrados de errores, \(Error~SS\), se debe a la décima observación?
- Supón que reduces el conjunto de datos a tamaño \(n=20\). Después de realizar la regresión, resulta que todavía tenemos \(e_{10}=4s\). ¿Qué porcentaje de la suma de cuadrados de errores, \(Error~SS\), se debe a la décima observación?
2.18 Considera un conjunto de datos de 20 observaciones con las siguientes estadísticas resumen: \(\overline{x}=0\), \(\overline{y}=9\), \(s_x=1\) y \(s_y=10\). Realizas una regresión usando una variable y determinas que \(s=7\). Determina el error estándar de una predicción en \(x_{\ast}=1.\)
2.19 Las estadísticas resumen pueden ocultar relaciones importantes. Los datos en Tabla 2.9 son de Anscombe (1973). El propósito de este ejercicio es demostrar cómo graficar los datos puede revelar información importante que no es evidente en las estadísticas numéricas resumen.
Tabla 2.9. Datos de Anscombe (1973)
\[ {\small \begin{array}{c|rrrrrr} \hline obs & & & & & & \\ num & x_1 & y_1 & y_2 & y_3 & x_2 & y_4 \\ \hline 1 & 10 & 8.04 & 9.14 & 7.46 & 8 & 6.58 \\ 2 & 8 & 6.95 & 8.14 & 6.77 & 8 & 5.76 \\ 3 & 13 & 7.58 & 8.74 & 12.74 & 8 & 7.71 \\ 4 & 9 & 8.81 & 8.77 & 7.11 & 8 & 8.84 \\ 5 & 11 & 8.33 & 9.26 & 7.81 & 8 & 8.47 \\ 6 & 14 & 9.96 & 8.10 & 8.84 & 8 & 7.04 \\ 7 & 6 & 7.24 & 6.13 & 6.08 & 8 & 5.25 \\ 8 & 4 & 4.26 & 3.10 & 5.39 & 8 & 5.56 \\ 9 & 12 & 10.84 & 9.13 & 8.15 & 8 & 7.91 \\ 10 & 7 & 4.82 & 7.26 & 6.42 & 8 & 6.89 \\ 11 & 5 & 5.68 & 4.74 & 5.73 & 19 & 12.50 \\ \hline \end{array} } \]
Calcula los promedios y desviaciones estándar de cada columna de datos. Verifica que los promedios y desviaciones estándar de cada una de las columnas \(x\) son iguales, dentro de dos decimales, y de manera similar para cada una de las columnas \(y\).
Realiza cuatro regresiones, (1) \(y_{1}\) sobre \(x_{1}\), (2) \(y_2\) sobre \(x_{1}\), (3) \(y_{3}\) sobre \(x_{1}\) y (4) \(y_{4}\) sobre \(x_2\). Verifica, para cada uno de los cuatro ajustes de regresión, que \(b_0\approx 3.0\), \(b_{1}\approx 0.5\), \(s\approx 1.237\) y \(R^2\approx 0.677\), dentro de dos decimales.
Produce diagramas de dispersión para cada uno de los cuatro modelos de regresión que ajustaste en el apartado (b).
Discute el hecho de que los modelos de regresión ajustados en el apartado (b) implican que los cuatro conjuntos de datos son similares, aunque los cuatro diagramas de dispersión producidos en el apartado (c) muestran una historia dramáticamente diferente.
2.20 Utilización de Hogares de Cuidado. Este ejercicio considera los datos de hogares de cuidado proporcionados por el Departamento de Salud y Servicios Familiares de Wisconsin (DHFS) y descritos en el Ejercicio 1.2 y 2.10.
Decides examinar la relación entre los años totales de pacientes (LOGTPY) y el número de camas (LOGNUMBED), ambos en unidades logarítmicas, usando datos del año 2001.
Estadísticas descriptivas. Crea estadísticas descriptivas básicas para cada variable. Resume la relación mediante un estadístico de correlación y un diagrama de dispersión.
Ajusta el modelo lineal básico. Cita las estadísticas descriptivas básicas, incluye el coeficiente de determinación, el coeficiente de regresión para LOGNUMBED y el estadístico \(t\) correspondiente.
Pruebas de hipótesis. Prueba las siguientes hipótesis al nivel de significancia del 5% usando un estadístico \(t\). También calcula el valor \(p\) correspondiente.
c(i). Prueba \(H_0: \beta_1 = 0\) frente a \(H_a: \beta_1 \neq 0\).
c(ii). Prueba \(H_0: \beta_1 = 1\) frente a \(H_a: \beta_1 \neq 1\).
c(iii). Prueba \(H_0: \beta_1 = 1\) frente a \(H_a: \beta_1 > 1\).
c(iv). Prueba \(H_0: \beta_1 = 1\) frente a \(H_a: \beta_1 < 1\).Estás interesado en el efecto que un cambio marginal en LOGNUMBED tiene sobre el valor esperado de LOGTPY.
d(i). Supón que hay un cambio marginal en LOGNUMBED de 2. Proporciona una estimación puntual del cambio esperado en LOGTPY.
d(ii). Proporciona un intervalo de confianza del 95% correspondiente a la estimación puntual en la parte d(i).
d(iii). Proporciona un intervalo de confianza del 99% correspondiente a la estimación puntual en la parte d(i).En un número especificado de camas estimado en \(x_{*} = 100\), haz lo siguiente:
e(i). Encuentra el valor predicho de LOGTPY.
e(ii). Obtén el error estándar de la predicción.
e(iii). Obtén un intervalo de predicción del 95% para tu predicción.
e(iv). Convierte la predicción puntual en la parte e(i) y el intervalo de predicción obtenido en la parte e(iii) en años totales de personas (mediante exponenciación).
e(v). Obtén un intervalo de predicción como en la parte e(iv), correspondiente a un nivel del 90% (en lugar del 95%).
2.21 Ofertas Públicas Iniciales. Como analista financiero, deseas convencer a un cliente de las ventajas de invertir en empresas que acaban de ingresar a una bolsa de valores, en una OPI (oferta pública inicial). Por lo tanto, reúnes datos de 116 empresas que fijaron precios durante el período de seis meses del 1 de enero de 1998 al 1 de junio de 1998. Al mirar estos datos históricos recientes, puedes calcular RETURN, el retorno de la empresa en un año (en porcentaje).
También estás interesado en observar características financieras de la empresa que puedan ayudarte a entender (y predecir) el retorno. Inicialmente examinas REVENUE, los ingresos de la empresa en 1997 en millones de dólares. Desafortunadamente, esta variable no estaba disponible para seis empresas. Por lo tanto, las estadísticas a continuación son para las 110 empresas que tienen tanto REVENUE como RETURN. Además, la Tabla 2.9 proporciona información sobre los ingresos logarítmicos (naturales), denominados como LnREV, y el precio inicial de la acción, denominado PRICEIPO.
| Media | Mediana | Desviación Estándar | Mínimo | Máximo | |
|---|---|---|---|---|---|
| RETURN | 0.106 | -0.130 | 0.824 | -0.938 | 4.333 |
| REV | 134.487 | 39.971 | 261.881 | 0.099 | 1455.761 |
| LnREV | 3.686 | 3.688 | 1.698 | -2.316 | 7.283 |
| PRICEIPO | 13.195 | 13.000 | 4.694 | 4.000 | 29.000 |
Hipotetizas que las empresas más grandes, medida por ingresos, son más estables y, por lo tanto, deberían tener mayores retornos. Has determinado que la correlación entre RETURN y REVENUE es -0.0175.
a(i). Calcula el ajuste de mínimos cuadrados usando REVENUE para predecir RETURN. Determina \(b_0\) y \(b_1\).
a(ii). Para Hyperion Telecommunications, los ingresos son 95.55 (millones de dólares). Calcula el RETURN ajustado usando el ajuste de regresión en la parte a(i).
Tabla 2.11. Resultados de la Regresión con Ingresos Logarítmicos
\[ {\small \begin{array}{l|rrr} \hline & & \text{Error} & \\ \text{Variable} & \text{Coeficiente} & \text{Estándar} & t-\text{estadístico} \\ \hline \text{INTERCEPTO} & 0.438 & 0.186 & 2.35\\ \text{LnREV} & -0.090 & 0.046 & -1.97 \\ \hline s = 0.8136, & R^2 = 0.03452 \\ \hline \end{array} } \]
Tabla 2.11 resume una regresión utilizando ingresos y rendimientos logarítmicos.
b(i). Supón que usas LnREV para predecir RETURN. Calcula el RETURN ajustado bajo este modelo de regresión. ¿Es igual a tu respuesta en la parte a(ii)?
b(ii) ¿Afectan significativamente los ingresos logarítmicos a los retornos? Para ello, proporciona una prueba formal de hipótesis. Expón tus hipótesis nula y alternativa, el criterio de toma de decisiones y la regla de toma de decisiones. Usa un nivel de significancia del 10%.
b(iii). Hipotetizas que, manteniendo todo constante, las empresas con mayores ingresos serán más estables y, por lo tanto, tendrán un mayor retorno inicial. Por lo tanto, deseas considerar la hipótesis nula de ninguna relación entre LnREV y RETURN frente a la hipótesis alternativa de que hay una relación positiva entre LnREV y RETURN. Para ello, proporciona una prueba formal de hipótesis. Expón tus hipótesis nula y alternativa, el criterio de toma de decisiones y la regla de toma de decisiones. Usa un nivel de significancia del 10%.Determina la correlación entre LnREV y RETURN. Asegúrate de indicar si esta correlación es positiva, negativa o cero.
Estás considerando invertir en una empresa que tiene LnREV = 2 (por lo que los ingresos son \(e^2\) = 7.389 millones de dólares).
d(i). Usando el modelo de regresión ajustado, determina la predicción puntual de mínimos cuadrados.
d(ii). Determina el intervalo de predicción del 95% correspondiente a tu predicción en la parte d(i).El \(R^2\) del modelo de regresión ajustado es un decepcionante 3.5%. Parte de la dificultad se debe a la observación número 59, la Corporación Inktomi. Las ventas de Inktomi están en el 12º lugar más bajo del conjunto de datos, con LnREV = 1.76 (por lo que los ingresos son \(e^{1.76} = 5.79\) millones de dólares), pero tiene el mayor retorno en el primer año, con RETURN = 433.33.
e(i). Calcula el residuo para esta observación.
e(ii). ¿Qué proporción de la variabilidad no explicada (suma de cuadrados de errores) representa esta observación?
e(iii). Define la idea de una observación de alto apalancamiento.
e(iv). ¿Se consideraría esta observ
ación como una observación de alto apalancamiento? Justifica tu respuesta.
2.22 Esperanzas de Vida Nacionales. Continuamos el análisis iniciado en el Ejercicio 1.7 examinando la relación entre \(y= LIFEEXP\) y \(x=FERTILITY\), mostrado en la Figura 2.12. Ajusta un modelo de regresión lineal de \(LIFEEXP\) usando la variable explicativa \(x=FERTILITY\).
Figura 2.12: Gráfico de FERTILITY versus LIFEEXP.
EE.UU. tiene una tasa de FERTILITY de 2.0. Determina la esperanza de vida ajustada.
La nación insular Dominica no reportó una tasa de FERTILITY y, por lo tanto, no se incluyó en la regresión. Supón que su tasa de FERTILITY es 2.0. Proporciona un intervalo de predicción del 95% para la esperanza de vida en Dominica.
China tiene una tasa de FERTILITY de 1.7 y una esperanza de vida de 72.5. Determina el residuo bajo el modelo. ¿Cuántos múltiplos de \(s\) está este residuo alejado de cero?
Supón que tu hipótesis previa es que la pendiente de FERTILITY es -6.0 y deseas probar la hipótesis nula de que la pendiente ha aumentado (es decir, la pendiente es mayor que -6.0). Prueba esta hipótesis al nivel de significancia del 5%. También calcula un valor \(p\) aproximado.
2.11 Suplemento Técnico - Elementos del Álgebra de Matrices
Los ejemplos son una herramienta excelente para introducir temas técnicos como la regresión. Sin embargo, este capítulo también ha utilizado álgebra, así como probabilidad y estadística básica, para darte una comprensión más profunda del análisis de regresión. A partir de ahora, estudiaremos relaciones multivariantes. Con muchas cosas ocurriendo simultáneamente en varias dimensiones, el álgebra ya no es útil para proporcionar información. En cambio, necesitaremos el álgebra de matrices. Este suplemento ofrece una breve introducción al álgebra de matrices para que puedas estudiar los capítulos de regresión lineal de este texto. El Apéndice A3 define conceptos adicionales de matrices.
2.11.1 Definiciones Básicas
Una matriz es una tabla rectangular de números organizados en filas y columnas (el plural de matriz es matrices). Por ejemplo, considera los ingresos y la edad de 3 personas.
\[ \mathbf{A}= \begin{array}{c} Fila~1 \\ Fila~2 \\ Fila~3 \end{array} \overset{ \begin{array}{cc} ~~~Col~1~ & Col~2 \end{array} }{\left( \begin{array}{cc} 6,000 & 23 \\ 13,000 & 47 \\ 11,000 & 35 \end{array} \right) } \]
Aquí, la columna 1 representa el ingreso y la columna 2 representa la edad. Cada fila corresponde a un individuo. Por ejemplo, el primer individuo tiene 23 años y un ingreso de $6,000.
El número de filas y columnas se llama la dimensión de la matriz. Por ejemplo, la dimensión de la matriz \(\mathbf{A}\) anterior es \(3\times 2\) (se lee 3 “por” 2). Esto significa 3 filas y 2 columnas. Si quisiéramos representar los ingresos y la edad de 100 personas, entonces la dimensión de la matriz sería \(100\times 2\).
Es conveniente representar una matriz usando la notación
\[ \mathbf{A}=\left( \begin{array}{cc} a_{11} & a_{12} \\ a_{21} & a_{22} \\ a_{31} & a_{32} \end{array} \right) . \]
Aquí, \(a_{ij}\) es el símbolo para el número en la \(i\)-ésima fila y \(j\)-ésima columna de \(\mathbf{A}\). En general, trabajamos con matrices de la forma
\[ \mathbf{A}=\left( \begin{array}{cccc} a_{11} & a_{12} & \cdots & a_{1k} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nk} \end{array} \right) . \]
En este caso, la matriz \(\mathbf{A}\) tiene dimensión \(n\times k\).
Un vector es una matriz especial. Un vector fila es una matriz que contiene solo 1 fila (\(k=1\)). Un vector columna es una matriz que contiene solo 1 columna (\(n=1\)). Por ejemplo,
\[ \text{vector columna}\rightarrow \left( \begin{array}{c} 2 \\ 3 \\ 4 \\ 5 \\ 6 \end{array} \right) ~~~~\text{vector fila}\rightarrow \left( \begin{array}{ccccc} 2 & 3 & 4 & 5 & 6 \end{array} \right) . \]
Observa que el vector fila ocupa mucho menos espacio en una página impresa que el vector columna correspondiente. Una operación básica que relaciona estas dos cantidades es la transposición. La transposición de una matriz \(\mathbf{A}\) se define intercambiando las filas y columnas y se denota por \(\mathbf{A }^{\prime }\) (o \(\mathbf{A}^{T}\)). Por ejemplo,
\[ \mathbf{A}=\left( \begin{array}{cc} 6,000 & 23 \\ 13,000 & 47 \\ 11,000 & 35 \end{array} \right) ~~~\mathbf{A}^{\prime }=\left( \begin{array}{ccc} 6,000 & 13,000 & 11,000 \\ 23 & 47 & 35 \end{array} \right) . \]
Así, si \(\mathbf{A}\) tiene dimensión \(n\times k\), entonces \(\mathbf{A}^{\prime }\) tiene dimensiones \(k\times n\).
2.11.2 Algunas Matrices Especiales
Una matriz cuadrada es una matriz donde el número de filas es igual al número de columnas, es decir, \(n=k\).
Los números diagonales de una matriz cuadrada son los números en una matriz donde el número de fila es igual al número de columna, por ejemplo, \(a_{11}\), \(a_{22}\), y así sucesivamente. Una matriz diagonal es una matriz cuadrada en la que todos los números no diagonales son iguales a 0. Por ejemplo, \[ \mathbf{A}=\left( \begin{array}{ccc} -1 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 3 \end{array} \right) . \]
Una matriz identidad es una matriz diagonal donde todos los números diagonales son iguales a 1. Esta matriz especial se denota a menudo por \(\mathbf{I}\).
Una matriz simétrica es una matriz cuadrada \(\mathbf{A}\) tal que la matriz permanece sin cambios si intercambiamos las filas y las columnas. Más formalmente, una matriz \(\mathbf{A}\) es simétrica si \(\mathbf{A=A} ^{\prime }\). Por ejemplo, \[ \mathbf{A}=\left( \begin{array}{ccc} 1 & 2 & 3 \\ 2 & 4 & 5 \\ 3 & 5 & 10 \end{array} \right) \mathbf{=A}^{\prime }. \] Observa que una matriz diagonal es una matriz simétrica.
2.11.3 Operaciones Básicas
Multiplicación por un Escalar
Sea \(\mathbf{A}\) una matriz de \(n\times k\) y sea \(c\) un número real. Es decir, un número real es una matriz de \(1\times 1\) y también se llama escalar. Multiplicar un escalar \(c\) por una matriz \(\mathbf{A}\) se denota por \(c\mathbf{A}\) y se define por \[ c\mathbf{A}=\left( \begin{array}{cccc} ca_{11} & ca_{12} & \cdots & ca_{1k} \\ \vdots & \vdots & \ddots & \vdots \\ ca_{n1} & ca_{n2} & \cdots & ca_{nk} \end{array} \right) . \] Por ejemplo, supongamos que \(c=10\) y \[ \mathbf{A}=\left( \begin{array}{cc} 1 & 2 \\ 6 & 8 \end{array} \right) ~~~~~\text{entonces} ~~~~\mathbf{B}=c\mathbf{A}=\left( \begin{array}{cc} 10 & 20 \\ 60 & 80 \end{array} \right) . \] Observa que \(c\mathbf{A}=\mathbf{A}c\).
Suma y Resta de Matrices
Sean \(\mathbf{A}\) y \(\mathbf{B}\) matrices con dimensiones \(n\times k\). Utiliza \(a_{ij}\) y \(b_{ij}\) para denotar los números en la \(i\)-ésima fila y \(j\)-ésima columna de \(\mathbf{A}\) y \(\mathbf{B}\), respectivamente. Entonces, la matriz \(\mathbf{C}=\mathbf{A}+\mathbf{B}\) se define como la matriz con \((a_{ij}+b_{ij})\) en la \(i\)-ésima fila y \(j\)-ésima columna. De manera similar, la matriz \(\mathbf{C}=\mathbf{A}-\mathbf{B}\) se define como la matriz con \((a_{ij}-b_{ij})\) en la \(i\)-ésima fila y \(j\)-ésima columna. Simbólicamente, escribimos esto como sigue. \[ \text{Si }\mathbf{A=}\left( a_{ij}\right) _{ij}\text{ y } \mathbf{B=}\left( b_{ij}\right) _{ij}\text{, entonces} \] \[ \mathbf{C}=\mathbf{A}+\mathbf{B=}\left( a_{ij}+b_{ij}\right) _{ij}\text{ y }\mathbf{C}=\mathbf{A}-\mathbf{B=}\left( a_{ij}-b_{ij}\right) _{ij}. \] Por ejemplo, considera \[ \mathbf{A}=\left( \begin{array}{cc} 2 & 5 \\ 4 & 1 \end{array} \right) ~~~\mathbf{B}=\left( \begin{array}{cc} 4 & 6 \\ 8 & 1 \end{array} \right). \] Entonces \[ \mathbf{A}+\mathbf{B}=\left( \begin{array}{cc} 6 & 11 \\ 12 & 2 \end{array} \right) ~~~\mathbf{A}-\mathbf{B}=\left( \begin{array}{cc} -2 & -1 \\ -4 & 0 \end{array} \right) . \]
Ejemplo Básico de Regresión Lineal de Suma y Resta. Ahora, recuerda que el modelo básico de regresión lineal puede escribirse como \(n\) ecuaciones: \[ \begin{array}{c} y_1=\beta_0+\beta_1x_1+\varepsilon_1 \\ \vdots \\ y_n=\beta_0+\beta_1x_n+\varepsilon_n. \end{array} \] Podemos definir \[ \mathbf{y}=\left( \begin{array}{c} y_1 \\ \vdots \\ y_n \end{array} \right) ~~~\boldsymbol \varepsilon = \left( \begin{array}{c} \varepsilon_1 \\ \vdots \\ \varepsilon_n \end{array} \right) ~~~\text{y}~~~ \mathrm{E~}\mathbf{y} =\left( \begin{array}{c} \beta_0+\beta_1 x_1 \\ \vdots \\ \beta_0 + \beta_1 x_n \end{array} \right) . \] Con esta notación, podemos expresar las \(n\) ecuaciones de manera más compacta como \(\mathbf{y} = \mathrm{E~}\mathbf{y}+\boldsymbol \varepsilon\).
Multiplicación de Matrices
En general, si \(\mathbf{A}\) es una matriz de dimensión \(n\times c\) y \(\mathbf{B}\) es una matriz de dimensión \(c\times k\), entonces \(\mathbf{C}=\mathbf{AB}\) es una matriz de dimensión \(n\times k\) y se define por \[ \mathbf{C}=\mathbf{AB}=\left( \sum_{s=1}^{c}a_{is}b_{sj}\right)_{ij}. \] Por ejemplo, considera las matrices \(2\times 2\) \[ \mathbf{A}=\left( \begin{array}{cc} 2 & 5 \\ 4 & 1 \end{array} \right) ~~~\mathbf{B}=\left( \begin{array}{cc} 4 & 6 \\ 8 & 1 \end{array} \right) . \] La matriz \(\mathbf{AB}\) tiene dimensión \(2\times 2\). Para ilustrar el cálculo, considera el número en la primera fila y segunda columna de \(\mathbf{AB}\). Según la regla presentada arriba, con \(i=1\) y \(j=2\), el elemento correspondiente de \(\mathbf{AB}\) es \(\sum_{s=1}^2a_{1s}b_{s2}=a_{11}b_{12}+a_{12}b_{22}=2(6)+5(1)=17\). Los otros cálculos se resumen como \[ \mathbf{AB}=\left( \begin{array}{cc} 2(4)+5(8) & 2(6)+5(1) \\ 4(4)+1(8) & 4(6)+1(1) \end{array} \right) =\left( \begin{array}{cc} 48 & 17 \\ 24 & 25 \end{array} \right) . \] Como otro ejemplo, supongamos \[ \mathbf{A}=\left( \begin{array}{ccc} 1 & 2 & 4 \\ 0 & 5 & 8 \end{array} \right) ~~~\mathbf{B}=\left( \begin{array}{c} 3 \\ 5 \\ 2 \end{array} \right) . \] Como \(\mathbf{A}\) tiene dimensión \(2\times 3\) y \(\mathbf{B}\) tiene dimensión \(3\times 1\), esto significa que el producto \(\mathbf{AB}\) tiene dimensión \(2\times 1\). Los cálculos se resumen como \[ \mathbf{AB}=\left( \begin{array}{c} 1(3)+2(5)+4(2) \\ 0(3)+5(5)+8(2) \end{array} \right) =\left( \begin{array}{c} 21 \\ 41 \end{array} \right) . \] Para algunos ejemplos adicionales, tenemos \[ \left( \begin{array}{cc} 4 & 2 \\ 5 & 8 \end{array} \right) \left( \begin{array}{c} a_1 \\ a_2 \end{array} \right) =\left( \begin{array}{c} 4a_1+2a_2 \\ 5a_1+8a_2 \end{array} \right) . \] \[ \left( \begin{array}{ccc} 2 & 3 & 5 \end{array} \right) \left( \begin{array}{c} 2 \\ 3 \\ 5 \end{array} \right) =2^2+3^2+5^2=38~~~\left( \begin{array}{c} 2 \\ 3 \\ 5 \end{array} \right) \left( \begin{array}{ccc} 2 & 3 & 5 \end{array} \right) =\left( \begin{array}{ccc} 4 & 6 & 10 \\ 6 & 9 & 15 \\ 10 & 15 & 25 \end{array} \right) . \] En general, observa que \(\mathbf{AB}\neq \mathbf{BA}\) en la multiplicación de matrices, a diferencia de la multiplicación de escalares (números reales). Además, observamos que la matriz identidad cumple el papel de “uno” en la multiplicación de matrices, ya que \(\mathbf{AI=A}\) y \(\mathbf{IA=A}\) para cualquier matriz \(\mathbf{A}\), siempre que las dimensiones sean compatibles para permitir la multiplicación de matrices.
Ejemplo Básico de Regresión Lineal de Multiplicación de Matrices. Define \[ \mathbf{X}=\left( \begin{array}{cc} 1 & x_1 \\ \vdots & \vdots \\ 1 & x_n \end{array} \right) \text{ y } \boldsymbol \beta =\left( \begin{array}{c} \beta_0 \\ \beta_1 \end{array} \right) \text{, para obtener } \mathbf{X} \boldsymbol{\beta} =\left( \begin{array}{c} \beta_0+\beta_1x_1 \\ \vdots \\ \beta_0+\beta_1x_n \end{array} \right) =\mathbf{\mathrm{E~}\mathbf{y}}. \] Así, se obtiene la expresión matricial familiar del modelo de regresión, \(\mathbf{y}=\mathbf{X} \boldsymbol{\beta} + \boldsymbol{\varepsilon}\). Otras cantidades útiles incluyen \[ \mathbf{y}^{\prime }\mathbf{y}=\left( \begin{array}{ccc} y_1 & \cdots & y_n \end{array} \right) \left( \begin{array}{c} y_1 \\ \vdots \\ y_n \end{array} \right) =y_1^2+\cdots +y_n^2=\sum_{i=1}^{n}y_i^2, \] \[ \mathbf{X}^{\prime }\mathbf{y}=\left( \begin{array}{ccc} 1 & \cdots & 1 \\ x_1 & \cdots & x_n \end{array} \right) \left( \begin{array}{c} y_1 \\ \vdots \\ y_n \end{array} \right) =\left( \begin{array}{c} \sum_{i=1}^{n}y_i \\ \sum_{i=1}^{n}x_iy_i \end{array} \right) \] y \[ \mathbf{X}^{\prime }\mathbf{X}=\left( \begin{array}{ccc} 1 & \cdots & 1 \\ x_1 & \cdots & x_n \end{array} \right) \left( \begin{array}{cc} 1 & x_1 \\ \vdots & \vdots \\ 1 & x_n \end{array} \right) =\left( \begin{array}{cc} n & \sum_{i=1}^{n}x_i \\ \sum_{i=1}^{n}x_i & \sum_{i=1}^{n} x_i^2 \end{array} \right) . \] Observa que \(\mathbf{X}^{\prime }\mathbf{X}\) es una matriz simétrica.
Inversas de Matrices
En álgebra de matrices, no existe el concepto de “división.” En su lugar, extendemos el concepto de “recíprocos” de los números reales. Para comenzar, supongamos que \(\mathbf{A}\) es una matriz cuadrada de dimensión \(k \times k\) y que \(\mathbf{I}\) es la matriz identidad de dimensión \(k \times k\). Si existe una matriz \(k \times k\) llamada \(\mathbf{B}\) tal que \(\mathbf{AB}=\mathbf{I}=\mathbf{BA}\), entonces \(\mathbf{B}\) se llama inversa de \(\mathbf{A}\) y se escribe como \[ \mathbf{B}=\mathbf{A}^{-1}. \] No todas las matrices cuadradas tienen inversas. Además, incluso cuando existe una inversa, puede no ser fácil de calcular manualmente. Una excepción a esta regla son las matrices diagonales. Supongamos que \(\mathbf{A}\) es una matriz diagonal de la forma \[ \mathbf{A}=\left( \begin{array}{ccc} a_{11} & \cdots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \cdots & a_{kk} \end{array} \right). \text{ Entonces } \mathbf{A}^{-1}=\left( \begin{array}{ccc} \frac{1}{a_{11}} & \cdots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \cdots & \frac{1}{a_{kk}} \end{array} \right). \] Por ejemplo, \[ \begin{array}{cccc} \left( \begin{array}{cc} 2 & 0 \\ 0 & -19 \end{array} \right) & \left( \begin{array}{cc} \frac{1}{2} & 0 \\ 0 & -\frac{1}{19} \end{array} \right) & = & \left( \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right) \\ \mathbf{A} & \mathbf{A}^{-1} & = & \mathbf{I} \end{array} . \] En el caso de una matriz de dimensión \(2\times 2\), el procedimiento de inversión se puede realizar manualmente incluso cuando la matriz no es diagonal. En el caso de \(2\times 2\), supongamos que si \[ \mathbf{A}=\left( \begin{array}{cc} a & b \\ c & d \end{array} \right), \text{ entonces } \mathbf{A}^{-1}=\frac{1}{ad-bc}\left( \begin{array}{cc} d & -b \\ -c & a \end{array} \right) \text{.} \] Así, por ejemplo, si \[ \mathbf{A}=\left( \begin{array}{cc} 2 & 2 \\ 3 & 4 \end{array} \right) \text{ entonces } \mathbf{A}^{-1}=\frac{1}{2(4)-2(3)} \left( \begin{array}{cc} 4 & -2 \\ -3 & 2 \end{array} \right) =\left( \begin{array}{cc} 2 & -1 \\ -3/2 & 1 \end{array} \right) \text{.} \] Como verificación, tenemos \[ \mathbf{A}\mathbf{A}^{-1}=\left( \begin{array}{cc} 2 & 2 \\ 3 & 4 \end{array} \right) \left( \begin{array}{cc} 2 & -1 \\ -3/2 & 1 \end{array} \right) =\left( \begin{array}{cc} 2(2)-2(3/2) & 2(-1)+2(1) \\ 3(2)-4(3/2) & 3(-1)+4(1) \end{array} \right) =\left( \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right) =\mathbf{I}\text{.} \]
Ejemplo Básico de Regresión Lineal de Inversas de Matrices. Con \[ \mathbf{X}^{\prime }\mathbf{X}=\left( \begin{array}{cc} n & \sum\limits_{i=1}^{n}x_i \\ \sum\limits_{i=1}^{n}x_i & \sum\limits_{i=1}^{n}x_i^2 \end{array} \right), \] tenemos \[ \left( \mathbf{X}^{\prime }\mathbf{X}\right)^{-1}=\frac{1}{n\sum_{i=1}^{n}x_i^2-\left( \sum_{i=1}^{n}x_i\right) ^2}\left( \begin{array}{cc} \sum\limits_{i=1}^{n}x_i^2 & -\sum\limits_{i=1}^{n}x_i \\ -\sum\limits_{i=1}^{n}x_i & n \end{array} \right). \] Para simplificar esta expresión, recuerda que \(\overline{x}=n^{-1} \sum_{i=1}^{n}x_i\). Así, \[\begin{equation} \left( \mathbf{X}^{\prime }\mathbf{X}\right)^{-1}=\frac{1}{ \sum_{i=1}^{n}x_i^2-n\overline{x}^2}\left( \begin{array}{cc} n^{-1}\sum\limits_{i=1}^{n}x_i^2 & -\overline{x} \\ -\overline{x} & 1 \end{array} \right) . \tag{2.9} \end{equation}\]
La Sección 3.1 discutirá la relación \(\mathbf{b}=\left( \mathbf{X}^{\prime}\mathbf{X}\right)^{-1}\mathbf{X}^{\prime}\mathbf{y}\). Para ilustrar el cálculo, tenemos \[\begin{eqnarray*} \mathbf{b} &=&\left( \mathbf{X}^{\prime }\mathbf{X}\right)^{-1}\mathbf{X} ^{\prime }\mathbf{y}=\frac{1}{\sum_{i=1}^{n}x_i^2-n\overline{x}^2} \left( \begin{array}{cc} n^{-1}\sum\limits_{i=1}^{n}x_i^2 & -\overline{x} \\ -\overline{x} & 1 \end{array} \right) \left( \begin{array}{c} \sum\limits_{i=1}^{n}y_i \\ \sum\limits_{i=1}^{n}x_iy_i \end{array} \right) \\ &=&\frac{1}{\sum_{i=1}^{n}x_i^2-n\overline{x}^2}\left( \begin{array}{c} \sum\limits_{i=1}^{n}\left( \overline{y}x_i^2-\overline{x} x_iy_i\right) \\ \sum\limits_{i=1}^{n}x_iy_i-n\overline{x}\overline{y} \end{array} \right) =\left( \begin{array}{c} b_0 \\ b_1 \end{array} \right) . \end{eqnarray*}\] De esta expresión, podemos ver \[ b_1=\frac{\sum\limits_{i=1}^{n}x_iy_i-n\overline{x}\overline{y}}{\sum\limits_{i=1}^{n}x_i^2-n\overline{x}^2} \] y \[ b_0=\frac{\overline{y}\sum\limits_{i=1}^{n}x_i^2-\overline{x} \sum\limits_{i=1}^{n}x_iy_i}{\sum\limits_{i=1}^{n}x_i^2-n\overline{x}^2}=\frac{\overline{y}\left( \sum\limits_{i=1}^{n}x_i^2-n\overline{x} ^2\right) -\overline{x}\left( \sum\limits_{i=1}^{n} x_i y_i - n\overline{x} \overline{y}\right) }{\sum\limits_{i=1}^{n}x_i^2-n\overline{x}^2}=\overline{y}-b_1\overline{x}. \] Estas son las expresiones usuales para la pendiente \(b_1\) (Ejercicio 2.8) y el intercepto \(b_0\).
2.11.4 Matrices Aleatorias
Esperanzas. Consideremos una matriz de variables aleatorias \[ \mathbf{U=}\left( \begin{array}{cccc} u_{11} & u_{12} & \cdots & u_{1c} \\ u_{21} & u_{22} & \cdots & u_{2c} \\ \vdots & \vdots & \ddots & \vdots \\ u_{n1} & u_{n2} & \cdots & u_{nc} \end{array} \right). \] Cuando escribimos la esperanza de una matriz, esto es una forma abreviada para la matriz de esperanzas. Específicamente, supongamos que la función de probabilidad conjunta de \({u_{11}, u_{12}, ..., u_{1c}, ..., u_{n1}, ..., u_{nc}}\) está disponible para definir el operador de esperanza. Entonces definimos \[ \mathrm{E} ~ \mathbf{U} = \left( \begin{array}{cccc} \mathrm{E }u_{11} & \mathrm{E }u_{12} & \cdots & \mathrm{E }u_{1c} \\ \mathrm{E }u_{21} & \mathrm{E }u_{22} & \cdots & \mathrm{E }u_{2c} \\ \vdots & \vdots & \ddots & \vdots \\ \mathrm{E }u_{n1} & \mathrm{E }u_{n2} & \cdots & \mathrm{E }u_{nc} \end{array} \right). \] Como un caso especial importante, consideremos la función de probabilidad conjunta para las variables aleatorias \(y_1, \ldots, y_n\) y el operador de expectativas correspondiente. Entonces \[ \mathrm{E}~ \mathbf{y=} \mathrm{E } \left( \begin{array}{cccc} y_1 \\ \vdots \\ y_n \end{array} \right) = \left( \begin{array}{cccc} \mathrm{E }y_1 \\ \vdots \\ \mathrm{E }y_n \end{array} \right). \] Por la linealidad de las esperanzas, para una matriz no aleatoria A y un vector , tenemos \(\mathrm{E} (\textbf{A y} + \textbf{B}) = \textbf{A} \mathrm{E} \textbf{y + B}\).
Varianzas. También podemos trabajar con los segundos momentos de vectores aleatorios. La varianza de un vector de variables aleatorias se llama matriz de varianza-covarianza. Se define como \[\begin{equation} \mathrm{Var} ~ \mathbf{y} = \mathrm{E} ( (\mathbf{y} - \mathrm{E} \mathbf{y})(\mathbf{y} - \mathrm{E} \mathbf{y})^{\prime} ). \tag{2.10} \end{equation}\] Es decir, podemos expresar \[ \mathrm{Var}~\mathbf{y=} \mathrm{E } \left( \left( \begin{array}{c} y_1 -\mathrm{E } y_1 \\ \vdots \\ y_n -\mathrm{E } y_n \end{array}\right) \left(\begin{array}{ccc} y_1 - \mathrm{E } y_1 & \cdots & y_n - \mathrm{E } y_n \end{array}\right) \right) \] \[ = \left( \begin{array}{cccc} \mathrm{Var}~y_1 & \mathrm{Cov}(y_1, y_2) & \cdots &\mathrm{Cov}(y_1, y_n) \\ \mathrm{Cov}(y_2, y_1) & \mathrm{Var}~y_2 & \cdots & \mathrm{Cov}(y_2, y_n) \\ \vdots & \vdots & \ddots & \vdots\\ \mathrm{Cov}(y_n, y_1) & \mathrm{Cov}(y_n, y_2) & \cdots & \mathrm{Var}~y_n \\ \end{array}\right), \] porque \(\mathrm{E} ( (y_i - \mathrm{E} y_i)(y_j - \mathrm{E} y_j) ) = \mathrm{Cov}(y_i, y_j)\) para \(i \neq j\) y \(\mathrm{Cov}(y_i, y_i) = \mathrm{Var}~y_i\).
En el caso de que \(y_1, \ldots, y_n\) sean mutuamente no correlacionados, tenemos que \(\mathrm{Cov}(y_i, y_j)=0\) para \(i \neq j\) y así \[ \mathrm{Var}~\mathbf{y=} \left( \begin{array}{cccc} \mathrm{Var}~y_1 & 0 & \cdots & 0 \\ 0 & \mathrm{Var}~y_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots\\ 0 & 0 & \cdots & \mathrm{Var}~y_n \\ \end{array}\right). \] Además, si las varianzas son idénticas, de modo que \(\mathrm{Var}~y_i=\sigma ^2\), entonces podemos escribir \(\mathrm{Var} ~\mathbf{y} = \sigma ^2 \mathbf{I}\), donde I es la matriz identidad \(n \times n\). Por ejemplo, si \(y_1, \ldots, y_n\) son i.i.d., entonces \(\mathrm{Var} ~\mathbf{y} = \sigma ^2 \mathbf{I}\).
A partir de la ecuación (2.10), se puede demostrar que \[\begin{equation} \mathrm{Var}\left( \mathbf{Ay +B} \right) = \mathrm{Var}\left( \mathbf{Ay} \right) = \mathbf{A} \left( \mathrm{Var}~\mathbf{y} \right) \mathbf{A}^{\prime}. \tag{2.11} \end{equation}\] Por ejemplo, si \(\mathbf{A} = (a_1, a_2, \ldots,a_n)= \mathbf{a}^{\prime}\) y B = 0, entonces la ecuación (2.11) se reduce a \[ \mathrm{Var}\left( \sum_{i=1}^n a_i y_i \right) = \mathrm{Var} \left( \mathbf{a^{\prime} y} \right) = \mathbf{a^{\prime}} \left( \mathrm{Var} ~\mathbf{y} \right) \mathbf{a} = (a_1, a_2, \ldots,a_n) \left( \mathrm{Var} ~\mathbf{y} \right) \left(\begin{array}{c} a_1 \\ \vdots \\ a_n \end{array}\right) \] \[ = \sum_{i=1}^n a_i^2 \mathrm{Var} ~y_i ~+~2 \sum_{i=2}^n \sum_{j=1}^{i-1} a_i a_j \mathrm{Cov}(y_i, y_j). \]
Definición - Distribución Normal Multivariante. Un vector de variables aleatorias \(\mathbf{y} = \left(y_1, \ldots, y_n \right)^{\prime}\) se dice que es normal multivariante si todas las combinaciones lineales de la forma \(\sum_{i=1}^n a_i y_i\) están distribuidas normalmente. En este caso, escribimos \(\mathbf{y} \sim N (\mathbf{\boldsymbol \mu}, \mathbf{\Sigma} )\), donde \(\mathbf{\boldsymbol \mu} = \mathrm{E}~ \mathbf{y}\) es el valor esperado de y y \(\mathbf{\Sigma}= \mathrm{Var}~\mathbf{y}\) es la matriz de varianza-covarianza de y. Según la definición, tenemos que \(\mathbf{y}\sim N (\mathbf{\boldsymbol \mu}, \mathbf{\Sigma} )\) implica que \(\mathbf{a^{\prime}y}\sim N (\mathbf{a^{\prime} \boldsymbol \mu}, \mathbf{a^{\prime}\Sigma a})\). Así, si \(y_i\) son i.i.d., entonces \(\sum_{i=1}^n a_i y_i\) está distribuido normalmente con media \(\mu \sum_{i=1}^n a_i\) y varianza \(\sigma ^2 \sum_{i=1}^n a_i ^2\).